Clases abstractas e interfaces: de qué estamos hablando
Cuando diseñamos una jerarquía de clases en Java, en ocasiones necesitamos definir un tipo padre que no tenga sentido instanciar directamente, sino que sirva como modelo para las clases que deriven de él. Java ofrece dos herramientas distintas para esto: las clases abstractas y las interfaces. Aunque a primera vista pueden parecer intercambiables, tienen diferencias importantes que conviene entender bien antes de elegir entre ellas.
Clases abstractas
Una clase abstracta es una clase que no puede instanciarse directamente. Se declara con la palabra clave abstract y puede contener:
- Atributos de instancia (estado).
- Constructores.
- Métodos concretos (con implementación).
- Métodos abstractos (sin implementación), que las subclases están obligadas a implementar.
El ejemplo que ya conoces de clase es la jerarquía de figuras geométricas:
public abstract class Figura {
private String color; // ← atributo de instancia
public Figura(String color) { // ← constructor
this.color = color;
}
public String getColor() { // ← método concreto
return color;
}
public abstract double area(); // ← método abstracto
public abstract double perimetro(); // ← método abstracto
}
Las subclases deben implementar obligatoriamente todos los métodos abstractos:
public class Circulo extends Figura {
private double radio;
public Circulo(String color, double radio) {
super(color);
this.radio = radio;
}
@Override
public double area() {
return Math.PI * radio * radio;
}
@Override
public double perimetro() {
return 2 * Math.PI * radio;
}
}
Si una subclase no implementa todos los métodos abstractos, Java obliga a declararla también como abstract. Hay que tener en cuenta además que, en Java, una clase solo puede extender una única clase padre, sea esta abstracta o concreta. Esta restricción, conocida como herencia simple, tendrá importancia cuando hagamos la comparación con los interfaces.
Interfaces
Un interfaz es una declaración de comportamiento sin implementación. Se declara con la palabra clave interface y en su forma clásica solo puede contener:
- Métodos abstractos (implícitamente son
public abstract). - Constantes (implícitamente son
public static final).
Una clase implementa un interfaz con la palabra clave implements:
public interface Dibujable {
void dibujar(); // ← implícitamente public abstract
}
public interface Redimensionable {
void redimensionar(double factor); // ← implícit. public abstract
}
Una misma clase puede implementar varias interfaces a la vez, lo que no es posible con la herencia de clases:
class Circulo extends Figura implements Dibujable, Redimensionable {
private double radio;
public Circulo(String color, double radio) {
super(color);
this.radio = radio;
}
@Override
public double area() { return Math.PI * radio * radio; }
@Override
public double perimetro() {return 2 * Math.PI * radio; }
@Override
public void dibujar() {
System.out.println("Dibujando círculo");
}
@Override
public void redimensionar(double factor) {
this.radio *= factor;
}
}
📎 Java 8 y los métodos
default: a partir de Java 8, las interfaces pueden incluir métodos con implementación, declarados con la palabra clavedefault. Esto redujo parte de la distancia histórica entre interfaces y clases abstractas. Sin embargo, las interfaces siguen sin poder tener atributos de instancia ni constructores, lo que mantiene vigente la distinción fundamental entre ambas.
La tabla comparativa de partida
| Clase abstracta | Interfaz | |
|---|---|---|
| Instanciación | No se puede instanciar directamente | No se puede instanciar directamente |
| Atributos de instancia | Sí | No |
| Constructores | Sí | No |
| Métodos concretos | Sí | Solo con default (Java 8+) |
| Métodos abstractos | Sí | Sí (todos, por defecto) |
| Herencia/implementación | Una sola clase padre | Múltiples interfaces |
| Relación que modela | “es-un” con estado compartido | Contrato de comportamiento |
Con estas dos herramientas claras, la pregunta es cuándo elegir cada una. Eso es lo que veremos en los siguientes apartados.
Herencia de implementación y herencia de tipos
Aunque son mecanismos distintos, tanto extender una clase abstracta como implementar un interfaz son formas de herencia en Java y es útil distinguirlas por su nombre:
- Herencia de implementación (class inheritance): cuando una clase extiende una clase abstracta (o concreta). La subclase hereda tanto el contrato (los métodos) como la implementación (el código) de la clase padre.
