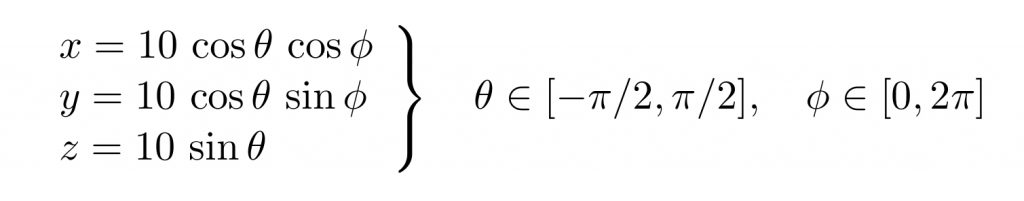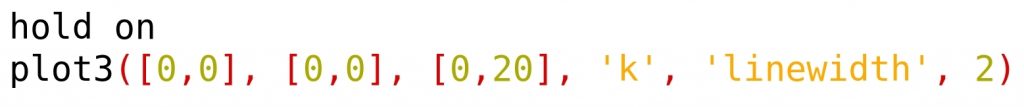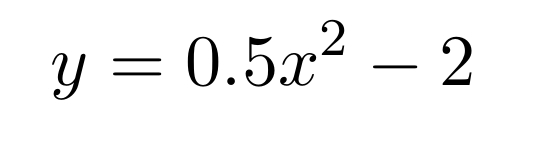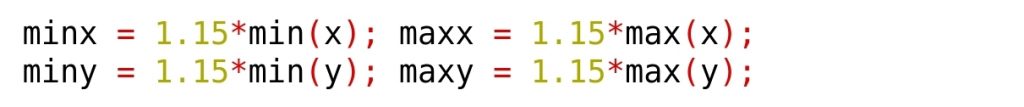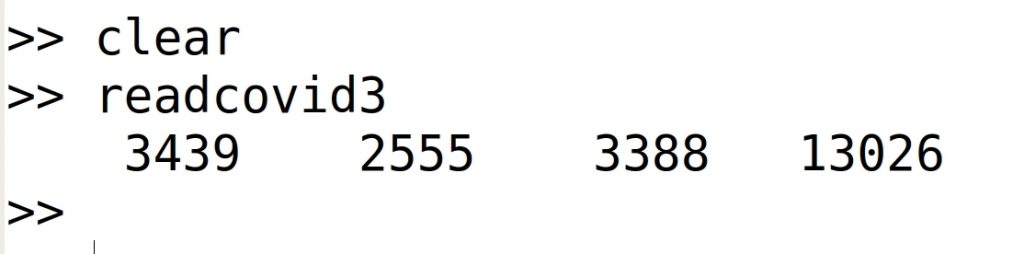Los lenguajes de programación más solicitados en 2021
La programación de ordenadores sigue siendo un campo con interesantes salidas laborales. Esto es especialmente cierto en el campo de la Ingeniería Civil, por tratarse de un sector consumidor de muchos recursos informáticos. Actualmente existen más de 700 lenguajes de programación activos. Este artículo hablará sobre los lenguajes más demandados en el año 2021, según distintas fuentes.
Con la excepción de los lenguajes dedicados a la programación de bases de datos, la mayoría de los índices miden la importancia de los lenguajes en su uso general, no dentro de un campo específico. Es por ello, que los lenguajes cuya utilización se da principalmente dentro de un campo concreto, salen penalizados, y su posición en los índices generales no muestra realmente su posición si se considerara solo su prevalencia en dicho campo.
Es el caso de MATLAB-Octave, cuyo uso está restringido al ámbito científico. Uno de los índices más prestigiosos es el índice TIOBE, basado en las búsquedas en internet referentes a los diferentes lenguajes. El índice TIOBE del mes de octubre de 2021 indica que MATLAB ocupa la posición 13 entre los lenguajes más utilizados. Esto supone un incremento de uso respecto de octubre de 2020, cuando ocupaba la posición 15.
En todos los índices, las primeras posiciones están copadas por Python, Java y las diferentes variantes del C: C, C++ y C#. Son sin duda los lenguajes más utilizados para programación general. Java, que venía siendo el más utilizado durante muchos años, ha cedido la primera posición en favor de Python y C. Cualquiera de ellos es una buena opción para profundizar en la programación. Si nos limitamos al ámbito científico, tal vez Python ofrece, a día de hoy, una combinación de recursos y facilidad de uso que lo convierten en la opción más atractiva.
Es significativa la evolución del lenguaje Fortran. Hace muchos años era el lenguaje científico por excelencia. De hecho, era el lenguaje que se estudiaba en la Escuela de Caminos allá por los años 80 y 90 del siglo pasado. Más tarde, Fortran perdió importancia y pasó a ser un lenguaje muy minoritario. Las mejoras aportadas en las útimas versiones, junto con su rapidez de ejecución y su enfoque científico han hecho que vuelva a ser un lenguaje muy utilizado. En el citado índice TIOBE de octubre de 2021, ocupa la posición 18 entre los lenguajes más utilizados, ascendiendo a esta posición desde la posición 37 que ocupaba el año pasado.
En el último artículo que dediqué a los lenguajes más utilizados, hablaba de Rust y Go. Los sigo considerando dos lenguajes muy interesantes y con mucho futuro. En el índice TIOBE de octubre 2021, Go ocupa la posición 12 y Rust la 26. Son lenguajes fundamentalmente dedicados a la programación de sistemas. Como opción laboral, son de los que mejores sueldos ofrecen a los programadores. Les seguiremos la pista para ver su evolución. Seguro que seguirán dando que hablar en el futuro.
Es muy interesante la encuesta anual de Stack Overflow, que ofrece respuestas a numerosas preguntas acerca del perfil de los lenguajes de programación y de los propios programadores.
A continuación se ofrece una lista de enlaces a algunos índices y a artículos comentando los distintos índices:
La manera en la que los computadores tratan los números reales da lugar a algunas paradojas que es conveniente tener en cuenta para no cometer errores. Los ordenadores no operan con números reales, sino con unos números denominados de coma flotante. Por
ejemplo en Octave y Matlab se utiliza el formato numérico denominado double para representar los números reales,. El formato double permite operar números con hasta 15 decimales significativos. Esto hace que, en el caso de
los números reales que tengan un número de decimales mayor que 15, el valor utilizado por el formato double sea una aproximación al número truncada a 15 decimales.
Números reales con más de 15 decimales significativos hay infinitos, en particular todos los números irracionales y los números racionales como el 1/3 o el 1/7, que tienen un número infinito de decimales. En todas las operaciones que realicemos con el
ordenador en las que intervenga alguno de estos números, los resultados serán aproximados, no exactos.
Históricamente ha habido algunas catástrofes producidas por no considerar adecuadamente estas aproximaciones que realizan los ordenadores. Así sucedió en el caso de la explosión del cohete Arianne 5 poco después del despegue o en el fallo de una
batería de misiles Patriot que no pudo interceptar un misil SCUD disparado por las tropas iraquíes durante la guerra del Golfo [1 y 2].
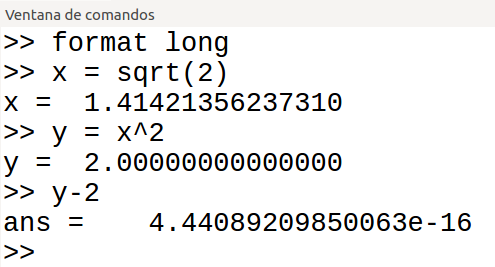
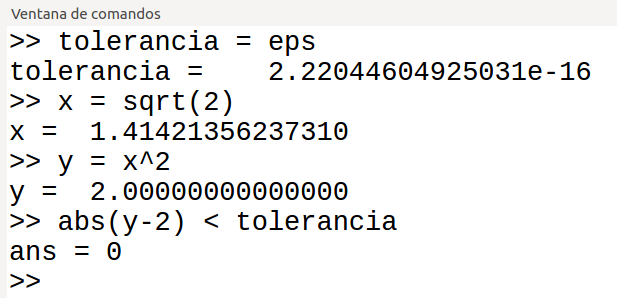
Una situación concreta en la que hay que tener cuidado y que se da habitualmente en los problemas que se hacen en el curso es la de comprobar si el resultado de una operación entre números reales es igual a cero. El problema de comprobar si dos números reales son iguales es equivalente al anterior, pues comprobar si x es igual a y es equivalente a comprobar si (x-y) es igual a cero. En general es incorrecto hacer la comparación ‘if x==0′ o la comparación ‘if x==y’.Se puede comprobar con el siguiente ejemplo realizado en la consola de Octave:
Operando con números reales, la comprobación (y-2)==0 debería arrojar un resultado verdadero y, en cambio, arroja un resultado falso. La raíz cuadrada de 2 es un número irracional y, por tanto, el valor utilizado por el ordenador es una aproximación. Si se utiliza el formato largo para mostrar los números en pantalla se podrá comprender lo que está pasando:
Se puede ver que la diferencia(y-2) es un valor muy pequeño, pero no exactamente cero.
