Herencia y composición: de qué estamos hablando
Uno de los debates más fecundos del diseño orientado a objetos es el de cuándo usar herencia y cuándo usar composición (o agregación). La herencia es la primera herramienta que aprende cualquier estudiante de POO y esa familiaridad temprana suele convertirla en un martillo que hace que todo parezcan clavos. Este artículo revisa qué dicen los autores más influyentes del campo y propone ejemplos concretos para ayudarte a elegir bien.
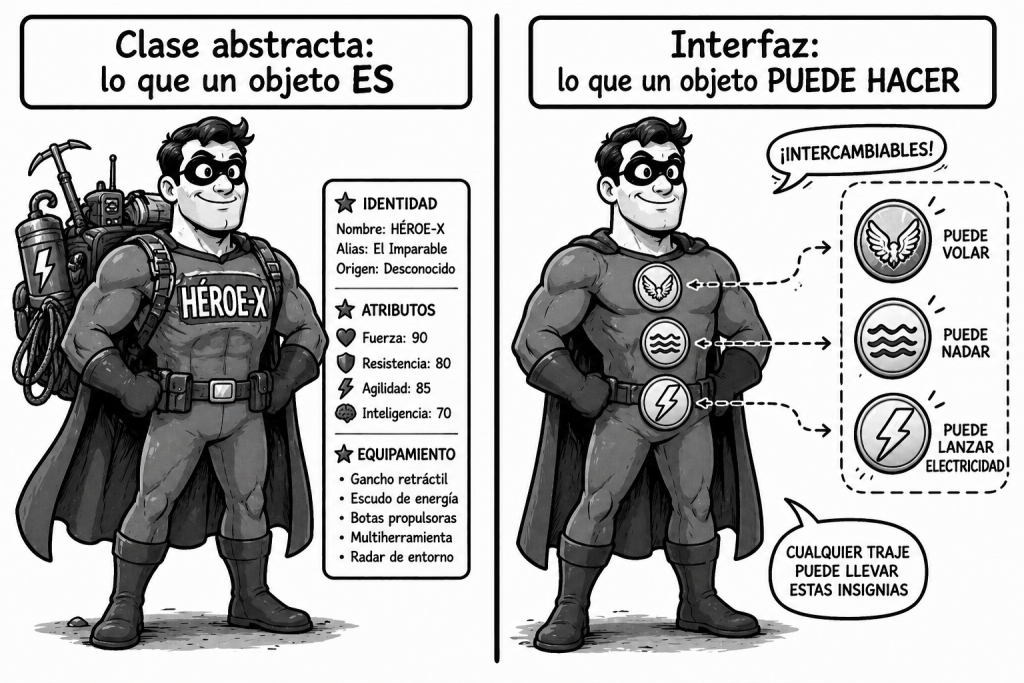
Antes de entrar en el debate, conviene fijar con precisión qué significa cada mecanismo. Aunque ya los conoces de clase, vale la pena verlos uno al lado del otro para apreciar sus diferencias estructurales.
Herencia
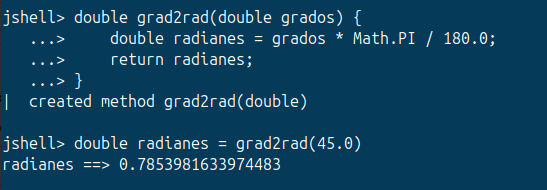
La herencia es el mecanismo por el cual una clase (la subclase o clase hija) adquiere automáticamente los atributos y métodos de otra clase (la superclase o clase madre). En Java se expresa con la palabra clave extends:
public class Animal {
protected String nombre;
public Animal(String nombre) {
this.nombre = nombre;
}
public void comer() {
System.out.println(nombre + " está comiendo.");
}
}
public class Perro extends Animal {
public Perro(String nombre) {
super(nombre);
}
public void ladrar() {
System.out.println(nombre + " está ladrando.");
}
}
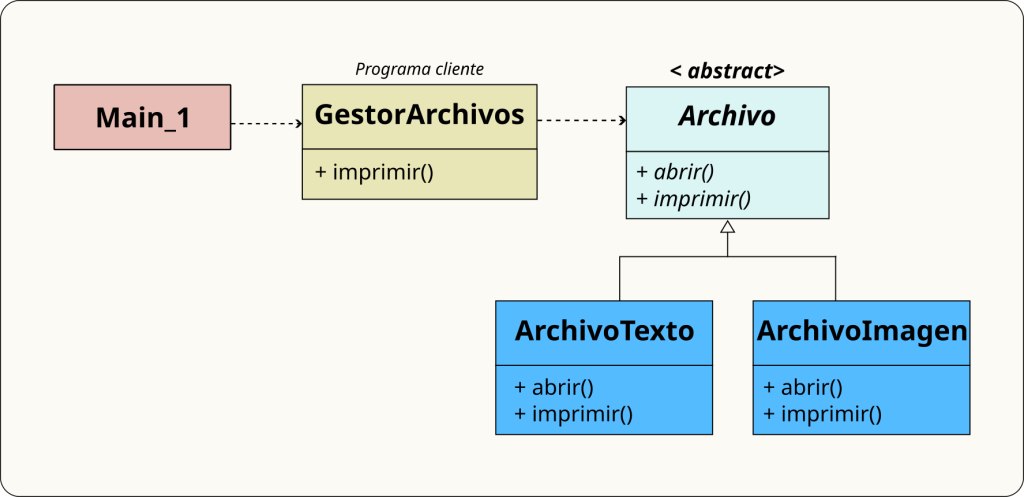
El diagrama UML de la jerarquía anterior es:
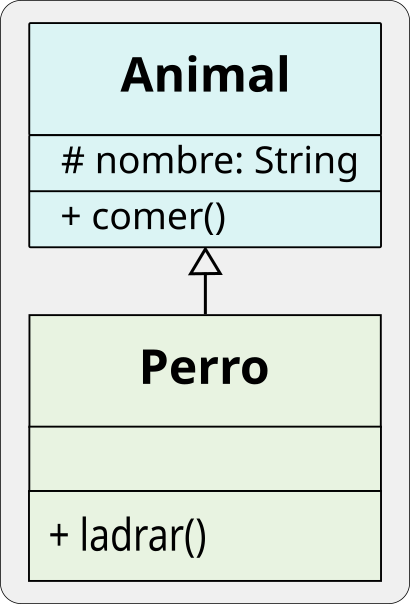
Un Perro hereda el método comer(), sin necesidad de redefinirlo y además añade su propio método ladrar(). La relación que modela la herencia es la relación “es-un” (is-a): un perro es un animal.
