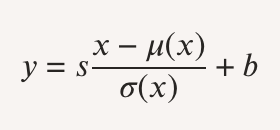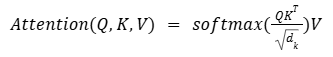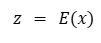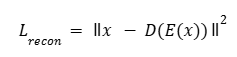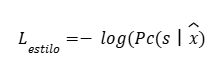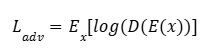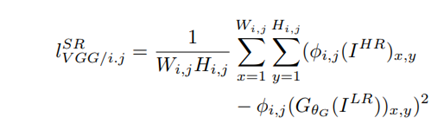Alejandro Cuevas · Iria Lozano · Javier Saguar — PASD, UPM
Introducción
El diagnóstico de tumores cerebrales mediante resonancia magnética (RM) es una tarea clínica de alta complejidad que exige interpretar simultáneamente múltiples secuencias de imagen. Los gliomas, el tipo de tumor cerebral primario más frecuente, presentan subregiones con morfología e intensidad de señal muy distintas según la modalidad empleada. Sin embargo, el etiquetado manual por parte de radiólogos expertos es costoso, lento y escaso, lo que limita la disponibilidad de datos etiquetados para entrenar modelos supervisados.
El aprendizaje contrastivo ofrece una solución natural: aprender representaciones ricas del espacio latente usando únicamente datos no etiquetados, para luego transferirlas a tareas clínicas con muy pocos ejemplos supervisados. La clave está en que en lugar de decirle al modelo qué es cada imagen, le enseñamos qué imágenes son similares entre sí.
Estado del arte
El aprendizaje contrastivo fue formalizado por Chen et al. en SimCLR [1], demostrando que maximizar la similitud entre vistas aumentadas del mismo dato —y minimizarla entre datos distintos— permite aprender representaciones de calidad comparable a métodos supervisados. Posteriormente, He et al. propusieron MoCo [2], introduciendo una cola de memoria que hace el entrenamiento más eficiente con batches pequeños. Más recientemente, VICReg [3] eliminó la necesidad de pares negativos mediante regularización de varianza, invarianza y covarianza.
En imagen médica, Azizi et al. [8] demostraron que modelos preentrenados con aprendizaje autosupervisado superan a los entrenados supervisadamente en clasificación médica con datos limitados. Chaitanya et al. [9] extendieron el aprendizaje contrastivo a segmentación médica con anotaciones parciales. El dataset BRATS [4][5] se ha consolidado como benchmark estándar para segmentación y clasificación de gliomas, con cuatro modalidades complementarias que capturan distintas propiedades del tejido tumoral.
Fundamentos matemáticos
1. Normalización Z-score
Para la estandarización de datos, aplicamos el z-score canal a canal sobre cada corte axial. Dado un valor individual x:
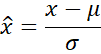
(1) Donde µ es la media del canal, σ su desviación estándar y la puntuación estandar
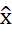
Esta transformación garantiza que cada modalidad (FLAIR, T1w, T1gd, T2w) contribuya
por igual al aprendizaje, independientemente de su rango de intensidad original.
2. Similitud coseno
Para medir el parecido entre representaciones en el espacio latente usamos la similitud coseno, que es robusta frente a cambios de brillo o contraste propios de la RM:
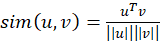
(2) A diferencia de la distancia euclídea, la similitud coseno se centra únicamente en la dirección del vector, ignorando su magnitud.
3. NT-Xent Loss
Para el pre-entrenamiento, implementamos la función de pérdida NT-Xent (Normalized Temperature-scaled Cross Entropy). Dado un par positivo de representaciones (zi, zj) provenientes de la misma imagen, la pérdida se define:
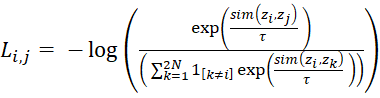
(3) Donde:
– (zi, zj) Son los vectores de representación (embeddings) de dos versiones aumentadas de la misma imagen (par positivo).
– donde τ = 0,5 es el parámetro de temperatura y N el tamaño de batch. La temperatura controla la “dureza” de la distribución: valores bajos hacen el entrenamiento más selectivo, penalizando más los negativos difíciles.
