Introducción
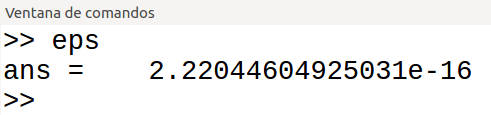
Desde el año 2015, de acuerdo con la encuesta anual que realiza Stack Overflow entre más de 80.000 programadores de todo el mundo, Rust ha resultado ser el lenguaje que más gustaba (The most loved language).
Rust se creó con el objetivo de obtener un lenguaje de prestaciones similares o superiores a las de C o C++, pero poniendo énfasis en la seguridad del código, aspecto en el que estos lenguajes han dado lugar a numerosos problemas.
Pero Rust no solo ofrece código seguro. Rust ofrece una documentación de alta calidad, permite la programación concurrente de manera eficiente y segura, permite programar en WebAssembly, ofrece un alto rendimiento en el procesamiento de grandes cantidades de datos y, además, dispone de un compilador muy efectivo y un entorno de desarrollo completo, con servicios para documentación de programas, servicios para test unitarios o de integración, servicios para control de versiones y mucho más.
Rust es un lenguaje de código abierto. Inicialmente se desarrolló al amparo de la empresa Mozilla. Desde 2021, el desarrollo está coordinado por la Fundación Rust, que es apoyada y financiada por las grandes empresas del software.
Rust no es un lenguaje orientado a objetos propiamente dicho, aunque se pueden emular muchas de las técnicas que se utilizan en ese paradigma de programación. La mayores influencias en el lenguaje Rust provienen de SML, OCaml, C++, Cyclone, Haskell y Erlang. La programación funcional sí casa mejor con la filosofía del lenguaje Rust, que sin ser un lenguaje funcional estricto, permite realizar una programación funcional eficiente. Puede ser una buena herramienta para pasarse a la programación funcional.
Desde su primera versión estable de enero de 2014, Rust se utiliza en los desarrollos de grandes empresas, como Amazon, Discord, Dropbox, Facebook (Meta), Google (Alphabet) y Microsoft. Actualmente, Rust se utiliza para desarrollar el nucleo de sistemas operativos como Linux, Windows y Android.
A pesar de que se trata de un lenguaje relativamente nuevo, dispone ya de una amplia librería de utilidades que facilitan la programación dentro de cualquier ámbito.
Por supuesto, todas estas ventajas que ofrece Rust son a costa de una curva de aprendizaje un poco más pendiente al principio. Programar en Rust requiere más esfuerzo que programar en otros lenguajes, como por ejemplo, Python. Pero los resultados que se obtienen compensan el esfuerzo dedicado.
GeoRust
Existe un ecosistema muy amplio de herramientas geoespaciales para trabajar con Rust. En este artículo se va a hacer una introducción al uso de la librería geo_types, aunque hay otras que servirán para ampliar conocimientos con posterioridad:
- geo: utiliza los tipos de geo_types y añade un gran número de funciones para cálculos geoespaciales.
- geojson: proporciona métodos para leer y escribir objetos Geo-JSON según la especificación IETF RFC 7946.
- proj: proporciona servicios de cambio de coordenadas utilizando bindings a proj.
- gdal: proporciona bindings para usar la librería GDAL, que permite procesar formatos geoespaciales raster y vectoriales.
- Librerías para formatos específicos: geotiff, kml, netCDF, osm, shapefile, tilejson y algunas más.
Además se dispone de diversas librerías con utilidades para geocodificación y otras tareas de análisis geoespacial.
La totalidad de librerías se puede consultar en el siguiente enlace:
Crate geo_types
Esta librería proporciona estructuras para los tipos de geometría habituales. Se añade al proyecto con:
cargo add geo_types
Si se necesitan algoritmos geoespaciales, hay que usar la crate geo, que reexporta los tipos de datos de geo_type. Se realiza a continuación una introducción al uso de algunas de las primitivas fundamentales.
Coord
La estructura en la que se basan los demás tipos es geo::geometry::Coord, que es una pareja de coordenadas de algún tipo numérico, por defecto, f64.
pub struct Coord<T = f64> where
T: CoordNum,{
pub x: T,
pub y: T,
}
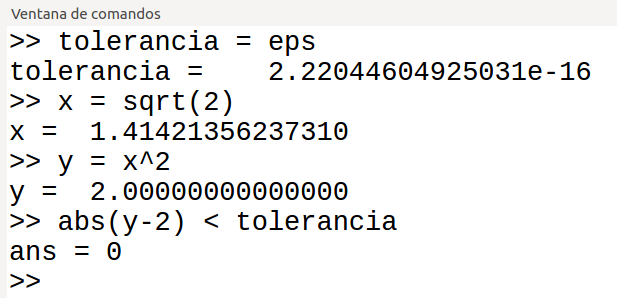
El trait CoordNum proporciona operaciones sumar, restar, multiplicar, dividir y algunas otras, sobre objetos del tipo Coord. Este trait lo implementan los números float y los enteros. Em los algoritmos que solo tienen sentido con floats, como el cálculo de un área, hay que usar tipos que implementen CoordFloat.
También hay una macro, coord!{}, que permite crear instancias de Coord. Se puede acceder a los campos x o y de manera individual y también hay un método x_y()que devuelve una tupla con las coordenadas (x, y):
use geo_types::coord;
let c = coord! {
x: 40.02f64,
y: 116.34,
};
assert_eq!(c.x, 40.02);
assert_eq!(c.y, 116.34);
let (x, y) = c.x_y();
assert_eq!(y, 116.34);
assert_eq!(x, 40.02f64);
Coord no es una primitiva geoespacial, pero forma parte de todas las primitivas.