Desde el punto de vista de la implementación, la herencia establece una relación estática: se fija en el momento de escribir el código y no puede cambiar en tiempo de ejecución. Además, la subclase tiene acceso, mediante protected, a los detalles internos de la superclase, lo que crea un acoplamiento fuerte entre ambas.
Composición (y agregación)
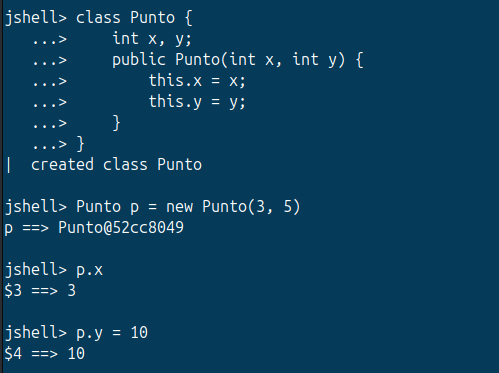
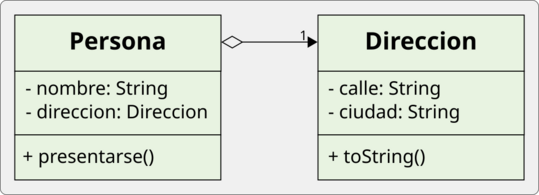
La composición es el mecanismo por el cual una clase contiene una referencia a un objeto de otra clase como uno de sus campos. En lugar de heredar el comportamiento, lo delega al objeto contenido. Como ejemplo, vamos a desarrollar las siguientes clases: Persona y Direccion :
class Direccion {
private String calle;
private String ciudad;
public Direccion(String calle, String ciudad) {
this.calle = calle;
this.ciudad = ciudad;
}
public String toString() {
return calle + ", " + ciudad;
}
}
class Persona {
private String nombre;
private Direccion direccion; // ← Persona TIENE UNA Direccion
public Persona(String nombre, Direccion direccion) {
this.nombre = nombre;
this.direccion = direccion;
}
public void presentarse() {
System.out.println("Me llamo " + nombre + " y vivo en " + direccion);
}
}
En este caso, el diagrama UML sería:
El uso podría ser:
Direccion dir = new Direccion("Calle Mayor, 5", "Madrid");
Persona alumno = new Persona("Ana García", dir);
alumno.presentarse();
Que daría lugar a la siguiente salida:
Me llamo Ana García y vivo en Calle Mayor, 5, Madrid
La relación que modela la composición es la relación “tiene-un” (has-a): una Persona tiene una Direccion. La Persona no es una Direccion, ni hereda nada de ella, simplemente la utiliza.