4. Coeficiente de silueta
Para evaluar la calidad del clustering en el espacio latente sin usar etiquetas, empleamos el coeficiente de silueta. Dado un punto i:
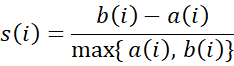
(4) Donde a(i) es la distancia media entre i y los demás puntos de su mismo cluster (cohesión), y b(i) la distancia media mínima al cluster más cercano (separación). Valores próximos a 1 indican clusters bien separados.
Durante el preentrenamiento contrastivo el modelo aprende sin etiquetas. El coefi-
-ciente de silueta es la única forma de evaluar si el encoder ha aprendido estructura
discriminativa de forma no supervisada: si los cortes con y sin tumor forman gru-
-pos naturalmente separados en el espacio latente, el aprendizaje contrastivo ha sido
efectivo.
Materiales
1. Dataset BRATS
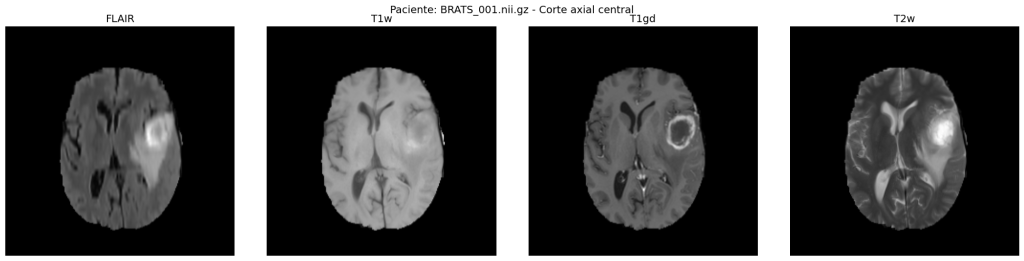
El dataset BRATS (Brain Tumour Segmentation Challenge) [4, 5] contiene 484 pacientes con gliomas en formato NIfTI, con volúmenes de dimensiones 240 × 240 ×155 vóxeles y cuatro modalidades de RM por paciente:
– FLAIR: elimina la señal del líquido cefalorraquídeo normal, resaltando el edema
peritumoral.
– T1w: proporciona el mejor contraste anatómico de referencia.
– T1gd: resalta el tumor activo mediante contraste con gadolinio.
– T2w: destaca tejidos con alto contenido de agua (edema, necrosis).
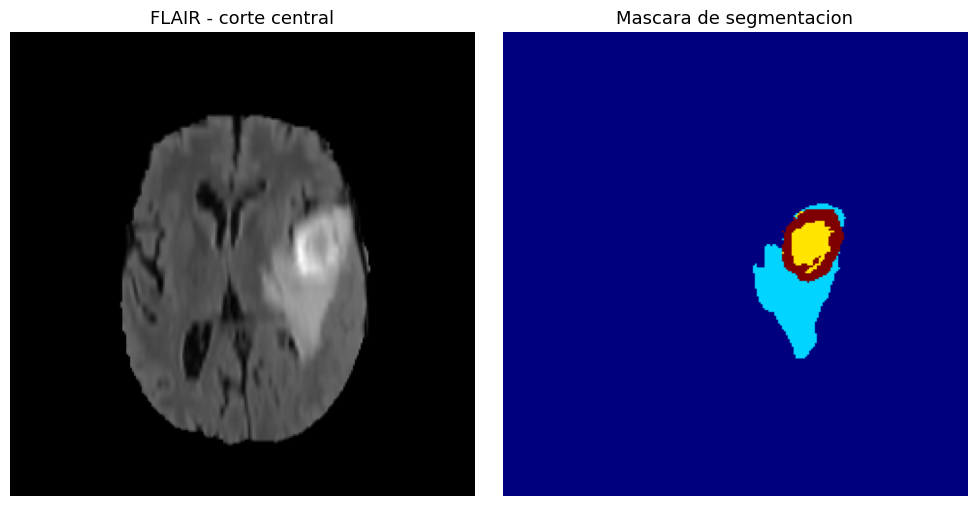
Las máscaras de segmentación etiquetan cuatro regiones: fondo (label 0), edema peritumoral (label 1), tumor no realzado (label 2) y tumor realzado (label 3). El dataset es de acceso abierto a través del Medical Segmentation Decathlon1.
