Hábitos que distinguen a un programador que empieza de uno que madura
Para quienes ya saben escribir código, pero aún no saben pensar en código.

Cuando empiezas a programar, la batalla es contra la sintaxis. ¿Va el punto y coma aquí o allá? ¿Por qué me falla la compilación? ¿Qué significa ese NullPointerException?
Pero los programadores más experimentados saben que la dificultad no está en la sintaxis, sino en el diseño correcto de las aplicaciones. La mayoría de los problemas al desarrollar software no son problemas de codificación, son problemas de pensar. Los errores más silenciosos y peligrosos son los errores de diseño.
Un programa puede compilar perfectamente, ejecutarse sin fallos y aun así estar fundamentalmente mal construido. Son los errores que no te avisa el compilador, pero que te perseguirán semanas después cuando quieras añadir una funcionalidad, corregir un fallo o simplemente releer tu propio código.
Este artículo muestra una serie de consejos para mejorar tu técnica como programador y recoge algunos de los errores más frecuentes que cometen los programadores nóveles, con ejemplos concretos en C y Java.
1. Dibuja antes de picar tecla
Antes de escribir una sola línea de código, coge un papel y un bolígrafo.
Suena anticuado. Puede que incluso innecesario. Pero es uno de los hábitos que más diferencian a un programador experimentado de uno que acaba de empezar.
El programador novel abre el editor nada más leer el enunciado. El resultado es casi siempre el mismo: a mitad del programa descubre que su planteamiento inicial era erróneo, que necesita una variable que no había previsto o que las funciones que escribió primero no encajan con las que necesita ahora. Borra, reescribe, da vueltas. El editor se convierte en el lugar donde se piensa, no donde se construye.
Utilizar esquemas visuales proporciona algunas ventajas durante la fase de diseño:
- La estructura queda más clara antes de empezar a teclear.
- Se identifican con mayor facilidad los casos límite.
- Se facilita la comunicación entre miembros del equipo.
- El papel es más rápido que el compilador para descartar ideas malas.
¿Qué se dibuja exactamente?
Depende del problema, pero hay tres herramientas básicas que cubren la mayoría de los casos:
Diagramas de flujo para los algoritmos. Antes de escribir un bucle o una cadena de condiciones, dibuja las cajas y las flechas. ¿Por dónde entra el flujo? ¿Qué condición lo bifurca? ¿Dónde termina? Un diagrama de flujo toscamente trazado en un minuto te muestra los casos que no habías considerado.