📎 Composición vs. agregación: técnicamente, hablamos de composición cuando el objeto contenido no puede existir sin el contenedor y de agregación, cuando el objeto contenido tiene vida propia y puede ser compartido. El ejemplo de
PersonayDireccionilustra precisamente la agregación: la dirección se crea fuera del constructor dePersonay podría ser compartida por dos personas que viven en el mismo domicilio. Un ejemplo de composición estricta sería unPedidoque contiene sus propiasLineas de pedido: si el pedido desaparece, sus líneas no tienen sentido fuera de él. En la práctica del diseño de software, el término “composición” se usa con frecuencia para referirse a ambos casos, y así lo hacen también los autores que citaremos.
A diferencia de la herencia, la composición mantiene la encapsulación intacta: la Persona solo conoce la interfaz pública de Direccion, no sus detalles internos. Y si Direccion tiene varios tipos posibles, basta con que todos implementen una interfaz común para que una Persona pueda trabajar con cualquiera de ellos, incluso cambiando la dirección en tiempo de ejecución.
La tabla siguiente resume las características de los dos tipos de relación entre clases:
| Herencia | Composición | |
|---|---|---|
| Relación modelada | “es-un” (is-a) | “tiene-un” (has-a) |
| Acoplamiento | Alto (la subclase conoce los internos de la superclase) | Bajo (solo se conoce la interfaz pública) |
| Encapsulación | Se debilita | Se preserva |
| Flexibilidad | Estática (fijada en compilación) | Dinámica (puede cambiar en ejecución) |
| Reutilización | Automática, pero rígida | Explícita, pero flexible |
Ejemplo de utilización incorrecta de la herencia
Vamos a ver un ejemplo en el que la utilización de la herencia llevaría a un diseño incorrecto. Tenemos una clase Motor que dispone de los métodos arrancar() y apagar(). Podríamos crear una clase Coche, que derive de la clase Motor, con el fin de reutilizar estos métodos:
// ─── MAL DISEÑO: Coche extiende Motor ───────────────────────────────────────
class Motor {
private int cilindros;
public Motor(int cilindros) {
this.cilindros = cilindros;
}
public void arrancar() {
System.out.println("Motor de " + cilindros + " cilindros arrancando.");
}
public void apagar() {
System.out.println("Motor apagado.");
}
}
// Un Coche "es un" Motor??? No tiene ningún sentido.
class Coche extends Motor {
private String modelo;
public Coche(String modelo, int cilindros) {
super(cilindros);
this.modelo = modelo;
}
public void describir() {
System.out.println("Coche: " + modelo);
}
}
Con este diseño, alguien puede escribir código absurdo que Java acepta sin quejarse:
Motor vehiculo = new Coche("Seat Ibiza", 4); // Un Coche ES UN Motor???
vehiculo.arrancar();
Y lo peor: si mañana queremos que el Coche sea también Vehiculo (para poder meterlo en una lista junto a motos y camiones), Java no nos lo permite porque ya hemos “gastado” la herencia en Motor.
// ─── BUEN DISEÑO: Coche tiene un Motor ──────────────────────────────────────
class Motor {
private int cilindros;
public Motor(int cilindros) {
this.cilindros = cilindros;
}
public void arrancar() {
System.out.println("Motor de " + cilindros + " cilindros arrancando.");
}
public void apagar() {
System.out.println("Motor apagado.");
}
}
class Coche {
private String modelo;
private Motor motor; // ← Coche TIENE UN Motor
public Coche(String modelo, Motor motor) {
this.modelo = modelo;
this.motor = motor;
}
public void arrancar() {
System.out.println("Arrancando el " + modelo + "...");
motor.arrancar(); // ← delega en el Motor
}
public void apagar() {
motor.apagar();
System.out.println(modelo + " apagado.");
}
}
Ahora el uso es natural y semánticamente correcto:
Motor motor = new Motor(4);
Coche coche = new Coche("Seat Ibiza", motor);
coche.arrancar();
coche.apagar();
Salida:
Arrancando el Seat Ibiza...