Tras el preprocesado se obtuvieron 66.517 cortes 2D válidos con distribución prácticamente equilibrada: 50.7 % con tumor y 49.3 % sin tumor.
2. Entorno de desarrollo

5. Desarrollo
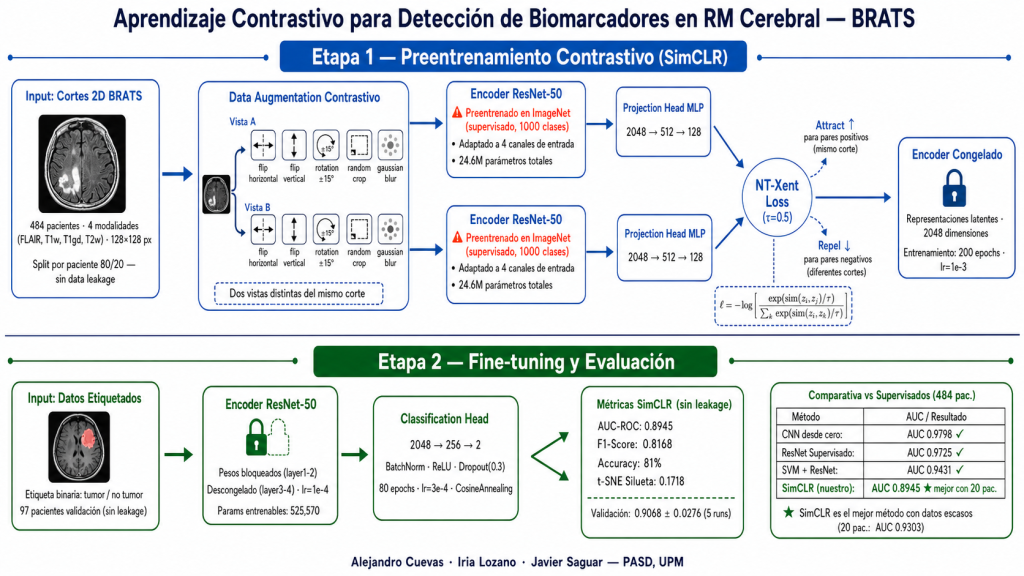
El pipeline se estructura en dos etapas bien diferenciadas: preentrenamiento contrastivo autosupervisado y fine-tuning supervisado.
Etapa 1 — Preentrenamiento contrastivo (SimCLR)
Se extrajeron cortes axiales 2D de cada volumen, descartando los vacíos (valor máximo < 10-5) y aplicando el siguiente preprocesado por canal: clipping al percentil 99.5, normalización z-score y redimensionado a 128 × 128 píxeles.
Adaptamos ResNet-50 preentrenada en ImageNet (clasificación supervisada de 1000
clases de objetos — no un encoder contrastivo de origen) para aceptar 4 canales de entrada, inicializando el canal adicional con la media de los tres originales para preservar los pesos preentrenados. Se eliminó la capa de clasificación final y se añadió una projection head MLP (2048 → 512 → 128).
Para cada corte se generaron dos vistas aumentadas aplicando transformaciones estocásticas independientes: flips horizontal y vertical, rotación aleatoria ±15°, recorte aleatorio (escala 80–100 %) y blur gaussiano. La NT-Xent Loss con temperatura τ = 0,5 forzó al encoder a aprender representaciones similares para vistas del mismo corte y distintas para cortes diferentes, sin usar ninguna etiqueta.
Configuración de entrenamiento: 200 épocas, Adam (lr = 10-3, weight_decay = 10-4),
CosineAnnealingLR (Tmax = 200). Checkpoints guardados cada 10 épocas.
Etapa 2 — Fine-tuning para clasificación
Sobre el encoder preentrenado se añadió una cabeza de clasificación ligera (2048 → 256 → 2, BatchNorm, ReLU, Dropout 0.3). El entrenamiento se realizó en dos fases:
1. Encoder congelado: 80 épocas, lr = 3×10-4, CosineAnnealingLR. Solo se actualizan
los 525.570 parámetros de la cabeza.