- Herencia de tipos (interface inheritance): cuando una clase implementa un interfaz. La clase hereda únicamente el contrato, sin ninguna implementación.
Ambas formas de herencia comparten una propiedad fundamental: el dynamic dispatch o asociación dinámica. Esto significa que, cuando llamamos a un método a través de una referencia del tipo padre, Java decide en tiempo de ejecución qué implementación ejecutar según el tipo real del objeto. El resultado es el mismo independientemente de si el tipo padre es una clase abstracta o un interfaz:
// Con clase abstracta
Figura f1 = new Circulo("rojo", 5.0);
Figura f2 = new Rectangulo("azul", 4.0, 3.0);
f1.area(); // ejecuta Circulo.area()
f2.area(); // ejecuta Rectangulo.area()
// Con interfaz
Dibujable d1 = new Circulo("rojo", 5.0);
Dibujable d2 = new Rectangulo("azul", 4.0, 3.0);
d1.dibujar(); // ejecuta Circulo.dibujar()
d2.dibujar(); // ejecuta Rectangulo.dibujar()
En ambos casos, el código que llama al método no sabe ni necesita saber qué tipo concreto tiene el objeto. Esa es la esencia del polimorfismo y funciona igual con los dos mecanismos.
Esta equivalencia es importante: la elección entre clase abstracta e interfaz no afecta al polimorfismo. Lo que cambia son las capacidades del tipo padre (si puede tener estado, constructores, lógica compartida) y las restricciones que impone sobre las clases que lo utilizan. Esos son precisamente los criterios que veremos a continuación.
La restricción más importante: herencia simple
Java permite que una clase extienda una sola clase padre. Esto es la herencia simple y se aplica tanto a clases concretas como a clases abstractas. En cambio, una clase puede implementar múltiples interfaces sin ninguna restricción.
Esta asimetría tiene consecuencias prácticas inmediatas. Veamos un ejemplo concreto.
Supongamos que estamos desarrollando un videojuego y tenemos la siguiente jerarquía:
public abstract class Personaje {
protected String nombre;
protected int vida;
public Personaje(String nombre, int vida) {
this.nombre = nombre;
this.vida = vida;
}
public abstract void atacar();
}
Ahora queremos crear un Mago que extienda Personaje. Sin problema:
public class Mago extends Personaje {
public Mago(String nombre) {
super(nombre, 100);
}
@Override
public void atacar() {
System.out.println(nombre + " lanza un hechizo.");
}
}
Pero resulta que en nuestro juego algunos personajes pueden volar y otros pueden nadar. Queremos que el Mago pueda hacer ambas cosas. Si intentamos resolverlo con clases abstractas, el diseño se bloquea:
public abstract class Volador {
public abstract void volar();
}
public abstract class Nadador {
public abstract void nadar();
}
// ¡Esto no compila! Java no permite extender dos clases a la vez.
public class Mago extends Personaje, Volador, Nadador {
...
}
Java no lo permite. Hemos “gastado” la herencia en Personaje, y no podemos extender nada más. Con interfaces, el problema desaparece:
public interface Volador {
void volar();
}
public interface Nadador {
void nadar();
}
// Esto sí compila: una clase padre y los interfaces que necesitemos.