Motor de 4 cilindros arrancando.
Motor apagado.
Seat Ibiza apagado.
La ventaja adicional, que vale la pena señalar, es que ahora Motor y Coche son independientes: si mañana el Motor cambia internamente, por ejemplo, añade un sistema de inyección, el Coche no se entera ni se rompe, siempre que arrancar() y apagar() sigan funcionando igual. Con la herencia, cualquier cambio en Motor podría afectar a Coche de maneras imprevistas.
Los peligros de heredar de una clase ajena
Hay situaciones en las que la herencia introduce problemas sutiles y difíciles de detectar. El caso más problemático es cuando derivamos una clase de otra en la que no tenemos acceso al código fuente: por ejemplo, una clase perteneciente a una librería de terceros.
Considera la siguiente clase Array, que envuelve un ArrayList y ofrece dos métodos para añadir elementos:
class Array {
private ArrayList<Object> a = new ArrayList<Object>();
public void add(Object element) {
a.add(element);
}
public void addAll(Object elements[]) {
for (int i = 0; i < elements.length; ++i)
a.add(elements[i]); // esta línea va a cambiar
}
}
Se supone que esta clase Array pertenece a una librería de la que no tenemos acceso al código fuente. En nuestra aplicación necesitamos una variante que lleve la cuenta del número de elementos añadidos. Parece razonable derivar una clase ArrayCount que sobreescriba ambos métodos:
public class ArrayCount extends Array {
private int count = 0;
@Override
public void add(Object element) {
super.add(element);
++count;
}
@Override
public void addAll(Object elements[]) {
super.addAll(elements);
count += elements.length;
}
public int getCount() {
return count;
}
}
Probamos la clase y todo funciona correctamente:
public class Main {
public static void main(String[] args) {
Integer[] list = {1, 2, 3};
ArrayCount ac = new ArrayCount();
ac.addAll(list);
System.out.println(ac.getCount()); // Imprime 3 ✓
}
}
El contador vale 3, que es el valor correcto. Todo parece en orden.
Ahora bien: supongamos que los autores de la librería publican una nueva versión y modifican addAll() internamente. El cambio consiste en que, en lugar de actuar directamente sobre el ArrayList, ahora llaman a su propio método add():
public void addAll(Object elements[]) {
for (int i = 0; i < elements.length; ++i)
add(elements[i]); // esta línea ha cambiado
}
Los autores comprueban que la nueva versión pasa todos sus tests y que la funcionalidad de la librería no ha variado. El cambio parece inocuo. Pero si actualizamos la librería y volvemos a ejecutar nuestro programa:
6
El contador muestra 6 en lugar de 3. Nuestro código no ha cambiado ni una línea, y sin embargo ahora falla.
¿Qué ha ocurrido? El mecanismo de enlace dinámico de Java hace que cuando Array.addAll() llama a add(), el método que se ejecuta no es el add() de Array sino el add() sobreescrito en ArrayCount. El resultado es que el contador se incrementa tres veces dentro de add(), y luego otras tres veces más al final de addAll(). Seis en total.
No podemos detectar el problema leyendo nuestro código, porque el problema está en el código de la librería, al que no tenemos acceso. Ni siquiera podemos saber que addAll() llama internamente a add().
Este fenómeno tiene nombre: se conoce como el problema de la clase base frágil (fragile base class problem). La raíz del problema es que la herencia crea un acoplamiento muy fuerte entre la subclase y la superclase: la subclase depende, no solo de la interfaz pública de la superclase, sino también de sus detalles de implementación internos, que pueden cambiar en cualquier momento sin previo aviso.
La solución es usar composición en lugar de herencia:
public class ArrayCount {
private Array array = new Array(); // ← contiene un Array, no extiende uno
private int count = 0;
public void add(Object element) {
array.add(element);
++count;
}
public void addAll(Object elements[]) {
array.addAll(elements);
count += elements.length;
}
public int getCount() {
return count;
}
}
Ahora ArrayCount no depende de cómo Array implemente addAll() internamente. Da igual si llama a add() o no: nosotros solo usamos su interfaz pública y el contador se gestiona íntegramente en nuestro código. Si la librería cambia su implementación interna, nuestro contador sigue siendo correcto.