2. Encoder parcialmente descongelado: layer3 y layer4 de ResNet-50, 80 épocas
adicionales, lr = 10-4 con CosineAnnealingLR.
6. Resultados
1. Entrenamiento contrastivo
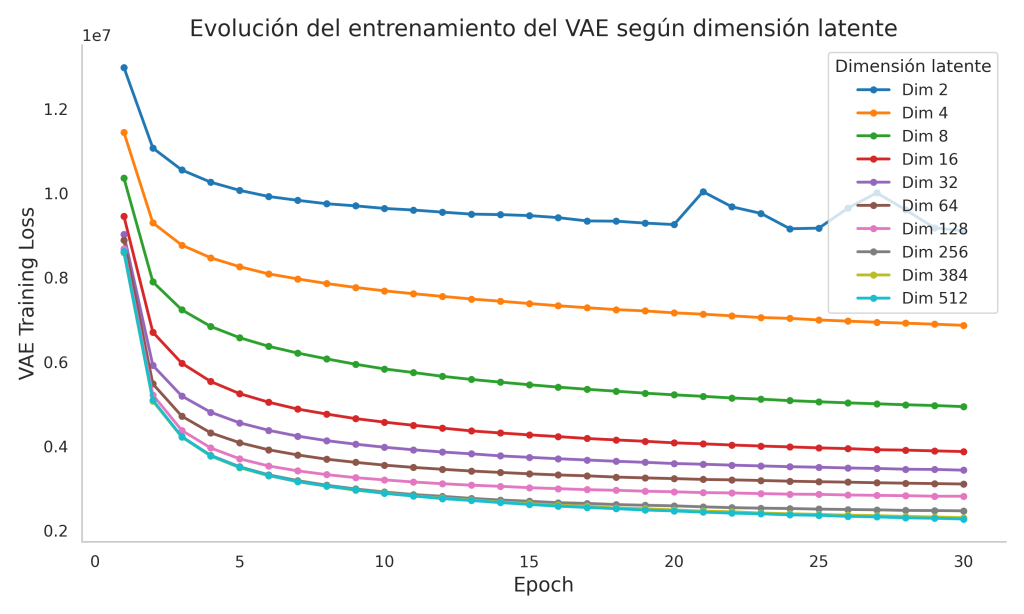
Con 200 épocas sobre 484 pacientes la loss de entrenamiento alcanza 2.8755 (val loss: 3.3574),con una brecha train/val de 0.48 coherente con un split correcto por paciente. La curva deentrenamiento muestra convergencia sostenida a partir de la época 130, cuando el schedulercoseno reduce suficientemente el learning rate.
2. Efecto del preentrenamiento contrastivo
La comparativa de espacios latentes entre ResNet-50 original (silueta: 0.20) y el encoder
SimCLR (silueta: 0.22) evidencia el valor del preentrenamiento contrastivo: la red reorganiza sus representaciones para capturar morfología cerebral en lugar de características de objetos de ImageNet, mejorando la separación emergente entre cortes con y sin tumor.
3. Clasificación final

El clasificador obtuvo AUC-ROC 0.9246 con solo 20 pacientes etiquetados. La validación
estadística con 5 runs y selección aleatoria de pacientes confirma la robustez del método.
4. Comparativa con métodos supervisados
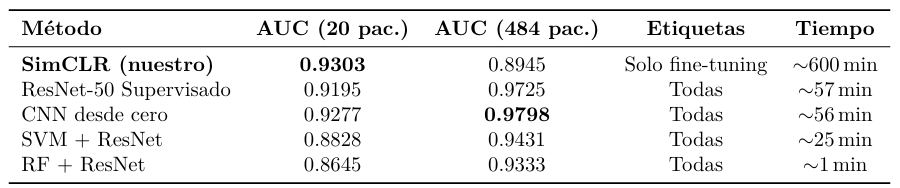
Con 20 pacientes, SimCLR es el mejor método, superando a todos los supervisados sin
haber usado ninguna etiqueta durante el preentrenamiento. Con 484 pacientes los métodos supervisados ganan, lo que define el escenario óptimo de cada enfoque.