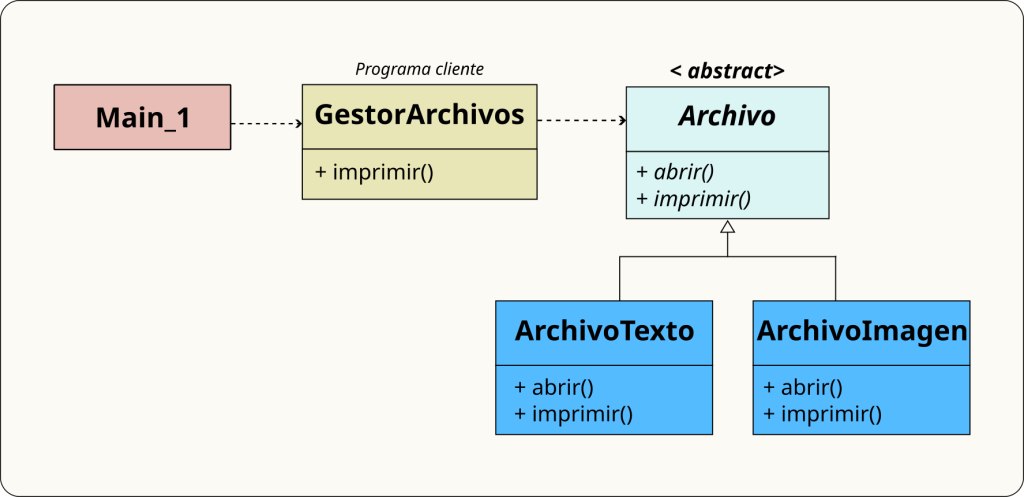
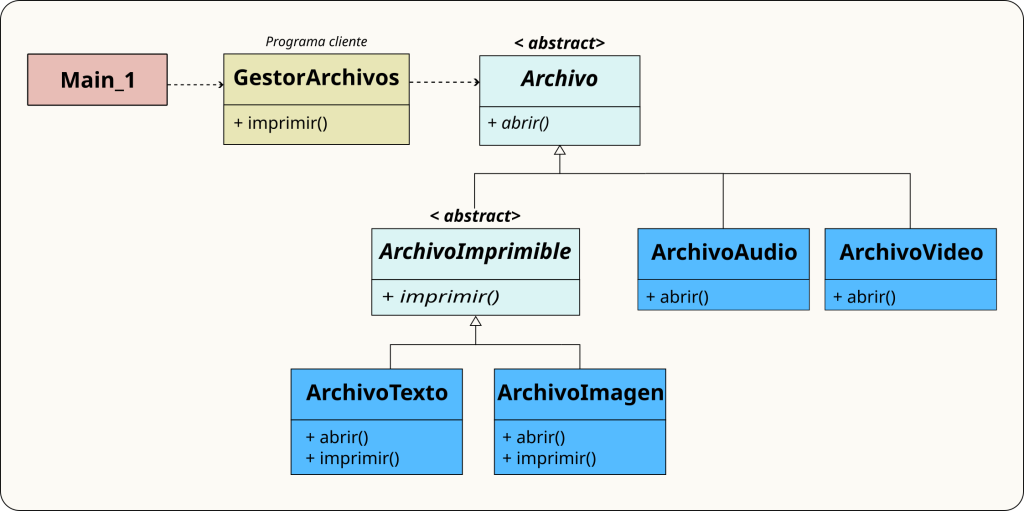
Bocetos de estructuras de datos. En C, antes de declarar un struct, dibuja los campos que necesitas y las relaciones entre ellos. En Java, antes de escribir una clase, dibuja un rectángulo con su nombre, sus atributos y sus métodos principales. No hace falta que sea UML formal: basta con que seas capaz de responder a la pregunta ¿qué sabe esta clase de sí misma?

Pseudocódigo. A medio camino entre el lenguaje natural y el código real. No tiene sintaxis estricta; su único objetivo es fijar la lógica antes de preocuparte por los detalles del lenguaje.

Escribir esto en papel lleva dos minutos. Detectar que el criterio de aprobado debe ser un parámetro (¿y si en otra asignatura es 4,5?) lleva otros treinta segundos. Hacer ese mismo cambio después de haber escrito cincuenta líneas de código puede llevarte media hora.
La regla práctica
No es necesario dibujar todo siempre. Para una función de tres líneas, el papel sobra. Pero cuando un problema te parezca medianamente complejo o cuando tengas dudas de por dónde empezar, esa es exactamente la señal para apartar el teclado y coger el bolígrafo.
Herramientas para dibujar esquemas
El dibujo inicial de los esquemas se hace mejor a mano. Es más rápido y, por la forma de funcionar nuestro cerebro, dibujarlos a mano permite fijar mejor las ideas en la memoria. No obstante, cuando los esquemas pasan a ser definitivos y decides guardarlos en el ordenador o incluirlos en un documento, es útil utilizar alguna herramienta de diseño. Yo utilizo InkScape y Draw.io. Se trata de herramientas libres y gratuitas que funcionan muy bien. InkScape tiene una curva de aprendizaje más pronunciada, pero también permite hacer muchas más cosas. Todos los esquemas que ves en los artículos de Matemata están hechos con InkScape. También me han hablado de Excalidraw, que es una herramienta web, pero nunca la he probado.
Más allá del dibujo: planificar antes de programar
Dibujar es la forma concreta de una habilidad más amplia: planificar antes de programar. Imagina a un pintor que, nada más recibir el encargo, agarra el pincel y empieza a pintar sin haber visto cómo es la habitación. Es probable que se quede sin pintura a mitad, que no le cuadren las esquinas o que tenga que repintar tres veces lo que hizo el primer día.