Qué dice la bibliografía de referencia
En esta segunda parte del artículo veremos cómo se han pronunciado sobre esta cuestión algunos de los autores más influyentes del diseño orientado a objetos. Es posible que algunos conceptos exijan un nivel algo más avanzado en POO para comprenderlos completamente, pero pueden leerse como una guía para cuando se quiera profundizar.
1. La Banda de los Cuatro (GoF)
El punto de partida obligatorio es el libro Design Patterns: Elements of Reusable Object-Oriented Software (Gamma, Helm, Johnson y Vlissides, 1994), conocido popularmente como el libro de la Gang of Four o GoF. En su introducción, los autores formulan dos principios de diseño orientado a objetos reutilizable. El segundo de ellos es:
“Favor object composition over class inheritance.” — Gamma et al., Design Patterns, 1994, p. 20
No es una frase suelta. Viene precedida por una página y media de argumentación y seguida de otro tanto sobre delegación. El núcleo del razonamiento es el siguiente:
- La herencia es lo que los autores llaman reutilización de caja blanca (white-box reuse): la subclase tiene acceso, o al menos dependencia, de los detalles internos de la superclase. Esto crea un acoplamiento fuerte que hace el código frágil.
- La composición, en cambio, es reutilización de caja negra (black-box reuse): el objeto compuesto solo conoce la interfaz del objeto que contiene, no sus tripas.
- Los autores advierten de que “inheritance breaks encapsulation” (la herencia rompe la encapsulación) porque, si la superclase cambia su implementación interna, las subclases pueden romperse aunque su propio código no haya variado.
- Su observación empírica es contundente: en su experiencia, los diseñadores abusan de la herencia (designers overuse inheritance).En una entrevista en 2004, Erich Gamma (uno de los cuatro autores) amplió su posición:
“Inheritance is a cool way to change behavior. But we know that it’s brittle […] There’s a tight coupling between the base class and the subclass. […] Composition has a nicer property. The coupling is reduced by just having some smaller things you plug into something bigger.” — Erich Gamma, entrevista en Artima (2004)
También puntualizó algo importante que suele olvidarse: “A common misunderstanding is that composition doesn’t use inheritance at all.” La composición suele apoyarse en herencia de interfaz (implementar interfaces), que es semánticamente sana. Lo que los autores desaconsejan es el abuso de la herencia de implementación entre clases concretas.
2. Joshua Bloch, Effective Java
Joshua Bloch, arquitecto principal de la API de Java en Sun Microsystems, dedica dos ítems completos a este tema en su libro Effective Java (cuya tercera edición data de 2018):
- Ítem 18: “Favor composition over inheritance”
- Ítem 19: “Design and document for inheritance or else prohibit it”El argumento central de Bloch en el Ítem 18 es que la herencia viola la encapsulación: una subclase depende de los detalles de implementación de su superclase, detalles que pueden cambiar de una versión a otra. Su recomendación práctica es:
“If you are tempted to have a class B extend a class A, ask yourself the question: is every B really an A?” — Bloch, Effective Java 3ª ed., Ítem 18
Si la respuesta no es un sí rotundo, B no debería extender A. En su lugar, recomienda dar a la nueva clase un campo privado que contenga una instancia de la clase existente (forwarding o delegación), patrón que llama wrapper class o clase envoltorio.
El Ítem 19 va aún más lejos: si una clase no ha sido diseñada explícitamente para ser heredada (con documentación detallada de sus invariantes y sus métodos sobreescribibles), debería prohibirse su extensión declarándola final o haciendo privados sus constructores.
3. Barbara Liskov y el LSP
Barbara Liskov es conocida principalmente por el Principio de Sustitución de Liskov (LSP), formulado en su conferencia de 1987 “Data Abstraction and Hierarchy” (OOPSLA’87) y formalizado junto a Jeannette Wing en 1994:
“If for each object o1 of type S there is an object o2 of type T such that for all programs P defined in terms of T, the behavior of P is unchanged when o1 is substituted for o2, then S is a subtype of T.” — Liskov & Wing, 1994
¿Qué tiene que ver el LSP con la elección entre herencia y composición? Todo. El LSP establece la condición semántica mínima que debe cumplirse para que la herencia sea legítima: una subclase debe poder sustituir a su superclase en cualquier contexto sin alterar el comportamiento correcto del programa. Cuando ese criterio no se cumple, es una señal inequívoca de que la relación entre las dos clases no es una verdadera relación “es-un” y de que debería reemplazarse por composición.