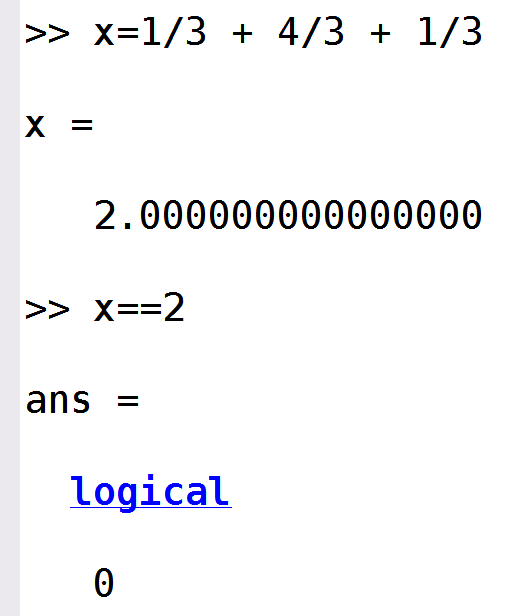
Hay muchos ejemplos, algunos con operaciones aparentemente sencillas. El lector puede comprobar que al sumar 1/3 + 4/3 + 1/3 no se obtiene exactamente 2, como se muestra en la siguiente figura:
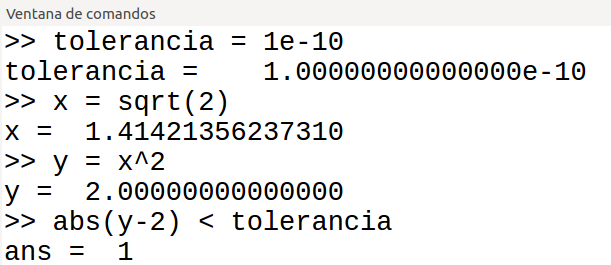
Para actuar de manera controlada en estas situaciones se puede utilizar un valor umbral, que se suele denominar tolerancia, para comparar si determinada cantidad es cero. Lo que se hace es comprobar si la cantidad es menor en valor absoluto que
el valor umbral utilizado. Si así sucede, se considera que dicha cantidad es cero. Por ejemplo, si se toma como valor umbral de la tolerancia 1e-10, se podría hacer la siguiente
comparación:
El valor umbral utilizado para la tolerancia dependerá del problema concreto. Por ejemplo, si se está trabajando en un problema de altitudes del terreno medidas en metros para una obra pública, puede ser suficiente considerar que un milímetro es la cantidad
más pequeña a considerar, con lo que la tolerancia en ese caso podrá ser 1e-3 . En otros casos será necesario utilizar valores menores o mayores. Cuando se trate en el curso la resolución
de ecuaciones no lineales se podrán ver algunos ejemplos.
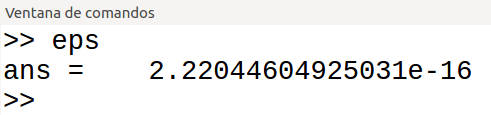
Octave y Matlab proporcionan una constante denominada eps , que corresponde a la precisión de la máquina, y que depende del ordenador utilizado. El épsilon de la máquina es el número decimal más pequeño que, sumado a 1, la computadora nos arroja un valor
diferente de 1, es decir, que no es redondeado. En el computador que hemos probado, el valor de eps es:
Este valor no nos sirve para utilizarlo como tolerancia, hay que utilizar valores de la tolerancia seleccionados adecuadamente y que se adapten bien al problema concreto. Se puede comprobar que, en el ejemplo de la raíz de 2, el valor de la constante
eps sería menor que el error que se comete y, por tanto, la comprobación seguiría arrojando valores erróneos:
En este artículo se va a utilizar la programación del clásico juego de adivinación de un número, para repasar conceptos básicos de programación en el lenguaje m de MATLAB y Octave.
El programa seleccionará un número entero aleatorio entre 0 y 100 y pedirá al usuario que lo adivine. En cada intento, el programa informará al usuario si el número que ha tecleado es demasiado alto o demasiado bajo respecto al elegido por el ordenador. Cuando el usuario acierte el número, el ordenador le informará de ello.
El programa es relativamente sencillo, pero permite afianzar los conocimientos acerca de:
Generación de números aleatorios
Entrada de datos por teclado
Validación de las entradas de datos
Asignación de variables
Bucles while
Sentencias break y continue
Bifurcaciones if
Salidas simples por pantalla
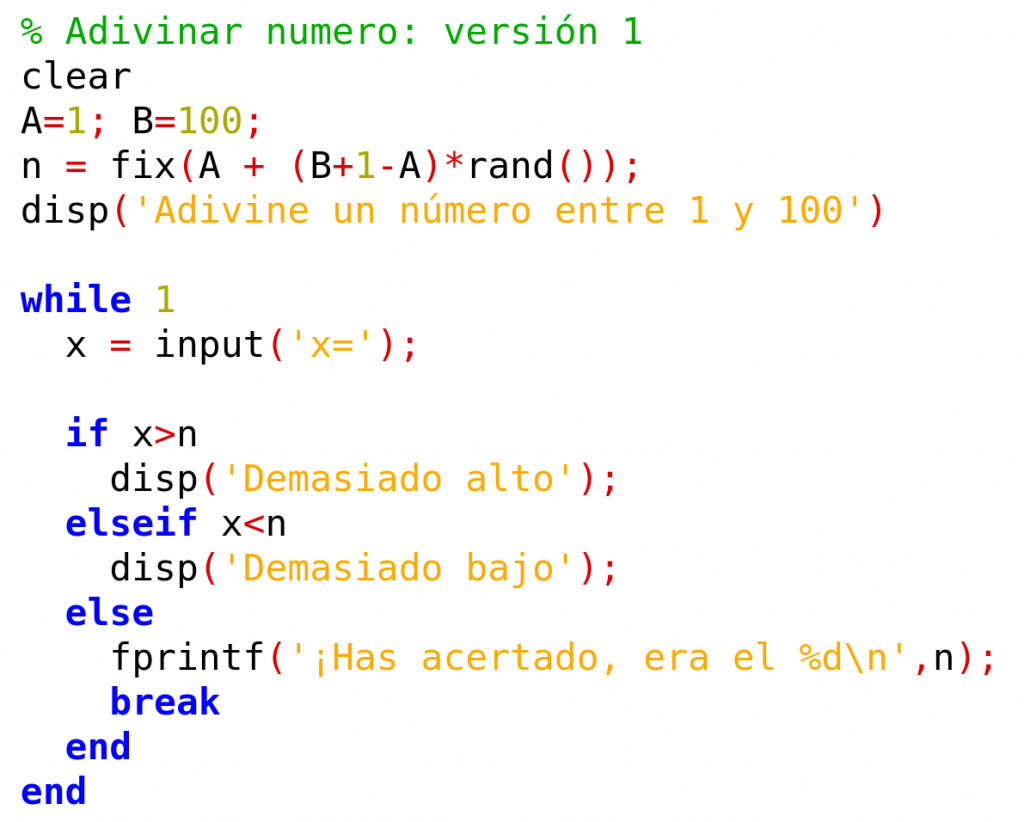
A continuación se muestra el listado de la primera versión del programa. Se analizará cada apartado y, posteriormente, se indicará cómo mejorar algunos aspectos del programa:
En esta versión del programa, en primer lugar se hace un clear, para borrar la memoria, y a continuación se genera un número entero aleatorio en el intervalo cerrado [1, 100]. La figura siguiente resume las dos fórmulas usuales para generar números aleatorios: la primera genera un número decimal aleatorio en el intervalo abierto (A, B). La segunda fórmula genera un número entero aleatorio en el intervalo cerrado [A, B]:
mde
El programa sigue con un bucle while de los denominados infinitos: al hacer while 1, el bucle se ejecutará de manera indefinida hasta que encuentre una sentencia break, que fuerce la salida del bucle.