Point
La estructura Point se utiliza para representar un punto en dos dimensiones.
pub struct Point<T = f64>(pub Coord<T>)
where
T: CoordNum;
Se pueden crear instancias de Point utilizando el método Point::new(), la macro point!, o, utilizando from(), a partir de una tupla, de una instancia de Coord o de un array:
use geo_types::{coord, point, Point};
let p0: Point = Point::new(3.14, 6.28);
let p1 = point! { x: 1.5, y: 0.5 };
let p2: Point = (0., 1.).into();
let p3: Point = [1.0, 2.0].into();
let c = coord! { x: 10., y: 20. };
let p4: Point = c.into();
El tipo Point es una estructura no etiquetada cuyo único campo es una instancia de Coord. Se puede acceder a x e y utilizando los métodos x(), y() o el método x_y(), que devuelve una tupla:
use geo_types::{Point};
let p: Point = Point::new(3.14, 6.28);
assert_eq!(p.x(), 3.14);
assert_eq!(p.y(), 6.28);
assert_eq!(p.x_y(), (3.14, 6.28));
Line
La estructura Line representa un segmento con dos Coord:
pub struct Line<T = f64>where
T: CoordNum,{
pub start: Coord<T>,
pub end: Coord<T>,
}
Se pueden crear instancias de Line utilizando el método new() y a partir de un array de tuplas:
use geo_types::{Coord, Line};
let line_1: Line = Line::new(
Coord{x:3.14, y:6.28},
Coord{x:10., y: 6.}
);
let line_2: Line = [(3.14, 6.28), (10., 6.)].into();
assert_eq!(line_2.start_point().x(), 3.14);
Dispone de unos métodos start_point() y end_point() que devuelven los puntos inicial y final. También hay un método points() que devuelve una tupla con los dos puntos. Hay métodos dx() y dy() que devuelven el incremento en cada dirección. El método delta() devuelve una tupla con ambos incrementos. El método slope() devuelve la pendiente del segmento.
LineString
Es una colección ordenada de dos o mas Coord que representa la trayectoria entre dos puntos.
pub struct LineString<T: CoordNum = f64>(pub Vec<Coord<T>>);
Una LineString puede ser cerrada si no tiene puntos o si el primer y último puntos son el mismo.
Se puede crear una LineString llamando directamente a la función new(), utilizando la macro line_string!, convirtiendo un vector de tuplas de Coord o un vector de arrays de Coord:
use geotypes::{coord, LineString, linestring};
let line_string = LineString::new(vec![
coord! { x: 0., y: 0. },
coord! { x: 10., y: 0. },
]);
let line_string = line_string![
(x: 0., y: 0.),
(x: 10., y: 0.),
];
let line_string: LineString = vec![(0., 0.), (10., 0.)].into();
let line_string: LineString = vec![[0., 0.], [10., 0.]].into();
También se pueden obtener un LineString a partir de iteradores de Coord:
let mut coords_iter = vec![
coord! { x: 0., y: 0. },
coord! { x: 10., y: 0. }].into_iter();
let line_string: LineString<f32> = coords_iter.collect();
LineString ofrece cinco iteradores: coords, coords_mut, points, lines y triangles.
use geo_types::{coord, LineString};
let line_string = LineString::new(vec![
coord! { x: 0., y: 0. },
coord! { x: 10., y: 0. }
]);
linestring.coords().for_each(|coord| println!("{:?}", coord));
for point in line_string.points() {
println!("Point x = {}, y = {}", point.x(), point.y());
}
Si en un bucle se utiliza directamente el iterador procedente del trait IntoIterator, hay que cuidar la propiedad del LineString:
for coord in &line_string {
println!("Coordinate x = {}, y = {}", coord.x, coord.y);
}
for coord in line_string {
println!("Coordinate x = {}, y = {}", coord.x, coord.y);
}
A partir de un LineString se puede obtener directamente un vector de Coord o un vector de Point:
use geo_types::{coord, LineString, Point};
let line_string = LineString::new(vec![
coord! { x: 0., y: 0. },
coord! { x: 10., y: 0. },
]);
let coordinate_vec = line_string.clone().into_inner();
point_vec = line_string.clone().into_points();
Polygon
Es un área bidimensional. La frontera exterior es una LineString. Puede tener huecos, que estarán definidos por otras LineStrings.
Se puede consultar en:
Polygon in geo_types::geometry – Rust
Geometry
Es un enum representando todos los tipos de geometrías:
pub enum Geometry<T: CoordNum = f64> {
Point(Point<T>),
Line(Line<T>),
LineString(LineString<T>),
Polygon(Polygon<T>),
MultiPoint(MultiPoint<T>),
MultiLineString(MultiLineString<T>),
MultiPolygon(MultiPolygon<T>),
GeometryCollection(GeometryCollection<T>),
Rect(Rect<T>),
Triangle(Triangle<T>),
}
Todas las primitivas geométricas se pueden convertir en un Geometry utilizando Into::into(). De manera similar, se puede utilizar TryFrom::try_from()para obtener la primitiva a partir de un Geometry:
use std::convert::TryFrom;
use geo_types::{Point, point, Geometry};
let p = point!(x: 1.0, y: 1.0);
let pe: Geometry = p.into();
let pn = Point::try_from(pe).unwrap();
JSON
Como ejemplo, se va a mostrar cómo pasar una Line a JSON:
fn test_json() -> serdejson::error::Result<()> {
use geotypes::{Coord, Line};
use serdejson;
let line: Line = [(3.14, 6.28), (10., 6.)].into();
let cad = serde_json::to_string(&line)?;
println!("{}", cad);
let value: serde_json::Value = serde_json::from_str(cad.as_str())?;
assert!(value.is_object());
Ok(())
}
(Santiago Higuera de Frutos – Enero 2024)