Liskov también dejó constancia en “Data Abstraction and Hierarchy” de que la herencia de jerarquías es adecuada cuando la relación se identifica claramente en la fase de diseño; en caso contrario, otras alternativas (agrupación por composición, paso de procedimientos como argumentos) pueden ser superiores.
En su libro conjunto con John Guttag, Program Development in Java: Abstraction, Specification, and Object-Oriented Design (2001), Liskov y Guttag desarrollaron un conjunto de reglas prácticas (de firma, de propiedades y de métodos) para identificar cuándo un subtipo es semánticamente correcto.
4. Robert C. Martin — SOLID y Agile Software Development
Robert C. Martin (Uncle Bob) popularizó el acrónimo SOLID para referirse a cinco principios de diseño orientado a objetos. Tres de ellos conectan directamente con este debate:
- LSP (Liskov Substitution Principle): ya discutido arriba.
- OCP (Open/Closed Principle): las entidades software deben estar abiertas para extensión pero cerradas para modificación. Este principio se satisface frecuentemente mejor con composición (patrones Strategy, Decorator) que con herencia directa.
- DIP (Dependency Inversion Principle): los módulos de alto nivel no deben depender de módulos de bajo nivel; ambos deben depender de abstracciones. Esto favorece composición con interfaces frente a herencia de clases concretas.En su libro Agile Software Development: Principles, Patterns, and Practices (2002), Martin desarrolla el concepto de “fragile base class problem”: cuando una superclase cambia, las subclases pueden romperse de maneras imprevistas, aunque el cambio parezca inocuo. Es exactamente el mismo problema que señalan GoF y Bloch, analizado desde la perspectiva de la gestión del cambio en sistemas ágiles.
Los dos criterios fundamentales
Para decidir entre herencia y composición, la literatura coincide en señalar dos criterios de decisión. El resto de las propiedades que se recogen a continuación son consecuencias que se derivan de la elección, no criterios en sí mismos.
Criterios de decisión:
| Criterio | Herencia | Composición |
|---|---|---|
| Relación semántica | “es-un” (is-a) | “tiene-un” (has-a) |
| Prueba de sustitución | La subclase puede usarse donde se espera la superclase (LSP) | No es necesaria la sustitución |
El primer criterio (“es-un“) es necesario pero no suficiente. El segundo (LSP) es el que lo valida semánticamente: una relación “es-un” que no supera la prueba de sustitución no justifica la herencia.
Propiedades resultantes de la elección:
| Propiedad | Herencia | Composición |
|---|---|---|
| Encapsulación | Se debilita | Se preserva |
| Flexibilidad en tiempo de ejecución | Fija en compilación | Puede cambiar dinámicamente |
| Acoplamiento | Alto (caja blanca) | Bajo (caja negra) |
Estas propiedades no son criterios de elección, sino consecuencias: si la herencia es semánticamente correcta, su mayor acoplamiento y menor flexibilidad son el precio a pagar. Si no lo es, esas mismas propiedades son razones adicionales para preferir la composición.
Ejemplos avanzados
Ejemplo 1: El clásico error — Stack sobre Vector
Este es el ejemplo canónico de Bloch. En la API estándar de Java, la clase Stack extiende Vector:
// Así está en java.util — ¡un ejemplo de lo que NO se debe hacer!
public class Stack<E> extends Vector<E> {
public E push(E item) { ... }
public E pop() { ... }
public E peek() { ... }
public boolean empty() { ... }
}
El problema es que Stack hereda toda la interfaz pública de Vector, incluyendo métodos como add(int index, E element) o remove(int index) que violan la semántica de una pila: permiten insertar y eliminar elementos en posiciones arbitrarias. Una pila no “es un” vector, tiene un vector. El diseño correcto es:
public class Pila<E> {
private final List<E> elementos = new ArrayList<>();
public void push(E elemento) {
elementos.add(elemento);
}
public E pop() {
if (empty()) throw new EmptyStackException();
return elementos.remove(elementos.size() - 1);
}
public E peek() {
if (empty()) throw new EmptyStackException();
return elementos.get(elementos.size() - 1);
}
public boolean empty() {
return elementos.isEmpty();
}
}
Ahora la semántica es correcta: solo se exponen las operaciones de pila y la implementación interna (un ArrayList) puede cambiarse sin afectar a los clientes.