Dentro del bucle, en cada iteración, el programa solicita un número al usuario mediante una sentencia input(), y se lo asigna a la variable x. A continuación se utiliza una bifurcación del tipo if…elseif…else…end para determinar la respuesta del programa al usuario. Si el número tecleado por el usuario no es el correcto, se le informa si es demasiado alto o demasiado bajo. Si el usuario acierta, se le informa de ello, y se sale del bucle con la sentencia break, alcanzando el final del programa.
El lector debe observar que, para informar de número alto o bajo, es suficiente utilizar una sentencia disp(), mostrando en pantalla una cadena de caracteres. En cambio, para informar del acierto, como se quiere utilizar una cadena de caracteres junto con el valor de la variable n, se utiliza la sentencia fprintf().
El programa funciona, como puede comprobar el lector. Pero, ¿qué pasa si el usuario no teclea un número cuando se le solicita, y se limita a pulsar la tecla INTRO? El lector puede comprobar que, en ese caso, el programa da el resultado como correcto e informa de que se ha acertado, mostrando además el número correcto.
¿Por qué pasa esto? Si se analiza en detalle la sentencia if, se puede comprobar que si el número no es mayor ni es menor que el elegido por el ordenador, la respuesta se da por buena. En este caso, al no teclear ningún número, la variable x está vacía, y no es mayor ni menor que el resultado, con lo que se sale del bucle por la rama else.
Este tipo de circunstancias es habitual en los programas, por lo que siempre que hay una entrada de datos a un programa es muy importante hacer la comprobación de que la entrada de datos ha sido correcta.
Para comprobar si el usuario ha dejado la respuesta vacía, se puede utilizar la función isempty(), que devuelve un 1 (verdadero), si la variable está vacía. Con esto, se podría forzar al programa a repetir el input(), si la variable respuesta está vacía:
Si el usuario deja la variable x vacía, la sentencia continue fuerza que se vuelva al inicio del bucle while, iniciando otra iteración, y volviendo a ejecutar la sentencia input(). El lector puede corregir el programa y comprobar que se resuelve el problema de respuesta vacía.
La respuesta vacía no es la única respuesta incorrecta. El usuario, por error o por malicia, podría teclear un número que no fuera entero, por ejemplo un número decimal. Para detectar esta circunstancia se puede utilizar la función fix(), que devuelve la parte entera de un número decimal. Si la expresión fix(x) no es igual a x, entonces el valor tecleado no es entero. En ese caso, se puede hacer como antes, y forzar el reinicio del bucle. El código corregido quedaría así:
Se podría forzar al usuario a teclear un número no menor que 1 ni mayor que 100, aunque en este caso no se ha considerado que sea importante.
¿Y qué sucede si el usuario teclea una cadena de caracteres, en vez de teclear un número? En ese caso, Octave o MATLAB interpretarán la cadena de caracteres como el nombre de una variable o como una instrucción válida. Si el nombre de variable es correcto, por ejemplo, si se responde ‘PI‘, el programa interpretará la respuesta como un número decimal y actuará en consecuencia, volviendo a pedir el valor x. También se podría teclear una operación válida, por ejemplo, 20+10. En ese caso, se ejecutará la operación y se asignará el resultado a la variable x. Si se teclea una cadena que no se corresponda con un nombre de variable existente, o una instrucción válida, el programa fallará.
Una manera de gestionar esto es leer el dato del usuario como si fuera una cadena de caracteres, y luego convertirlo en número, de la siguiente forma:
Observe el lector que se añade un segundo parámetro ‘s‘ al input(), para forzar la lectura como cadena de caracteres, y luego se convierte dicha cadena en numero mediante la función str2num(). De esta forma, si la cadena no da lugar a un número, la variable x quedará vacía y se volverá a pedir el valor.
El problema puede ser si se teclea un comando válido. De hecho, en las entradas de datos, suelen estar algunos de los agujeros de seguridad más importantes que suelen aprovechar los hackers. Como muestra,el lector puede probar a teclear como respuesta clear, o surf(peaks), o, en plan hacker, pruebe a teclear exit(). Estas tres respuestas son relativamente inocuas, pero si nuestro programa se llama, por ejemplo, adivina1.m y respondemos con delete(‘adivina1.m’), el programa se borrará del directorio y perderemos todo el trabajo. Si el lector quiere probarlo, es conveniente hacer primero una copia del programa con otro nombre, para no perder el trabajo. Se podrían hacer cosas mucho más graves que simplemente borrar un fichero. Estas respuestas en forma de instrucciones a ejecutar por el software se conocen como ‘code injection‘, y es un bug realmente peligroso. El lector puede consultar el artículo al respecto de la Wikipedia:
La función str2num() evalua la expresión entrecomillada, antes de asignarla a la variable x. Si la expresión tecleada es maliciosa, se produce el problema. Se puede utilizar la función str2double(), que no evalua la expresión tecleada, y es por tanto segura frente al problema del code injection, aunque también nos impide teclear expresiones válidas. El código sería el siguiente:
Si el lector ha llegado hasta aquí, habrá podido comprobar que la codificación de programas aparentemente simples admite muchos matices. También será consciente de lo importante que es el checking de las entradas de datos en todos los programas.
Dada la fecha en la que va a aparecer publicado este artículo, no puedo por menos que desear feliz navidad a todos los lectores.
Nota: Estos problemas de code injection en sentencias de asignación directa o con str2num(), están parcialmente filtrados en MATLAB. No así en Octave. En cualquier caso, se puede probar a responder en MATLAB system(‘del adivina1.m’), que en Windows borrará el fichero en cuestión.A través de la instrucción system() que ejecuta directamente órdenes del sistema operativo se pueden introducir todo tipo de códigos maliciosos.
En un artículo anterior se ha explicado cómo dibujar los ejes coordenados en 2 dimensiones. En este artículo se va a explicar cómo hacerlo en gráficos de 3 dimensiones.
El procedimiento es el mismo, dibujar una recta a partir de dos puntos, pero al estar trabajando en 3 dimensiones, habrá que utilizar la función plot3() y los dos puntos que se utilizarán tendrán 3 coordenadas cada uno: la coordenada X, la coordenada Y y la coordenada Z.