7. Discusión
Los resultados demuestran la viabilidad del aprendizaje contrastivo para detectar biomarcadores visuales en RM cerebral multimodal y, más importante, definen con precisión cuándo usarlo.
SimCLR es el método óptimo con datos escasos. Con 20 pacientes etiquetados obtiene
AUC 0.93, superando a ResNet supervisada (0.92) y CNN desde cero (0.93) que necesitan todas las etiquetas. En el contexto clínico real, donde etiquetar volúmenes NIfTI requiere radiólogos especializados y horas de trabajo por caso, esta ventaja es decisiva.
Con suficientes datos, la supervisión directa gana. Con 484 pacientes la CNN desde
cero alcanza AUC 0.98 frente al 0.89 de SimCLR. Resulta llamativo que la CNN sin preentrenamiento supere a ResNet supervisada: una posible explicación es que los sesgos de ImageNet dificultan la adaptación al dominio médico, mientras que la CNN aprende libremente la morfología cerebral.
Análisis de cortes similares. El experimento con cortes centrales (Z=60–100) reveló
un resultado contraintuitivo: filtrar los cortes más “informativos” empeora el AUC (0,89 → 0,78) debido al desbalance extremo resultante (86 % con tumor). Esto confirma que la heterogeneidad del dataset completo, aunque añade dificultad, es metodológicamente necesaria para un entrenamiento generalizable.
Como trabajo futuro: VICReg [3] o BYOL como alternativas más estables, ViT [7] para
capturar dependencias globales, aumentaciones específicas para RM, y segmentación con cabeza U-Net sobre el encoder preentrenado.
8. Conclusiones
El aprendizaje contrastivo (SimCLR) es el método óptimo para la detección de biomarcadores en RM cerebral cuando los datos etiquetados son escasos: con 20 pacientes obtiene AUC 0.93, superando a todos los métodos supervisados. Con datos abundantes (484 pacientes), la supervisión directa resulta más eficiente. La validación estadística con 5 runs (AUC = 0,9068± 0,0276) confirma la robustez del método. El split correcto por paciente es imprescindible para evitar data leakage y obtener estimaciones fiables de generalización.
Referencias
[1] Chen, T., Kornblith, S., Norouzi, M., & Hinton, G. (2020). A Simple Framework for
Contrastive Learning of Visual Representations. ICML 2020. https://arxiv.org/abs/2002.05709
[2] He, K., Fan, H., Wu, Y., Xie, S., & Girshick, R. (2020). Momentum Contrast for
Unsupervised Visual Representation Learning. CVPR 2020. https://arxiv.org/abs/1911.05722
[3] Bardes, A., Ponce, J., & LeCun, Y. (2022). VICReg: Variance-Invariance-Covariance
Regularization for Self-Supervised Learning. ICLR 2022. https://arxiv.org/abs/2105.04906
[4] Menze, B.H. et al. (2015). The Multimodal Brain Tumor Image Segmentation Benchmark (BRATS). IEEE Transactions on Medical Imaging. https://doi.org/10.1109/TMI.
2014.2377694
[5] Bakas, S. et al. (2017). Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels. Scientific Data. https://doi.org/10.1038/sdata.2017.117
[6] He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recogni
tion. CVPR 2016. https://arxiv.org/abs/1512.03385
[7] Dosovitskiy, A. et al. (2021). An Image is Worth 16×16 Words: Transformers for Image
Recognition at Scale. ICLR 2021. https://arxiv.org/abs/2010.11929
[8] Azizi, S. et al. (2021). Big Self-Supervised Models Advance Medical Image Classification. ICCV 2021. https://arxiv.org/abs/2101.05224
[9] Chaitanya, K. et al. (2020). Contrastive Learning of Global and Local Features for Medical Image Segmentation. NeurIPS 2020. https://arxiv.org/abs/2006.10511
[10] Van der Maaten, L., & Hinton, G. (2008). Visualizing Data using t-SNE. Journal of
Machine Learning Research. https://jmlr.org/papers/v9/vandermaaten08a.html