Antes de escribir la primera línea, dedica aunque sea cinco minutos a responder:
- ¿Qué tiene que hacer exactamente este programa o función?
- ¿Qué datos recibe y qué datos devuelve?
- ¿Hay casos especiales que deba contemplar desde el principio?
La respuesta no tiene que ser perfecta. Solo tiene que existir.
2. Nombres que no dicen nada
Este es quizás el hábito más fácil de mejorar y con más impacto inmediato. Compara estos dos fragmentos en C:
/* Versión con nombres pobres */
int f(int a, int b) {
int r = 0;
for (int i = 0; i < b; i++) {
r += a;
}
return r;
}
/* Versión con nombres descriptivos */
int multiplicar(int factor, int veces) {
int resultado = 0;
for (int i = 0; i < veces; i++) {
resultado += factor;
}
return resultado;
}
El código es idéntico. Pero el segundo se entiende sin necesidad de ejecutarlo mentalmente.
La regla práctica es esta: el nombre debe responder a la pregunta “¿qué es esto?” sin necesitar mirar el resto del código. Si tienes que leer el cuerpo de una función para entender qué devuelve, el nombre ha fallado.
Esto aplica igualmente en Java:
// Mal: ¿qué hace este método? ¿qué es "d"?
public boolean chk(int d) {
return d >= 18;
}
// Bien: queda claro sin leer el cuerpo
public boolean esMayorDeEdad(int edad) {
return edad >= 18;
}
Algunos consejos concretos:
- Variables: sustantivos o frases nominales (
precio,nombreUsuario,listaAlumnos). - Funciones/métodos: verbos o frases verbales (
calcularMedia,obtenerNombre,esPrimo). - Booleanos: que puedan leerse como una afirmación (
estaVacio,tienePermiso,esValido). - Evita abreviaturas salvo las universalmente conocidas (
i,jen bucles;msgpara mensaje;lenpara longitud).
La misma exigencia de claridad que aplicamos a los nombres se extiende a todo el código: la tentación de escribir expresiones “inteligentes” es otra forma del mismo problema.
3. Intentar ser demasiado “ingenioso”
Uno de los errores más frecuentes en programadores principiantes consiste en intentar escribir código “impresionante” en lugar de código claro.
Cuando alguien empieza a sentirse cómodo con un lenguaje de programación, es habitual que aparezca la tentación de utilizar expresiones cada vez más compactas, operadores encadenados, trucos sintácticos o construcciones difíciles de entender. El programador tiene la sensación de estar escribiendo código más avanzado o más profesional, cuando en realidad muchas veces está haciendo justo lo contrario: crear software más difícil de comprender y mantener.
Por ejemplo, algunos principiantes intentan condensar demasiada lógica en una sola línea:
if ((x > 0 && y < 10) || (z != 0 && (a+b*c-d/e) > 50 && !error)) {
Aunque esta instrucción puede ser correcta, entender exactamente qué está ocurriendo requiere un esfuerzo innecesario. Un código más claro suele ser preferible:
boolean coordenadas_validas = (x > 0 && y < 10);
boolean calculo_correcto = (z != 0 && (a + b * c - d / e) > 50);
if (coordenadas_validas || (calculo_correcto && !error)) {
La segunda versión ocupa más líneas, pero resulta mucho más fácil de leer, revisar y modificar.
Otro caso típico aparece cuando se utilizan operadores de incremento o asignaciones complejas dentro de expresiones:
vector[i++] = datos[++j] + --k;
Aunque un programador experimentado podría analizar esta línea, su comportamiento no es evidente a simple vista. Además, expresiones de este tipo suelen ser fuente de errores difíciles de detectar.
En general, cuando una línea de código necesita varios segundos de análisis para comprenderse, probablemente debería reescribirse de forma más sencilla.