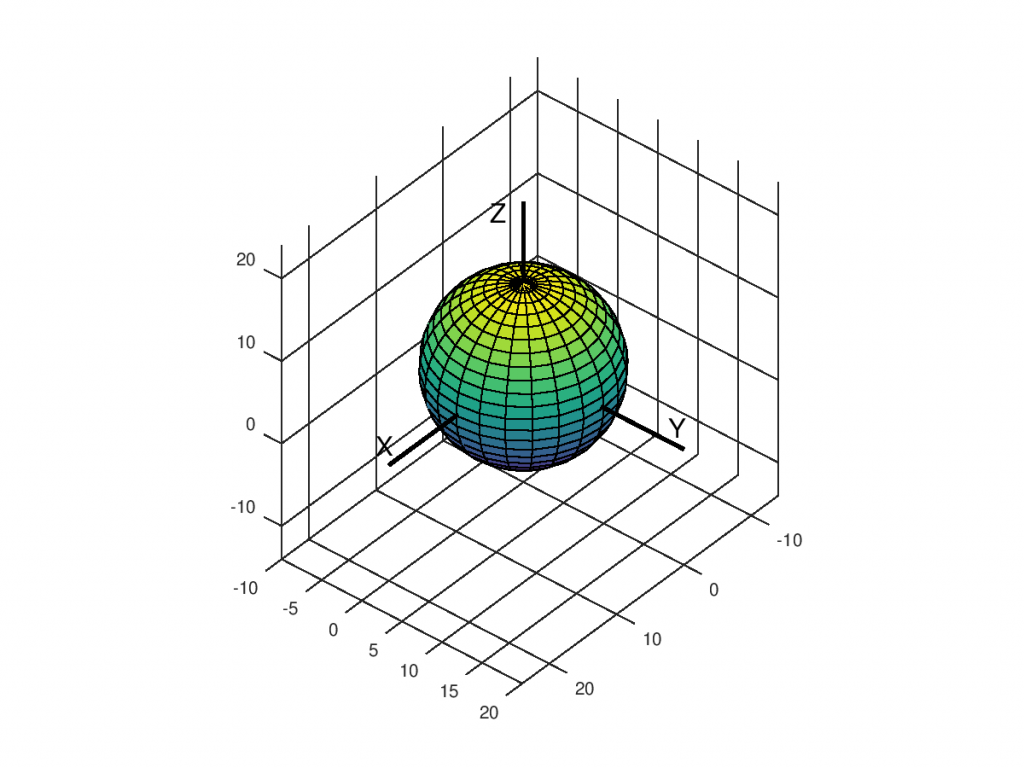
Para poder ilustrar esta técnica, se va a partir de un gráfico de ejemplo consistente en el dibujo de una esfera de radio 10, definida por las siguientes ecuaciones paramétricas:
El gráfico de la esfera se realizará por el procedimiento habitual para superficies en ecuaciones paramétricas:
Ahora se va a dibujar el eje Z. Para ello, hay que elegir los dos puntos extremos de la recta que queremos dibujar. Como la esfera tiene radio 10, se pueden elegir los puntos (0, 0, 0) y (0, 0, 20). La función a utilizar es plot3(), a la que hay que pasarle tres vectores con las coordenas X,Y,Z de los dos puntos. Además, se le dará estilo a la línea, en este caso se ha elegido color negro y 2 pixels de grueso. Antes de ejecutar el plot3, habrá que ejecutar el comando hold on, para que dibuje en el mismo gráfico:
Con un razonamiento similar, se pueden dibujar los ejes X e Y:
Los últimos refinamientos de la gráfica podrían ser añadir unas etiquetas a los ejes, establecer el punto de vista en azimut 130 y elevación 38, para ver la gráfica desde el primer cuadrante, hacer un axis equal, y cerrar el puerto gráfico con hold off:
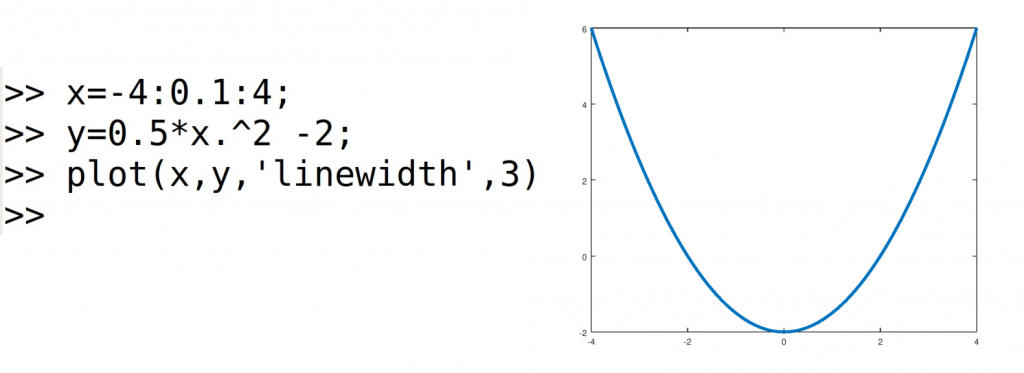
Como sabemos, al dibujar gráficos con el comando plot(x,y), la gráfica queda dibujada ajustando los ejes a la ventana, entre los valores máximos y mínimos de los vectores x e y. La gráfica muestra unos ejes graduados en la parte inferior e izquierda de la gráfica, que no tienen por qué estar en las posiciones y=0, x=0. Si añadimos etiquetas a los ejes con los comandos xlabel() e ylabel(), dichas etiquetas aparecerán en los ejes de la gráfica, no en los ejes coordenados X e Y.
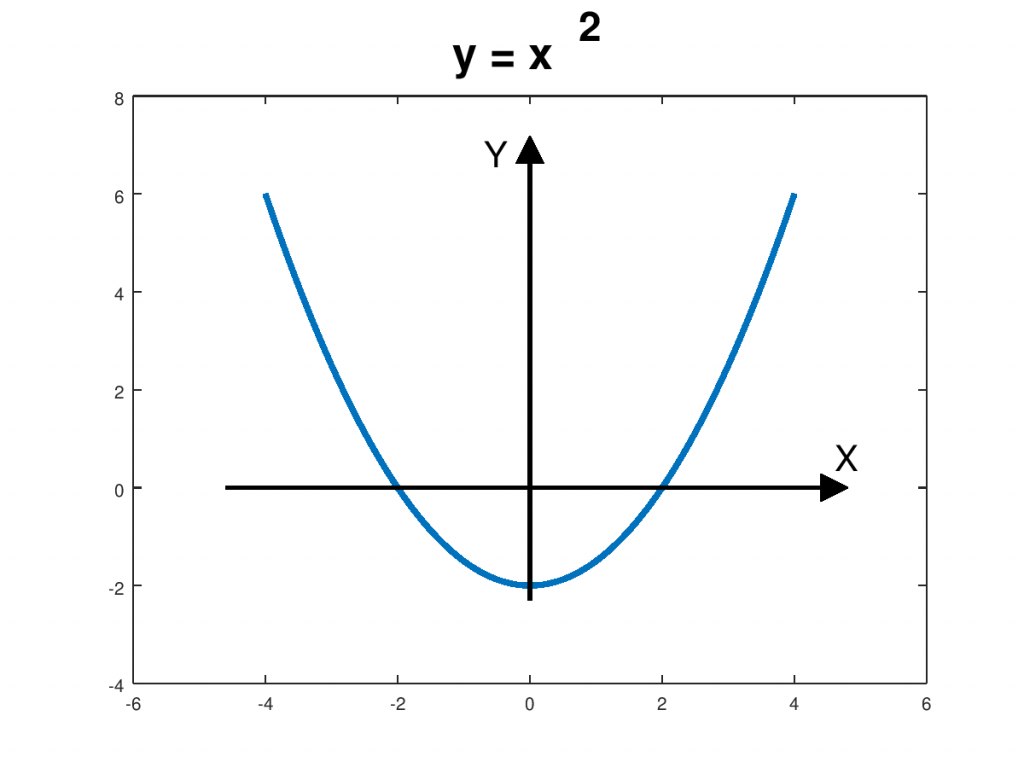
Vamos a explicar en este artículo cómo dibujar los ejes coordenados en sus posiciones. Para ello vamos a utilizar como ejemplo el gráfico de la siguiente parábola:
para valores de x en el intervalo [-4, 4]. El gráfico anterior se puede hacer de la siguiente manera:
El eje X es la recta cuya expresión es y=0. El eje Y es la recta x=0. Habrá que dibujar dichas rectas entre los valores mínimo y máximo de la gráfica donde queramos dibujarlos. Podemos hacerlo de la siguiente manera:
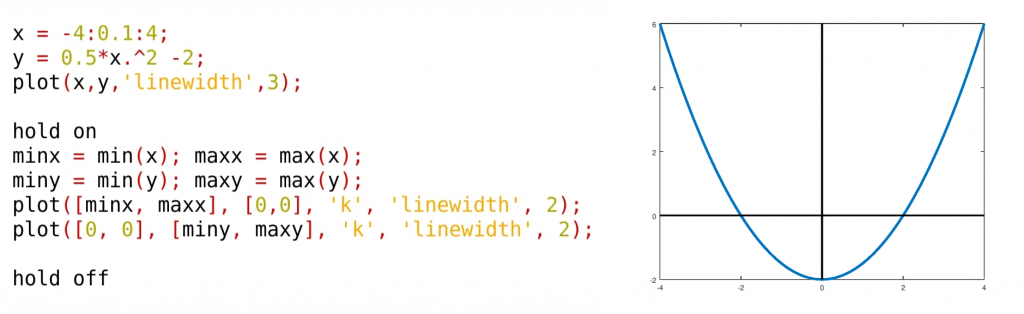
Hasta aquí es lo que pediríamos en los exámenes del curso de la escuela de Caminos. Vamos a añadir algunos refinamientos para mejorar los ejes.