Ejemplo 2: La trampa del LSP — Rectángulo y Cuadrado
Este es el ejemplo más citado para ilustrar una violación del LSP. Matemáticamente, todo cuadrado es un rectángulo, así que parece razonable hacer:
public class Rectangulo {
protected int ancho;
protected int alto;
public void setAncho(int ancho) { this.ancho = ancho; }
public void setAlto(int alto) { this.alto = alto; }
public int area() { return ancho * alto; }
}
public class Cuadrado extends Rectangulo {
@Override
public void setAncho(int lado) {
this.ancho = lado;
this.alto = lado; // ← mantiene el invariante del cuadrado
}
@Override
public void setAlto(int lado) {
this.ancho = lado; // ← ídem
this.alto = lado;
}
}
El problema surge cuando un método recibe un Rectangulo por parámetro:
public static void duplicarAlto(Rectangulo r) {
int anchoOriginal = r.ancho;
r.setAlto(r.alto * 2);
// Esperamos que el ancho no haya cambiado
assert r.ancho == anchoOriginal : "¡Si el parámetro es un Cuadrado, el ancho ha cambiado!";
}
Si pasamos un Cuadrado, la aserción falla: setAlto también modificó el ancho. El Cuadrado no puede sustituir al Rectangulo sin romper el programa, luego viola el LSP. La herencia es incorrecta aquí.
La solución es no usar herencia de implementación. Se puede usar una interfaz común si tiene sentido semántico:
public interface Figura {
int area();
}
public class Rectangulo implements Figura {
private final int ancho, alto;
public Rectangulo(int ancho, int alto) {
this.ancho = ancho; this.alto = alto;
}
@Override public int area() { return ancho * alto; }
}
public class Cuadrado implements Figura {
private final int lado;
public Cuadrado(int lado) { this.lado = lado; }
@Override public int area() { return lado * lado; }
}
Ambas clases son independientes (cada una con sus propios invariantes) y comparten solo la abstracción Figura. Es más seguro y más fiel a la semántica.
Ejemplo 3: Comportamiento variable — el patrón Strategy
Supongamos que tenemos vehículos que se desplazan de diferentes maneras. Un diseño basado en herencia podría ser:
// Diseño con herencia — rígido
public abstract class Vehiculo {
public abstract void desplazarse();
}
public class Coche extends Vehiculo {
@Override
public void desplazarse() { System.out.println("Ruedo por la carretera"); }
}
public class Barco extends Vehiculo {
@Override
public void desplazarse() { System.out.println("Navego por el agua"); }
}
Funciona bien mientras el comportamiento sea fijo. Pero ¿qué ocurre con un vehículo anfibio que puede rodar o navegar? Con herencia simple no hay solución limpia. Con composición, el comportamiento se convierte en una dependencia que puede cambiar:
// Interfaz de estrategia
public interface ModoDeDesplazamiento {
void desplazarse();
}
// Implementaciones concretas
public class Rodadura implements ModoDeDesplazamiento {
@Override public void desplazarse() { System.out.println("Ruedo por la carretera"); }
}
public class Navegacion implements ModoDeDesplazamiento {
@Override public void desplazarse() { System.out.println("Navego por el agua"); }
}
// La clase Vehiculo delega el comportamiento
public class Vehiculo {
private ModoDeDesplazamiento modo;
public Vehiculo(ModoDeDesplazamiento modo) {
this.modo = modo;
}
public void setModo(ModoDeDesplazamiento modo) {
this.modo = modo; // ← cambiable en tiempo de ejecución
}
public void desplazarse() {
modo.desplazarse();
}
}
Ahora un vehículo anfibio puede cambiar de modo sin necesidad de crear nuevas subclases:
Vehiculo anfibio = new Vehiculo(new Rodadura());
anfibio.desplazarse(); // "Ruedo por la carretera"
anfibio.setModo(new Navegacion());
anfibio.desplazarse(); // "Navego por el agua"
Este es el patrón Strategy descrito por GoF y es un ejemplo paradigmático de composición que resuelve lo que la herencia no puede.