Muchos programadores noveles creen que el buen código es el más corto o el más inteligente”. Sin embargo, en desarrollo profesional ocurre exactamente lo contrario: se valora especialmente el código claro y mantenible.
Un programa se escribe una vez, pero se lee y se modifica muchas veces. Además, en numerosos casos, quien tendrá que mantener el código en el futuro será otra persona… o incluso el propio autor varios meses después, cuando ya haya olvidado cómo funcionaba aquella expresión tan ingeniosa.
Por ello, una de las recomendaciones más importantes para cualquier programador es priorizar siempre la claridad sobre la brillantez, la simplicidad sobre la complejidad y la legibilidad sobre el ahorro de líneas. Un código sencillo no es señal de poca experiencia. Muy al contrario: escribir soluciones claras y fáciles de entender suele requerir más madurez y más disciplina que escribir código innecesariamente complicado.
De hecho, muchos programadores experimentados siguen una regla informal muy útil:
“Si una solución parece demasiado inteligente, probablemente no sea una buena solución.”
4. Una función, una responsabilidad
Uno de los principios más importantes en programación es que cada parte del código, cada función, cada método, cada clase, debe tener una responsabilidad clara y acotada. Cuando ese principio se ignora, el código crece sin control y acaba siendo imposible de entender o modificar.
El caso más extremo es el de escribir todo el programa dentro del main(). Al principio puede parecer cómodo, especialmente en programas pequeños. Sin embargo, a medida que el programa crece, el main() termina convirtiéndose en un bloque enorme donde se mezclan todas las tareas: lectura de datos, validaciones, cálculos, menús, impresión de resultados, tratamiento de errores…
El resultado suele ser un código difícil de leer y todavía más difícil de mantener. Localizar un error es complicado. Reutilizar una parte del código, casi imposible. Modificar algo sin romper otra cosa, un riesgo constante.
Una buena señal de que un programa está bien estructurado es que el main() sea relativamente corto y actúe únicamente como coordinador general, delegando el trabajo real en funciones más pequeñas y especializadas.
Ahora bien, dividir el código en funciones no es suficiente si cada función sigue haciéndolo todo. Una función no es un cajón de sastre. Si su descripción incluye la palabra “y”, probablemente hace demasiado.
Imagina que alguien te pide en un restaurante: “Toma nota del pedido, ve a la cocina, cocina el plato, tráelo a la mesa y después cobra al cliente.” Eso no es un camarero, es una persona haciendo cinco trabajos a la vez. Si algo falla, no sabes en cuál de los cinco pasos ocurrió el problema.
El mismo principio aplica a las funciones. Una función debería hacer una sola cosa, y hacerla bien:
/* Mal: esta función hace tres cosas a la vez */
void procesarAlumnos(Alumno* lista, int n) {
/* Lee datos por teclado */
for (int i = 0; i < n; i++) {
printf("Nombre: ");
scanf("%49s", lista[i].nombre);
printf("Nota: ");
scanf("%f", &lista[i].nota);
}
/* Calcula la media */
float suma = 0;
for (int i = 0; i < n; i++) {
suma += lista[i].nota;
}
float media = suma / n;
/* Imprime el resultado */
printf("Media de la clase: %.2f\n", media);
}
/* Bien: cada función tiene una responsabilidad */
void leerAlumnos(Alumno* lista, int n);
float calcularMedia(const Alumno* lista, int n);
void imprimirMedia(float media);
Un caso especialmente frecuente de esta mezcla de responsabilidades es combinar el cálculo con la presentación. Una función encargada de calcular un resultado no debería imprimir mensajes por pantalla: su responsabilidad debería limitarse únicamente al cálculo.
// Mal: calcula y muestra a la vez
public static void calcularPrecioFinal(double precio, double iva) {
double resultado = precio + precio * iva / 100.0;
System.out.println("El precio final es: " + resultado);
}
// Bien: calcula y devuelve; mostrar es tarea de quien llama
public static double calcularPrecioFinal(double precio, double iva) {
return precio + precio * iva / 100.0;
}
De esta forma, la función de cálculo puede reutilizarse fácilmente en otros contextos: una interfaz gráfica, una aplicación web o incluso otro programa distinto. Separar responsabilidades hace que el software sea más claro, más reutilizable y más sencillo de mantener. Aunque en programas pequeños esta separación pueda parecer innecesaria, en proyectos medianos o grandes se vuelve fundamental.