En primer lugar, conviene hacer los ejes un poco mayores que los valores máximos. Por ejemplo podemos hacerlos un 15% más grandes:
Aquí, si los valores mínimos fueran positivos, o los valores máximos fueran negativos, habría que actuar de manera diferente.
Además, podemos añadir unos marcadores de flecha, para indicar el sentido de crecimiento de los ejes:
Por último, podríamos añadir unas etiquetas con el nombre de los ejes, y un título al gráfico:
Un problema habitual al leer datos de un fichero de texto es que cada linea de datos contenga datos de distinto tipo: cadenas de caracteres y datos numéricos. La lectura y extracción de dichos datos a variables es un poco más complicada que los casos en los que toda la información es del mismo tipo. Se va a resolver un ejemplo que permita aprender las técnicas que son necesarias en estos casos.
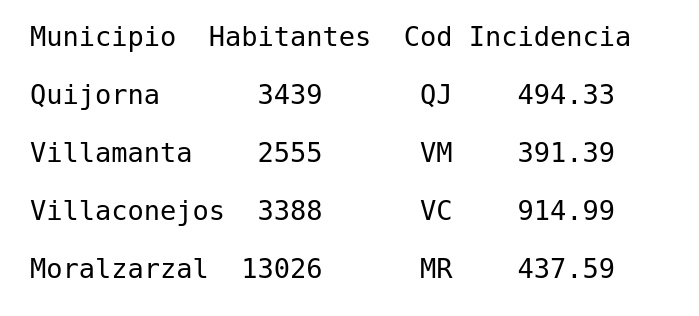
Para la resolución se va a utilizar el fichero datos.txt que, tras una línea de cabecera, contiene en cada línea los datos de incidencia COVID de un municipio de la provincia de Madrid a fecha 24 de noviembre de 2020. El fichero es el siguiente:
El alumno deberá crear este fichero con el editor, copiando los datos que contiene, y grabarlo con el nombre ‘datos.txt’, en el mismo directorio de trabajo donde se va a crear el programa .m de lectura del mismo.
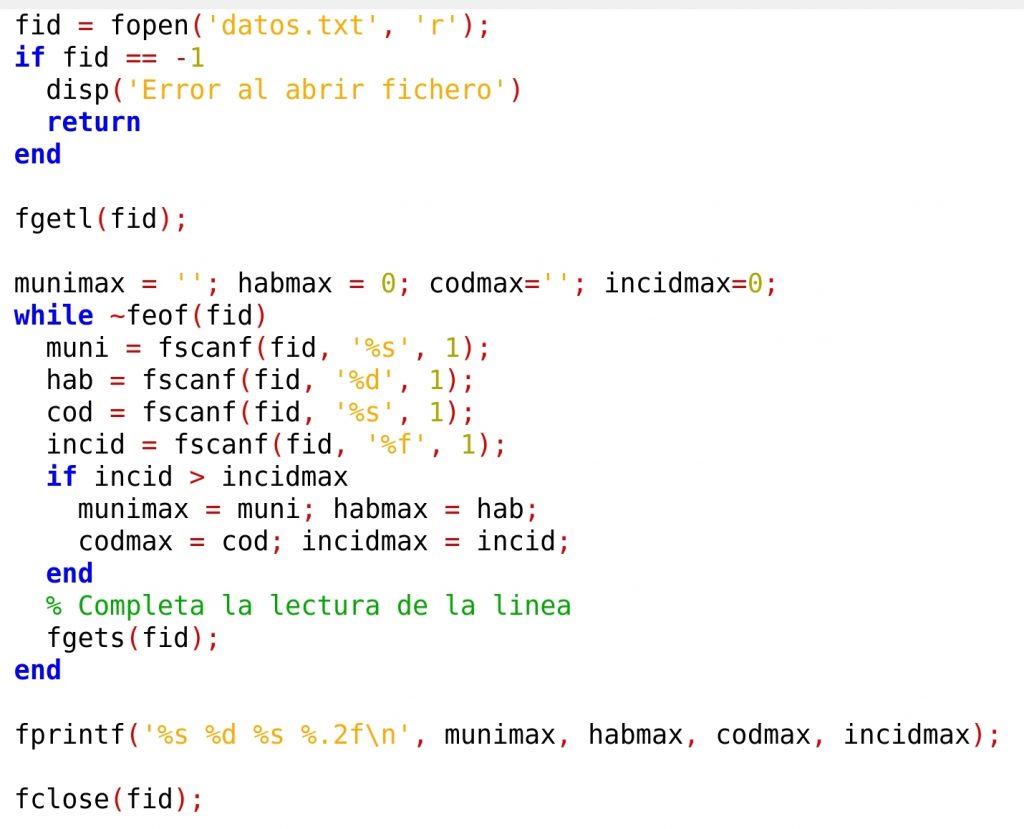
La lectura del fichero debe comenzar con la apertura del mismo en modo lectura, ‘read’. El listado siguiente realiza la apertura del fichero y la comprobación de que el fichero se ha abierto correctamente. Al final del programa se pone la orden fclose(fid), para cerrar el fichero. El alumno deberá copiar estas instrucciones en el editor y guardarlo en el disco, en el mismo directorio en el que ha guardado el fichero ‘datos.txt’. El fichero del programa lo podemos llamar ‘readcovid.m‘, por ejemplo:
Conviene probar esta parte del programa. El programa se ejecuta desde la ventana de comandos, tecleando el nombre del programa ‘readcovid’. Antes de ejecutar el programa haga un ‘clear’, para borrar las variables del espacio de trabajo. Si al ejecutarlo no aparece nada en pantalla, es que ha funcionado bien. En el espacio de trabajo veremos la variable ‘fid’ con el identificador de fichero que le haya sido asignado, y la variable ‘ans’ con el valor cero, correspondiente a la ejecución correcta de la instrucción ‘fclose()’. Si en pantalla se muestra el mensaje ‘Error al abrir fichero’, es que el programa no encuentra el fichero de datos, quizás por poner mal el nombre en la instrucción ‘fopen’, o quizás porque el fichero de datos no está en el mismo directorio que el fichero del programa.
Una vez que se comprueba que funciona correctamente, vamos a proceder a completar las instrucciones de lectura antes de la orden ‘fclose(fid)’. El problema que vamos a resolver es leer los datos del fichero, determinar el municipio con mayor incidencia de COVID, y mostrar en pantalla sus datos: Municipio, Habitantes, Cod e Incidencia.
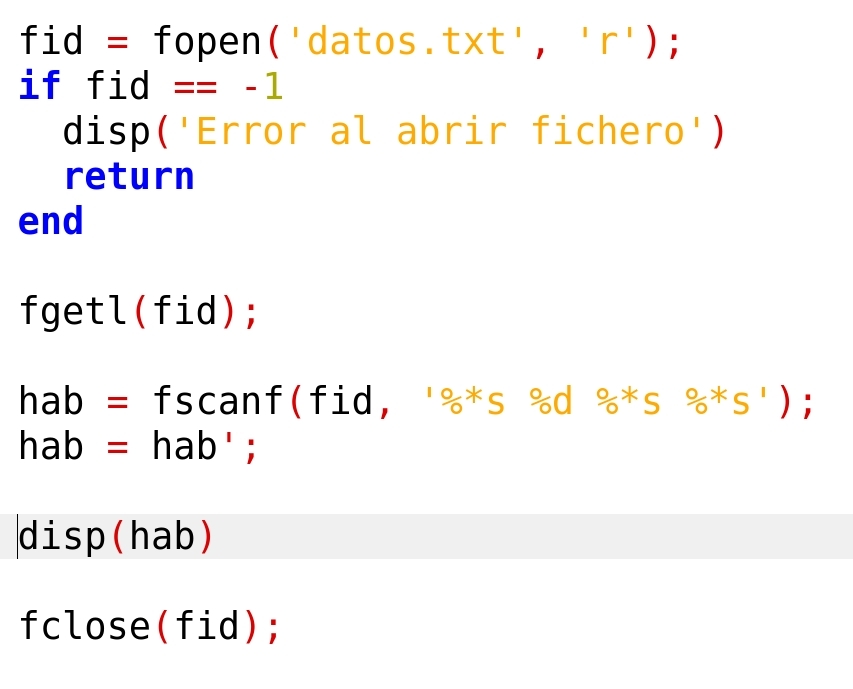
Vamos a empezar leyendo solo una línea, para entender el funcionamiento. La siguiente versión del programa lee los datos del primer municipio y los guarda en variables.