Ejemplo 4: Cuando la herencia SÍ es la elección correcta
La herencia no es mala en sí misma; es una herramienta potente cuando se usa adecuadamente. Es la elección correcta cuando:
- La relación “es-un” es genuina y estable.
- Se satisface el LSP: la subclase puede sustituir a la superclase sin sorpresas.
- La subclase extiende el comportamiento de la superclase sin alterar sus contratos.El ejemplo clásico en los cursos de POO es la jerarquía de figuras geométricas con polimorfismo:
public abstract class Figura {
public abstract double area();
public abstract double perimetro();
public void describir() {
System.out.printf("Área: %.2f, Perímetro: %.2f%n", area(), perimetro());
}
}
public class Circulo extends Figura {
private final double radio;
public Circulo(double radio) { this.radio = radio; }
@Override public double area() { return Math.PI * radio * radio; }
@Override public double perimetro() { return 2 * Math.PI * radio; }
}
public class RectanguloFigura extends Figura {
private final double base, altura;
public RectanguloFigura(double base, double altura) {
this.base = base; this.altura = altura;
}
@Override public double area() { return base * altura; }
@Override public double perimetro() { return 2 * (base + altura); }
}
Aquí la herencia es correcta porque:
- Un
Circuloes unaFiguragenuinamente. - El
Circulopuede sustituir a cualquierFiguraen cualquier contexto (LSP se cumple). - El polimorfismo permite escribir código genérico:
List<Figura> figuras = List.of(new Circulo(5), new RectanguloFigura(4, 3));
for (Figura f : figuras) {
f.describir();
}
Resumen: guía de decisión
¿La relación entre B y A es realmente "B es un A"?
│
├── NO → Usa COMPOSICIÓN
│
└── SÍ → ¿Se cumple el LSP? (¿puede B sustituir a A sin romper nada?)
│
├── NO → Usa COMPOSICIÓN (o rediseña la jerarquía)
│
└── SÍ → ¿A fue A diseñada para ser heredada (documentada, testada)?
│
├── NO → Considera COMPOSICIÓN o habla con el autor de A
│
└── SÍ → HERENCIA es apropiada
Conclusión
La preferencia por la composición sobre la herencia no es una moda ni una regla arbitraria. Es una recomendación avalada por décadas de experiencia colectiva, formulada con rigor por algunos de los autores más influyentes del diseño de software:
- GoF la elevan a principio de diseño fundamental (1994).
- Barbara Liskov proporciona el criterio formal para saber cuándo la herencia es semánticamente válida (1987, 1994).
- Joshua Bloch la convierte en consejo práctico inmediato para programadores Java (2001, 2018).
- Robert C. Martin la integra en el marco SOLID y en su análisis de fragilidad del software (2002).La herencia tiene su lugar: es la herramienta adecuada cuando la relación “es-un” es semánticamente sólida y se satisface el LSP. Fuera de ese contexto, la composición produce diseños más flexibles, más encapsulados y más fáciles de mantener a largo plazo.
Referencias
- Gamma, E., Helm, R., Johnson, R., & Vlissides, J. (1994). Design Patterns: Elements of Reusable Object-Oriented Software. Addison-Wesley.
- Liskov, B. (1987). Data Abstraction and Hierarchy. OOPSLA’87 Keynote.
- Liskov, B., & Wing, J. (1994). A Behavioral Notion of Subtyping. ACM Transactions on Programming Languages and Systems, 16(6), 1811–1841.
- Liskov, B., & Guttag, J. (2001). Program Development in Java: Abstraction, Specification, and Object-Oriented Design. Addison-Wesley.
- Bloch, J. (2018). Effective Java (3ª ed.). Addison-Wesley. [Ítems 18 y 19]
- Martin, R. C. (2002). Agile Software Development: Principles, Patterns, and Practices. Pearson Education.
- Gamma, E. (2004). How to Use Design Patterns [entrevista, Part I]. Artima Developer. https://www.artima.com/articles/how-to-use-design-patterns
- Gamma, E. (2004). Erich Gamma on Flexibility and Reuse [entrevista, Part II]. Artima Developer. https://www.artima.com/articles/erich-gamma-on-flexibility-and-reuse
- Gamma, E. (2004). Design Principles from Design Patterns [entrevista, Part III]. Artima Developer. https://www.artima.com/articles/design-principles-from-design-patterns
Santiago Higuera. 7 de mayo de 2026