5. Copiar y pegar: el camino fácil hacia el desastre
Tienes un fragmento de código que funciona. Lo necesitas en otro sitio. La tentación es copiar, pegar y listo.
El problema viene cuando ese código tiene un fallo, o cuando cambian los requisitos. De repente tienes que recordar en cuántos sitios lo pegaste y arreglarlo en todos. Invariablemente, te olvidarás de uno.
Este principio se conoce como DRY: Don’t Repeat Yourself (No te repitas).
Ejemplo en Java:
// Mal: la misma lógica de validación duplicada
public void registrarUsuario(String nombre, int edad) {
if (nombre == null || nombre.isBlank()) {
throw new IllegalArgumentException("Nombre no válido");
}
if (edad < 0 || edad > 150) {
throw new IllegalArgumentException("Edad no válida");
}
// ...
}
public void actualizarUsuario(String nombre, int edad) {
if (nombre == null || nombre.isBlank()) {
throw new IllegalArgumentException("Nombre no válido");
}
if (edad < 0 || edad > 150) {
throw new IllegalArgumentException("Edad no válida");
}
// ...
}
// Bien: la validación vive en un solo lugar
private void validarDatos(String nombre, int edad) {
if (nombre == null || nombre.isBlank()) {
throw new IllegalArgumentException("Nombre no válido");
}
if (edad < 0 || edad > 150) {
throw new IllegalArgumentException("Edad no válida");
}
}
public void registrarUsuario(String nombre, int edad) {
validarDatos(nombre, edad);
// ...
}
public void actualizarUsuario(String nombre, int edad) {
validarDatos(nombre, edad);
// ...
}
Cuando los criterios de validación cambien (y cambiarán), solo hay un lugar donde tocar.
6. Ignorar los casos límite
Un error habitual es pensar: “si compila, ya está“. Un programa que solo funciona con datos perfectos no funciona.
El programador novel suele probar su código con casos “normales”: una lista con varios elementos, una cadena con contenido, un número positivo. Pero los programas reales reciben datos imperfectos: listas vacías, cadenas nulas, números negativos, ficheros inexistentes.
Antes de dar por terminada una función, pregúntate:
- ¿Qué pasa si la lista está vacía?
- ¿Qué pasa si el puntero es
NULL(en C) o el objeto esnull(en Java)? - ¿Qué pasa si el número es negativo, cero, o muy grande?
- ¿Qué pasa si el usuario no introduce nada?
Ejemplo en C:
/* Mal: se rompe si lista es NULL o n es 0 */
float calcularMedia(float* lista, int n) {
float suma = 0;
for (int i = 0; i < n; i++) {
suma += lista[i];
}
return suma / n; /* División por cero si n == 0 */
}
/* Bien: maneja los casos problemáticos */
float calcularMedia(float* lista, int n) {
if (lista == NULL || n <= 0) {
return 0.0f; /* O señalizar el error de otra forma */
}
float suma = 0;
for (int i = 0; i < n; i++) {
suma += lista[i];
}
return suma / n;
}
El código robusto no es el que funciona cuando todo va bien. Es el que no se rompe cuando algo va mal. Los errores suelen aparecer en los casos que no pensamos.
7. Comentar el “qué” en lugar del “por qué”
Los comentarios son valiosos, pero hay una trampa frecuente: comentar lo que el código ya dice por sí solo.
// Mal: el comentario no añade ninguna información
i++; // Incrementa i en 1
// Mal: describe el "qué", que ya es evidente
if (edad >= 18) { // Si la edad es mayor o igual a 18
// ...
}
Un comentario útil explica por qué el código hace lo que hace, especialmente cuando la razón no es obvia:
// Bien: explica una decisión no evidente
// La edad legal varía por país; usamos 18 como mínimo internacional
if (edad >= 18) {
// ...