Lo primero que hace el programa es saltarse la línea de las cabeceras, mediante ‘fgetl()’. A continuación, lee los datos de una línea, de uno en uno, y los guarda en variables. Por último, hace un ‘fgets()’, para completar la lectura de la línea, leyendo el caracter fin de línea. De esta manera, el ‘cabezal de lectura’ quedará posicionado al principio de la siguiente línea de datos, preparado para seguir leyendo. El alumno debe observar que, para leer cada dato, la instrucción ‘fscanf’ utiliza el formato adecuado e indica que solo lee 1 dato. Tras ejecutar el programa y si todo va bien, la ventana del espacio de trabajo deberá mostrar las variables con los valores correctos (conviene hacer un ‘clear’, antes de cada ejecución del programa, para vaciar la memoria y el espacio de trabajo. Si se hace así, el espacio de trabajo mostrará, además de las variables del municipio, la variable ‘ans’ con el valor 0, correspondiente al resultado correcto de la orden ‘fclose’).
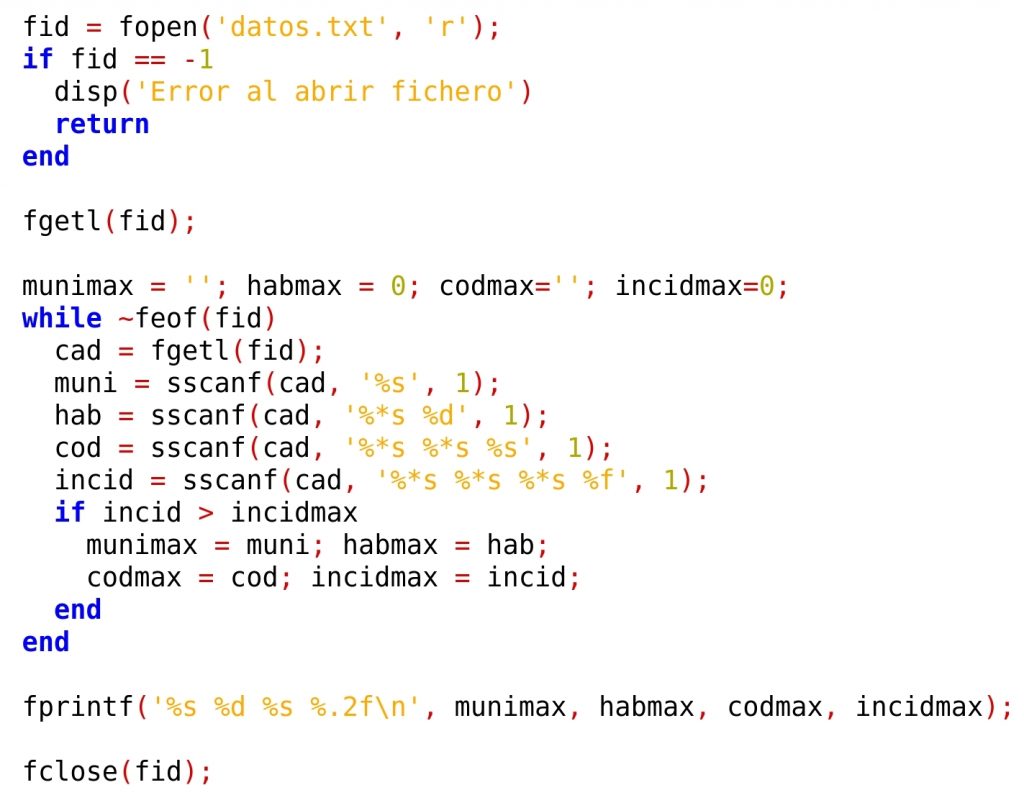
Una vez comprobado que podemos leer una línea de manera correcta, podemos proceder a leer todo el fichero, mediante un bucle ‘while’ con la condición ‘~feof(fid)’, o sea, ‘mientras no estemos en el FILE END OF FILE’. Para localizar el municipio con mayor incidencia de COVID en los últimos catorce días, aplicaremos el algoritmo del máximo. Inicializamos a cero unas variables donde guardar los datos máximos: munimax, habmax, codmax y incidmax. Cada vez que encontremos un municipio con incidencia máxima, guardaremos sus datos en las variables. Al final del bucle, tendremos guardados en las variables los datos del municipio con mayor incidencia, y los mostraremos en pantalla:
Al ejecutar el programa, y si todo va bien, deberíamos obtener una salida como la siguiente:
Otra técnica para leer este tipo de ficheros consiste en utilizar la instrucción ‘sscanf()’, que permite decodificar una cadena de texto. La instrucción ‘sscanf (String Scan Formatted)‘ funciona igual que la instrucción ‘fscanf’ (File Scan Formatted), con la salvedad de que ‘sscanf’ lee datos desde una cadena de texto, mientras que ‘fscanf’ lee datos desde un fichero.
La técnica es similar, pero se leen líneas completas del fichero a una cadena de texto con ‘fgetl()’, y luego se decodifica la cadena con ‘sscanf()’. Para explicar el funcionamiento de la instrucción ‘sscanf’, vamos a jugar un poco en la ventana de comandos, antes de hacer el programa que lee el fichero COVID.
Ejecute en la ventana de comandos las siguientes instrucciones:
Creamos primero una cadena de texto en la variable cad, y luego utilizamos la instrucción ‘sscanf’ para extraer el primer valor, como cadena de texto, a la variable ‘muni’. Observese que el primer parámetro que pasamos a la instrucción ‘sscanf’ es la cadena que queremos decodificar, luego el formato de la decodificación y, por último, el número de elementos que queremos extraer con ese formato.
Para extraer el segundo valor de la cadena, hay que saltarse el primer valor y leer el segundo. Esto se consigue poniendo un formato ‘%*s’. El asterisco que ponemos entre el símbolo % y la letra s hace que dicho formato lo lea, pero no lo guarde. El valor que guarda en la variable es el del segundo formato. Seguimos diciendo a ‘sscanf’ que lea un solo valor, el valor que se salta no cuenta:
Para leer el tercer valor, hay que saltarse los dos primeros. Aquí hay que tener cuidado: aunque el segundo valor sea un entero, para saltarlo hay que utilizar ‘%*s’, como si fuera una cadena de texto. Si lo intentáramos saltar con un formato ‘%*d’, el tercer valor no lo leería como cadena, sino como un array de doubles. Por tanto, para saltarse valores, siempre hay que hacerlo con ‘%*s’, como si fueran cadenas, aunque sean números lo que queremos saltar:
La lectura del cuarto dato no presenta mayores dificultades:
Una vez entendido cómo funciona la instrucción ‘sscanf’, reproducimos a continuación el listado del mismo programa que hicimos antes, para extraer los datos del municipio con mayor incidencia:
La salida de este programa debería ser idéntica a la de la otra versión.