public class Mago extends Personaje implements Volador, Nadador {
public Mago(String nombre) {
super(nombre, 100);
}
@Override
public void atacar() {
System.out.println(nombre + " lanza un hechizo.");
}
@Override
public void volar() {
System.out.println(nombre + " vuela sobre las nubes.");
}
@Override
public void nadar() {
System.out.println(nombre + " nada bajo el agua.");
}
}
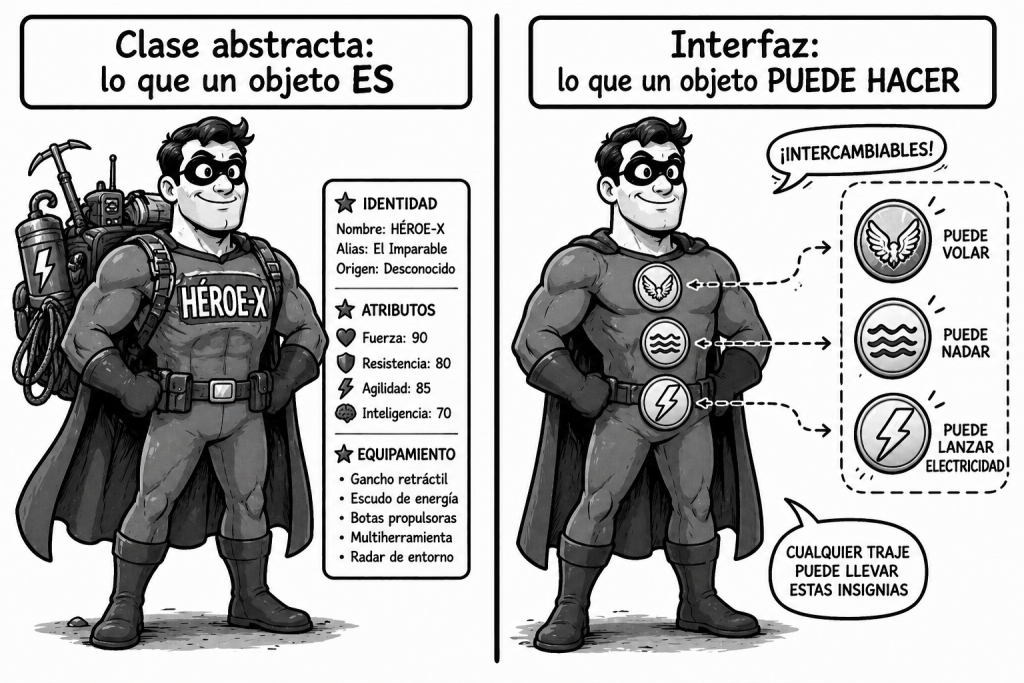
El patrón es claro: la clase abstracta define lo que un objeto es (un Personaje, con su estado y su lógica común), mientras que los interfaces definen lo que un objeto puede hacer (volar, nadar, dibujarse, serializarse, compararse). Esta distinción es la clave para entender cuándo usar cada herramienta.
Cuándo sí tiene sentido una clase abstracta
La clase abstracta es la herramienta adecuada cuando el tipo padre necesita algo más que declarar un contrato:
- Cuando tiene un estado propio que compartir con las subclases.
- Cuando hay un constructor con una lógica común que no tiene sentido duplicar.
- Cuando se quiere que las clases derivadas sigan los pasos de un algoritmo que deben ejecutarse siempre en el mismo orden.
Cuando hay estado compartido entre las subclases
Si varias subclases necesitan los mismos atributos, lo natural es declararlos en la clase abstracta y dejar que las subclases los hereden. Un interfaz no puede hacer esto porque no admite atributos de instancia.
En el ejemplo de figuras geométricas que ya conoces, todas las figuras tienen un color. Declararlo en la clase abstracta evita repetirlo en cada subclase:
public abstract class Figura {
private String color;
public Figura(String color) {
this.color = color;
}
public String getColor() {
return color;
}
public abstract double area();
public abstract double perimetro();
}
Si Figura fuera un interfaz, cada subclase tendría que gestionar el color por su cuenta, duplicando código innecesariamente.
Cuando hay un constructor con lógica común
Relacionado con lo anterior: si la inicialización de los atributos compartidos requiere alguna lógica, como validaciones, transformaciones o inicializaciones complejas, esa lógica puede centralizarse en el constructor de la clase abstracta y reutilizarse mediante super() en todas las subclases.
public abstract class Figura {
private String color;
public Figura(String color) {
if (color == null || color.isEmpty()) {
throw new IllegalArgumentException(
"El color no puede estar vacío.");
}
this.color = color;
}
}
Todas las subclases que llamen a super(color) se benefician automáticamente de esa validación sin tener que repetirla.
Cuando se quiere definir un algoritmo con pasos fijos
Este es el caso de uso más característico de las clases abstractas: el patrón Template Method. La idea es que la clase abstracta define la estructura de un algoritmo en un método concreto, pero delega algunos de sus pasos a las subclases mediante métodos abstractos.
Imaginemos que queremos modelar el proceso de preparar una bebida caliente. Los pasos son siempre los mismos: hervir agua, preparar la bebida, servir. Sin embargo, el paso de preparar la bebida varía según si es té o café:
public abstract class BebidaCaliente {
private String nombre;
public BebidaCaliente(String nombre) {
this.nombre = nombre;
}
// Método plantilla: define el algoritmo completo
public final void preparar() {
hervirAgua();
prepararBebida(); // ← variable, lo implementa cada subclase
servir();
}
private void hervirAgua() {
System.out.println("Hirviendo agua...");
}
protected abstract void prepararBebida(); // ← cada subclase
private void servir() {
System.out.println("Sirviendo " + nombre + ".");
}
}
public class Cafe extends BebidaCaliente {
public Cafe() {
super("café");
}
@Override
protected void prepararBebida() {
System.out.println("Añadiendo café molido y filtrando.");
}
}
public class Te extends BebidaCaliente {
public Te() {
super("té");
}
@Override
protected void prepararBebida() {
System.out.println("Añadiendo la bolsita de té y dejando reposar.");
}
}
El uso sería:
BebidaCaliente bebida = new Cafe();
bebida.preparar();
Salida:
Hirviendo agua...
Añadiendo café molido y filtrando.
Sirviendo café.
Un interfaz no puede implementar este patrón en su forma clásica, porque no puede tener un método concreto que llame a métodos abstractos propios con garantía de orden y control. La clase abstracta es aquí la única herramienta adecuada.
Cuándo el interfaz es claramente superior
El interfaz es la herramienta adecuada cuando lo que queremos definir es un contrato de comportamiento sin imponer ninguna jerarquía ni compartir estado. Hay tres situaciones en las que el interfaz gana claramente a la clase abstracta:
- Cuando una clase necesita cumplir varios contratos a la vez.
- Cuando queremos añadir comportamiento a clases ya existentes.
- Cuando queremos definir tipos para composición.
Cuando una clase necesita cumplir varios contratos a la vez
Ya lo vimos en la sección anterior: Java solo permite extender una clase, pero permite implementar múltiples interfaces. Siempre que una clase necesite comprometerse con más de un comportamiento independiente, el interfaz es la única opción viable.
Este es el caso más frecuente en la práctica y el argumento más inmediato para preferir interfaces a clases abstractas cuando no hay estado que compartir.
Cuando queremos añadir comportamiento a clases ya existentes
Supongamos que tenemos una clase Factura que ya extiende otra clase y no podemos cambiar su jerarquía. Si queremos que Factura sea comparable, para poder ordenar facturas por importe, por ejemplo, basta con implementar el interfaz Comparable:
public class Factura extends Documento implements Comparable<Factura> {
private double importe;
public Factura(double importe) {
this.importe = importe;
}
@Override
public int compareTo(Factura otra) {
return Double.compare(this.importe, otra.importe);
}
}
Con una clase abstracta esto sería imposible: Factura ya tiene su clase padre y no puede tener otra. El interfaz permite añadir capacidades a una clase existente sin tocar su jerarquía: encajar un interfaz en una clase que ya existe es sencillo; encajar una clase abstracta en una jerarquía ya establecida es, en general, imposible. A este mecanismo, Bloch lo llamó retroadaptación (retrofitting).
Cuando queremos definir tipos para composición
En ocasiones una clase no necesita ser algo, sino poder hacer algo. Y ese “poder hacer” puede combinarse con otras capacidades de forma flexible. En estos casos, el interfaz es la herramienta natural.
Imaginemos que estamos modelando vehículos que pueden desplazarse de diferentes maneras. Podríamos definir el comportamiento de desplazamiento como un interfaz:
public interface ModoDeDesplazamiento {
void desplazarse();
}
public class Rodadura implements ModoDeDesplazamiento {
@Override
public void desplazarse() {
System.out.println("Rodando por la carretera.");
}
}
public class Navegacion implements ModoDeDesplazamiento {
@Override
public void desplazarse() {
System.out.println("Navegando por el agua.");
}
}
public class Vehiculo {
private ModoDeDesplazamiento modo;
public Vehiculo(ModoDeDesplazamiento modo) {
this.modo = modo;
}
public void setModo(ModoDeDesplazamiento modo) {
this.modo = modo;
}
public void desplazarse() {
modo.desplazarse();
}
}
El Vehiculo no sabe ni le importa si rueda o navega: solo conoce el interfaz ModoDeDesplazamiento y delega en él. Esto permite cambiar el comportamiento en tiempo de ejecución sin modificar la clase Vehiculo:
Vehiculo anfibio = new Vehiculo(new Rodadura());
anfibio.desplazarse(); // Rodando por la carretera.
anfibio.setModo(new Navegacion());
anfibio.desplazarse(); // Navegando por el agua.
ModoDeDesplazamiento podría haber sido una clase abstracta, pero entonces Rodadura y Navegacion habrían gastado su única herencia en ella, bloqueando cualquier otra jerarquía. Como interfaz, no impone ninguna restricción y el diseño queda abierto a cualquier combinación futura.
📎 La regla práctica de Bloch: en Effective Java, Joshua Bloch resume la preferencia por los interfaces con una pregunta sencilla: ¿necesita el tipo padre tener estado o lógica compartida? Si la respuesta es no, usa un interfaz. Si la respuesta es sí, considera una clase abstracta, o mejor aún, combina ambas herramientas con el patrón de implementación esquelética, que se comenta más adelante y seguramente desarrollaremos en un artículo posterior.
📎 Patrón Strategy: el diseño utilizado en el ejemplo tiene nombre propio en la literatura del software. Se llama patrón Strategy y es uno de los 23 patrones del libro de la Banda de los Cuatro (GoF). Lo reconocerás siempre por sus tres elementos: un interfaz que define el comportamiento intercambiable (la estrategia), varias clases que lo implementan (las estrategias concretas) y una clase que las usa delegando en ellas (el contexto). En nuestro ejemplo,
ModoDeDesplazamientoes la estrategia,RodadurayNavegacionson las estrategias concretas, yVehiculoes el contexto.
Guía de decisión
¿El tipo padre necesita atributos de instancia o constructores con lógica común?
│
├── SÍ → Usa una CLASE ABSTRACTA
│ │
│ └── ¿Además necesitas cumplir varios contratos?
│ │
│ ├── SÍ → CLASE ABSTRACTA + INTERFACES adicionales
│ │
│ └── NO → Usa solo CLASE ABSTRACTA
│
└── NO → ¿Necesitas un algoritmo con pasos fijos y variables?
│
├── SÍ → Usa una CLASE ABSTRACTA (patrón Template Method)
│
└── NO → Usa un INTERFAZ
│
└── ¿Implementación con partes comunes reutilizables?
│
├── SÍ → INTERFAZ + CLASE ABSTRACTA esquelética
│
└── NO → Usa solo el INTERFAZ
📎 Nota: la combinación INTERFAZ + CLASE ABSTRACTA esquelética es un patrón especialmente potente que merece explicación detallada. Lo desarrollaremos en un artículo posterior.
📎 El patrón en la API de Java: si estás estudiando las colecciones de Java, ya has visto este patrón en acción.
Listes el interfaz que define el contrato,AbstractListes la clase abstracta esquelética que implementa la parte común yArrayListes la implementación concreta. Lo mismo ocurre conMapyAbstractMap, o conSetyAbstractSet. Es uno de los patrones de diseño más utilizados en la propia API de Java.
Conclusión
Las clases abstractas y los interfaces son dos herramientas distintas para un problema similar: definir un tipo padre que sirva de modelo para otras clases. Elegir bien entre ellas no es una cuestión de estilo sino de diseño.
La regla general es sencilla: usa una clase abstracta cuando el tipo padre necesite compartir estado o lógica común con sus subclases, y usa un interfaz cuando solo necesites definir un contrato de comportamiento. En la práctica, ambas herramientas se complementan con frecuencia: el interfaz define el tipo y la clase abstracta proporciona una implementación parcial reutilizable.
Hay una pregunta que conviene hacerse siempre antes de decidir: ¿estoy definiendo lo que un objeto es, o lo que un objeto puede hacer? Si la respuesta es lo primero, la clase abstracta es probablemente la herramienta adecuada. Si es lo segundo, el interfaz es la elección natural.
Una vez clara la diferencia entre estas dos herramientas, el siguiente paso es preguntarse cuándo conviene usar herencia, sea de clase abstracta o de interfaz y cuándo es mejor usar composición. Esa es precisamente la pregunta que abordaremos en el próximo artículo.
Santiago Higuera. 30 de abril de 2026.