}
// Bien: advierte de una trampa conocida
// Nota: indexOf devuelve -1 si no encuentra el carácter,
// por eso comprobamos >= 0 y no > 0
if (linea.indexOf(':') >= 0) {
// ...
}
Una buena guía práctica: si tienes que escribir un comentario para explicar qué hace una línea de código, considera si sería mejor reescribir esa línea para que se explique sola (con un mejor nombre, extrayendo una función, etc.).
Muchos principiantes programan como si el código fuese a ejecutarse una sola vez. Pero el verdadero coste del software suele estar en modificar, ampliar y corregir.
El código no se escribe para el ordenador; se escribe para futuros humanos.
8. Optimizar antes de tiempo
“La optimización prematura es la raíz de todos los males.” — Donald Knuth
El programador novel a veces se preocupa por la eficiencia antes de tener un programa que funcione correctamente. Decide usar estructuras de datos complejas, evitar llamadas a funciones “por el coste”, o reescribir bucles en formas rebuscadas para que sean “más rápidos”.
El resultado casi siempre es código difícil de leer, difícil de depurar y que además no es significativamente más rápido en la práctica.
El orden correcto es:
- Haz que funcione. Un programa correcto y lento es infinitamente mejor que uno rápido e incorrecto.
- Haz que sea claro. El código que se entiende es el código que se puede mantener.
- Haz que sea rápido, pero solo si hay una necesidad real y medida.
Los ordenadores modernos son extraordinariamente rápidos. La mayoría de los programas que escribirás en tu vida no tienen un problema de rendimiento. Y cuando lo tengan, las herramientas de profiling te dirán exactamente dónde está el cuello de botella, que casi nunca es donde imaginas.
9. No saber cuándo parar de añadir
Hay un fenómeno conocido como gold plating (chapado en oro): añadir funcionalidades que nadie ha pedido porque “quedan bien” o “pueden ser útiles algún día”.
El problema es que cada línea de código es código que hay que mantener, depurar y entender. El mejor código es, con frecuencia, el que no existe.
Cuando estés tentado de añadir algo extra, pregúntate: ¿Lo necesita el programa ahora mismo o simplemente me parece interesante?
Empieza por lo mínimo que resuelve el problema. Añade después si es necesario. Este principio tiene nombre: YAGNI (You Ain’t Gonna Need It, no lo vas a necesitar).
10. No releer tu propio código
El código recién escrito parece perfecto. Pero el código que relees al día siguiente, con la mente descansada, revela cosas que no veías antes.
Desarrolla el hábito de revisar tu propio código antes de darlo por terminado. Léelo como si fuera de otra persona. Pregúntate:
- ¿Entiendo este fragmento sin contexto adicional?
- ¿Hay algo que podría simplificarse?
- ¿He manejado todos los casos posibles?
Y, cuando sea posible, pide a alguien más que lo lea. Una mirada externa detecta problemas que el autor no puede ver porque está demasiado familiarizado con el código.
Conclusión
Aprender sintaxis es relativamente rápido. Aprender a diseñar software claro, mantenible y robusto lleva mucho más tiempo. La diferencia entre un programador novel y uno con experiencia no está solo en conocer más funciones de la librería estándar o dominar más algoritmos. Está en los hábitos de trabajo: en dibujar antes de codificar, en elegir nombres cuidadosamente, en mantener las funciones pequeñas, en anticipar los fallos.
Estos hábitos no se aprenden leyendo un artículo, sino practicándolos conscientemente hasta que se vuelven naturales. Pero el primer paso es saber que existen.
La próxima vez que vayas a escribir una función, detente un segundo. Coge el bolígrafo. Dibuja lo que quieres construir. Esos segundos se convierten, con el tiempo, en horas de depuración ahorradas.
Este artículo forma parte de una serie de materiales didácticos para estudiantes de Programación I y Programación II en la ETSIST-UPM.
Santiago Higuera. 21 de mayo de 2026.