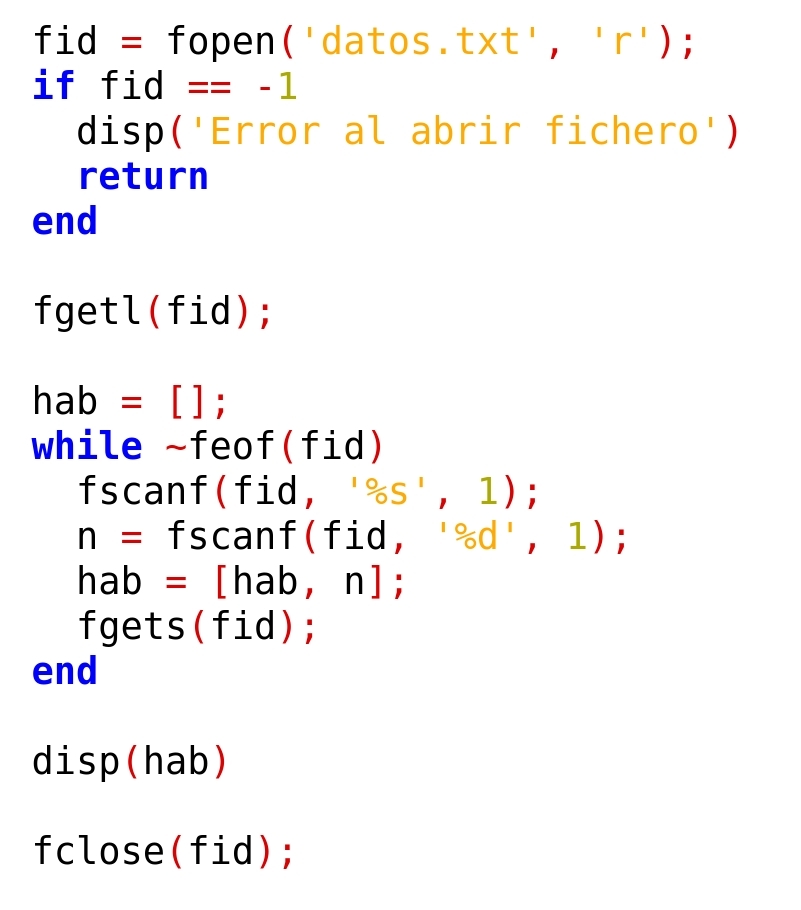
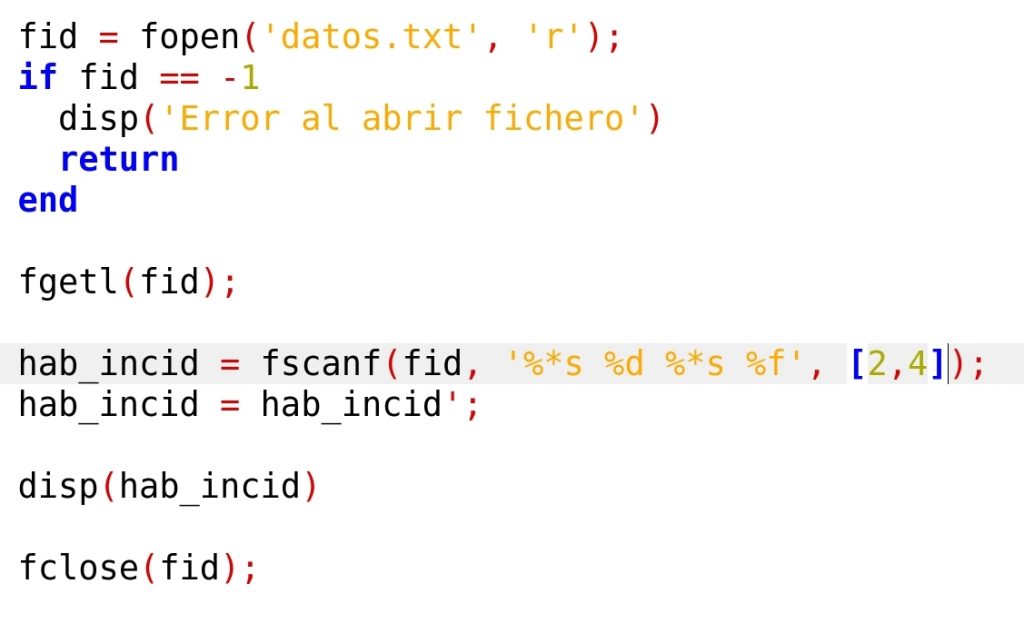
Vamos a ver, por último, cómo resolver si no se quieren guardar todos los datos de cada línea, sino solo alguno de ellos, descartando los demás. Por ejemplo, vamos a leer el número de habitantes de cada municipio a un vector, pero descartando todo el resto de información. La técnica consiste en leer en cada línea hasta el dato que buscamos, y descartar el resto de la línea haciendo ‘fgets()’:
La salida de este programa debería ser la siguiente:
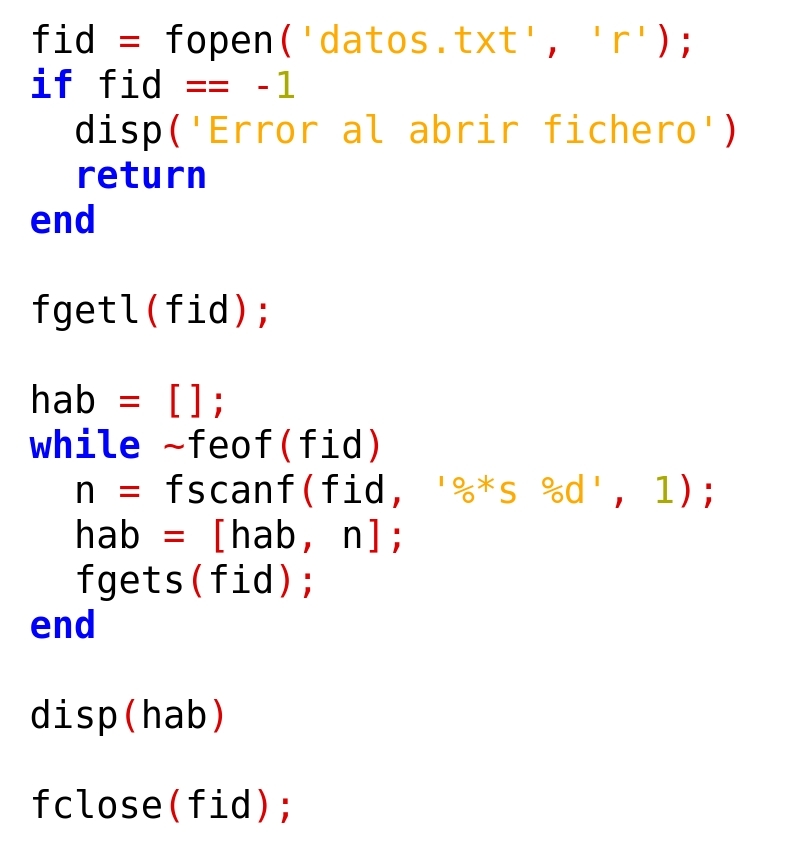
Analogamente a lo realizado en el caso resuelto con ‘sscanf’, aquí también podríamos utilizar la técnica de saltarnos datos, con lo que el programa quedaría:
Al ejecutar el programa, el resultado sería idéntico al anterior.
Para este caso de querer leer solo los datos numéricos de una de las columnas del fichero a un vector, podemos combinar la técnica de saltarse datos con la de repetir el formato hasta que se acabe el fichero, y leer el vector con el número de habitantes de los municipios en una única instrucción y sin utilizar bucles:
La salida de resultados sería la misma que en los dos casos anteriores.
Por último, utilizando esta técnica, podríamos leer una matriz que tenga en la primera columna el número de habitantes, y en la segunda columna la incidencia COVID:
Durante la corrección del examen parcial hemos observado que algunos alumnos utilizan claúsulas del tipo endif, endfor y similares para cerrar las instrucciones de bloque if, for, etc.
Esta sintaxis, que es totalmente correcta en Octave, no es compatible con MATLAB, donde genera un error de sintaxis.
En este curso tratamos de que todo el código que generamos sea compatible entre MATLAB y Octave y que se pueda utilizar de manera indistinta en uno u otro software. Por ello, no se debe utilizar dicha sintaxis en los programas del curso. Todas las instrucciones de bloque se deben terminar simplemente con la claúsula end (sin apellido).
Algunas versiones de Octave están configuradas de modo que, al teclear un bloque if, un bloque for u otros, autocompleta añadiendo la línea endif o endfor correspondiente.
Este comportamiento se puede modificar en la pantalla de preferencias que se encuentra en el menú ‘Editar->Preferencias’, en la pestaña del ‘Editor’, en la sección correspondiente al ‘Sangrado (Indentation)’. Ahí existe un desplegable que permite seleccionar el tipo de autocompletado que queremos: endif, solo end, o ninguno. La siguiente figura muestra dicha opción.
Os recomendamos que configuréis vuestros programas Octave con la opción ‘solo end’, o ‘ningún autocompletado’, para ahorraros el trabajo de modificar la claúsula del autocompletado en cada instrucción de bloque de vuestros programas.
La asignatura ‘Informática’ que se imparte en el primer curso de la Escuela de Ingenieros de Caminos de la Universidad Politécnica de Madrid (UPM), consiste en enseñar a los alumnos a utilizar MATLAB y Octave. En ambos casos, se trata de software matemático orientado al cálculo numérico. También ofrecen un lenguaje de programación, denominado lenguaje m, que permite la realización de programas.
MATLAB es un software privativo de la empresa Mathworks. Es un software caro, cada licencia cuesta unos dos mil euros al año. Octave es la versión de código abierto de MATLAB. Su utilización es libre y gratuita.
En la UPM se dispone de un acuerdo con Mathworks mediante el cual, tanto alumnos como profesores, disponemos de una licencia de MATLAB que podemos utilizar sin coste. Es la vieja técnica de regalar droga en la puerta del colegio para enganchar a los chicos a futuro. Y surte efecto. En la UPM se enseña preferentemente MATLAB frente a Octave.
Siempre que se trata de utilizar versiones de código abierto de algún software comercial, surge la pregunta de cuál es mejor de los dos. En la mayor parte de las ocasiones la pregunta está mal planteada, pues “ser mejor” es un concepto subjetivo, que depende en gran medida de los condicionantes del uso que se vaya a hacer del software.
Si nos fijamos únicamente en la velocidad de operación de los cálculos, MATLAB es más rápido. Lo que sucede es que, en la práctica, dicha velocidad es difícil de apreciar. Desde luego en los programas que hacemos en nuestro curso de informática no se nota en absoluto. Si uno hace el cálculo de la inversa de una matriz de 1000 filas y 1000 columnas, pues sí que se nota la diferencia. Lo que pasa es que no es habitual tener que hacer ese tipo de cálculos.
Pero hay otros aspectos que hay que valorar a la hora de decidir si un software es mejor que otro. Es paradigmático el caso del uso del lenguaje Python, que pese a ser mucho más lento que alternativas como el C u otras, no deja por ello de ser la principal opción a la hora de desarrollar aplicaciones de inteligencia artificial y muchos otros cálculos científicos. La existencia de librerías de funciones, la facilidad de uso, la facilidad programación y otros aspectos son fundamentales a la hora de decidirse por un lenguaje de programación concreto para su uso en determinado campo del conocimiento.
Pasa lo mismo con la comparación entre MATLAB y Octave. Octave, por ejemplo, es muy sencillo de utilizar desde otros lenguajes. Esto permite programar en cualquier lenguaje y utilizar por debajo Octave para la realización de los cálculos matemáticos complejos. Esta característica, por sí sola, puede ser clave a la hora de decidirse por su utilización. Creo que es uno de los motivos por los que Octave es la solución de cálculo numérico preferida en el CERN, seguramente el laboratorio de física de partículas más avanzado del mundo [1].
El funcionamiento de MATLAB y Octave es casi idéntico. Hay pocas diferencias y, la mayoría, ni siquiera es uno consciente de ellas en el funcionamiento normal. Siempre recomiendo a mis alumnos que, puesto que disponemos de licencia de uso de MATLAB, aprendan a utilizar los dos, que se instalen los dos programas en sus computadoras. En las clases yo utilizo preferentemente Octave, aunque siempre hago indicaciones de cómo resolver cuestiones concretas en MATLAB, que suelen estar relacionadas con la localización de opciones en el interfaz gráfico.
Hay otros aspectos más objetivos que me hacen pensar que Octave es una opción mejor que MATLAB para su utilización en el ámbito científico. Me llevan los demonios cada vez que leo un paper científico aceptado que utiliza MATLAB para resolver cálculos complejos. En mi opinión, esto no debería estar admitido en el ámbito científico. Cualquier experimento científico tiene que permitir que otros científicos puedan repetir el experimento de manera independiente. Pero, ¿cómo puede uno repetir un experimento que se resuelve mediante un algoritmo que no es de código abierto y que realiza los cálculos con una caja negra que es imposible de repasar? ¿Cómo se han resuelto las condiciones de borde? ¿Qué tratamiento da el algoritmo a determinados valores? De hecho, se han producido a veces errores importantes en diferentes campos científicos motivados por bugs en los algoritmos de software de código cerrado que no se habían detectado. Un ejemplo dramático se dio hace unos años en relación con el software que gestiona los scanner cerebrales [2]. Seguramente esta es otra de las razones por las que el CERN utiliza Octave: cualquier algoritmo se puede repasar y analizar, para detectar posibles errores, lo que no es posible hacer con MATLAB.
Y entonces, si esto es así, ¿por qué se permite la publicación de artículos científicos que basan sus cálculos en algoritmos de código cerrado de MATLAB? Pues para mí es inexplicable. La ignorancia y el dinero están detrás, no me cabe duda.
Hay un aspecto que suele condicionar la utilización de software privativo por parte de algunos usuarios. Se trata del interfaz gráfico. Los programas “caros” suelen tener interfaces gráficos más vistosos. El software libre lo desarrolla una comunidad de desarrolladores que actúa, en su mayor parte, de forma artesanal y en muchos casos de manera altruista. En ese sentido, no se suele dedicar mucho esfuerzo a la vistosidad o al marketing.
La versión actual de MATLAB utiliza un interfaz gráfico basado en la barra de herramientas que impuso hace unos años Microsoft en Windows, en su popular suite Office. Se basa en una barra de herramientas con botones grandes que permiten que cada opción lleve asociada una imagen coloreada. Hay botones que son eso, un botón. Otros son desplegables que abren a su vez otras opciones. También hay unas pestañas que permiten seleccionar diferentes barras de herramientas. Empresas como Microsoft o Apple nos tratan de imponer desde hace años la sustitución de las palabras por las imágenes, en las formas de navegar a través de las opciones que ofrecen los programas. Personalmente no me gusta esa forma de interpretar la navegación por un mapa de opciones. Me sitúo mejor navegando al viejo estilo Menú->Submenú, que me proporciona una estructura de árbol en la cuál mi cerebro se posiciona con más facilidad. En las barras de herramientas se pierde esa organización de la información en forma de árbol.
Además, los botones me suelen obligar a utilizar más el ratón y menos el teclado. Normalmente tengo que sobrevolar el botón con el cursor del ratón para que aparezca el tip de texto e interpretar adecuadamente la opción que busco, lo que me parece una pérdida de tiempo. Estoy acostumbrado a utilizar el teclado. Los menús son fáciles de acceder mediante combinaciones de teclas. Cada vez que tengo que soltar el teclado y agarrar el ratón, me parece que pierdo el tiempo.
Por ello, y aunque comprendo que a algunos les parezca mejor el interfaz gráfico de MATLAB, a mí personalmente me gusta menos que el de Octave.
Hay una razón de tipo social, que supongo que también es opinable. Imponer a nuestros futuros científicos e ingenieros la utilización de un software “caro”, cuando existen alternativas libres perfectamente equiparables, me parece ineficiente. La utilización de soluciones libres y de código abierto, permite que el dinero, en vez de utilizarse en pagar licencias a multinacionales, se utilice en otras cosas, por ejemplo, en pagar a desarrolladores, científicos e ingenieros locales.
En mi uso particular, siempre uso Octave. A mí me gusta más. No tengo ninguna duda de que es un software mucho mejor, en el contexto de utilización que yo hago. Y por ello, mientras siga siendo posible, seguiré utilizando en mis clases de manera preferente Octave frente a MATLAB, y seguiré recomendando a mis alumnos que aprendan a utilizar los dos programas.
He subido a youtube algunos de los vídeos que tenemos publicados en la plataforma Moodle de la asignatura en la Escuela de Caminos, de forma que se puedan ver en abierto, sin necesidad de acceder a ellos a través de Moodle.
El enlace a la lista de reproducción es el siguiente: