1. INTRODUCCIÓN
En este trabajo se analiza el Multi-Task Learning aplicado a varias tareas de NLP, con el fin de comparar el rendimiento cuando cada una se entrena por separado frente a cuando comparten parte del modelo. Para ello se estudian tres enfoques: entrenamiento independiente, Hard Parameter Sharing y Soft Parameter Sharing.
Las tareas elegidas son NLI, NER y detección de paráfrasis, tres problemas distintos pero lo bastante relacionados como para estudiar posibles efectos de transferencia. NLI consiste en decidir la relación entre dos frases; NER identifica entidades dentro de un texto; y PAWS determina si dos oraciones expresan o no la misma idea.
A partir de este planteamiento, el objetivo es comprobar qué estrategia resulta más eficaz y en qué casos compartir conocimiento entre tareas aporta valor.
El código y los resultados completos están disponibles en el repositorio de GitHub del proyecto: https://github.com/RoblesAdrian/PASD-Blog_Gonzalez-Maldonado-Mao
2. ESTADO DEL ARTE
El Multi-Task Learning se ha utilizado ampliamente en NLP como una forma de aprovechar relaciones entre tareas y compartir representaciones internas cuando existe cierto grado de afinidad entre ellas [1][2]. En este contexto, DistilBERT resulta una base especialmente adecuada por su tamaño reducido y su buen equilibrio entre eficiencia y rendimiento [3]. La literatura también apunta a que compartir parámetros no garantiza mejoras automáticas, ya que el resultado final depende del grado de compatibilidad entre tareas y del tipo de compartición empleado [4]. Sobre esa base, este trabajo compara entrenamiento independiente, Hard Sharing y Soft Sharing para analizar cómo cambia el comportamiento del modelo según la estrategia elegida.
3. MATERIALES
Para este trabajo se han utilizado tres conjuntos de datos públicos y de uso habitual en NLP: MNLI del corpus GLUE, WikiANN en inglés y PAWS-Wiki labeled final.
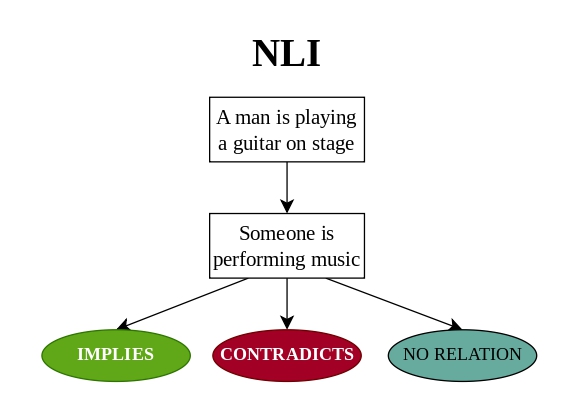
MNLI se ha empleado para la tarea de Natural Language Inference (NLI), donde el modelo debe decidir la relación entre dos frases. Un ejemplo sería una premisa como “A man is playing a guitar on stage” y una hipótesis como “Someone is performing music”, que el sistema debe clasificar según si la primera frase implica, contradice o simplemente no se relaciona con la segunda [5].
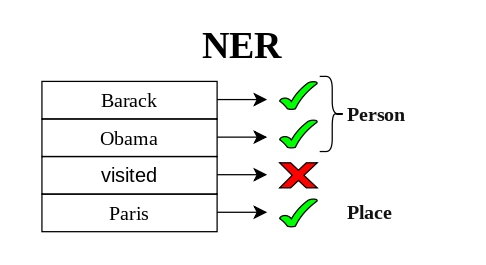
WikiANN se ha usado para Named Entity Recognition (NER), en el que cada palabra del texto recibe una etiqueta. Por ejemplo, en una frase como “Barack Obama visited Paris”, el modelo debe identificar Barack Obama como persona y Paris como lugar [6].
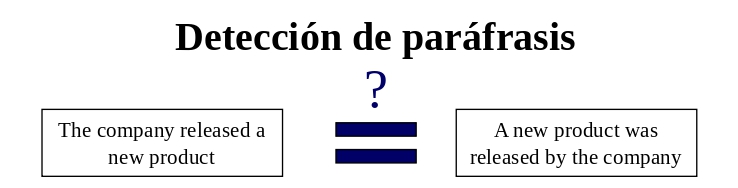
PAWS se ha utilizado para la detección de paráfrasis, es decir, decidir si dos oraciones expresan la misma idea. Un ejemplo sería comparar “The company released a new product” con “A new product was launched by the company”, donde el modelo debe determinar si ambas frases son equivalentes en significado [7].
En cuanto al tamaño de los datos, se ha trabajado con estos subconjuntos: NLI: 31.416 ejemplos de entrenamiento y 7.854 de evaluación, NER: 16.000 de entrenamiento y 4.000 de evaluación, y PAWS: 39.520 de entrenamiento y 9.881 de evaluación. Esta elección permite mantener los tres problemas en un orden de magnitud parecido y, al mismo tiempo, hacer viable la ejecución de todos los experimentos dentro de un tiempo razonable.
Como modelo base se ha empleado DistilBERT-base-uncased, junto con las librerías transformers, datasets y evaluate de Hugging Face. Para NER fue necesario alinear correctamente las etiquetas con los tokens generados por el tokenizador, ya que cada palabra tiene una etiqueta, pero no tiene por qué corresponder a un único token. En NLI y PAWS se trató como un problema de clasificación para la frase completa.
Además del código de entrenamiento, también se han utilizado scripts propios para guardar métricas, registrar el historial de entrenamiento y generar las gráficas comparativas finales.
4. ENTRENAMIENTO POR SEPARADO
La primera referencia fue el entrenamiento separado, donde hicimos fine-tuning del modelo base distilbert-base-uncased para cada una de las tareas y sin compartir parámetros por las demás. De este modo, obtuvimos un modelo de clasificación independiente para cada problema, con su propio conjunto de datos, su propio ajuste y sus propias métricas.
5. HARD PARAMETER SHARING
La primera aproximación al Multi-Task Learning fue mediante Hard Parameter Sharing, en la que todas las tareas comparten el mismo modelo base y solo cambia la capa final de salida. En nuestro caso, el backbone fue distilbert-base-uncased, y sobre él se añadieron tres cabezas distintas, una para NLI, otra para NER y otra para PAWS.
self.backbone = AutoModel.from_pretrained(backbone_name)
self.nli_head = nn.Linear(hidden, nli_labels)
self.paws_head = nn.Linear(hidden, paws_labels)
self.ner_head = nn.Linear(hidden, ner_labels)
El entrenamiento se realizó de forma alterna, pasando por ejemplos de cada tarea dentro de una misma época. La idea se ve en este bloque, donde se va cambiando de tarea en cada paso:
for step in range(steps_per_epoch):
for task in task_order:
batch = next(task_loaders[task])
outputs = model(task=task, ...)Primero se entrenó la versión con las tres tareas a la vez y, después, varias configuraciones de dos tareas: NLI + NER, NLI + PAWS y NER + PAWS.
6. SOFT PARAMETER SHARING
La segunda aproximación al Multi-Task Learning fue mediante Soft Parameter Sharing, donde cada tarea mantiene su propio modelo base, pero se penaliza que sus parámetros se alejen demasiado entre sí. En nuestro caso, se usaron tres backbones independientes de distilbert-base-uncased, uno para NLI, otro para NER y otro para PAWS, junto con sus respectivas cabezas de salida.
A diferencia del Hard Sharing, aquí no se comparte una única representación interna, sino que se añade una pérdida de regularización que empuja a que los tres modelos aprendan representaciones parecidas. Esta parte se implementó comparando los pesos de los backbones dos a dos y sumando la distancia cuadrática entre ellos:
def regularization_loss(self):
reg = 0.0
pairs = [
(self.backbone_nli, self.backbone_ner),
(self.backbone_nli, self.backbone_paws),
(self.backbone_ner, self.backbone_paws),
]
for b1, b2 in pairs:
for p1, p2 in zip(b1.parameters(), b2.parameters()):
reg += torch.sum((p1 - p2) ** 2)
return self.lambda_reg * regEl entrenamiento también se realizó de forma alterna, pasando por batches de cada tarea dentro de una misma época. La diferencia es que, en este caso, cada tarea actualiza su propio backbone, pero siempre bajo la restricción impuesta por la regularización compartida:
for step in range(steps_per_epoch):
for task in task_order:
batch = next(task_loaders[task])
outputs = model(task=task, ...)Esta vez, para acotar la complejidad y el número de experimentos, consideramos suficiente implementarlo únicamente para la configuración de 3 tareas simultáneas (NER + NLI + PAWS).
7. RESULTADOS
6.1. Entrenamiento por separado
En primer lugar, analizamos el entrenamiento base para comprobar que se obtienen buenos resultados: el entrenamiento es estable, converge y el modelo es capaz de aprender a resolver cada una de las tres tareas. Esto servirá como referencia para el resto de experimentos.
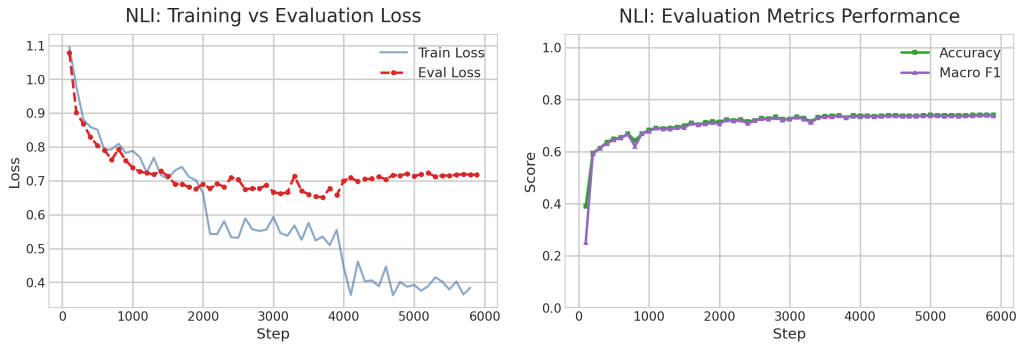
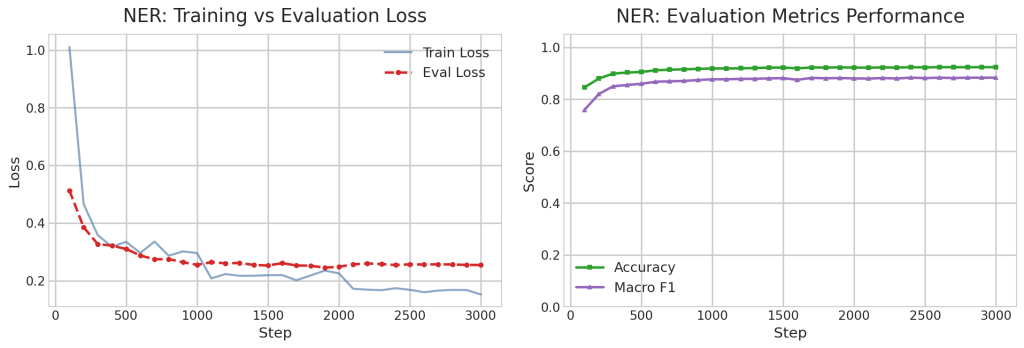
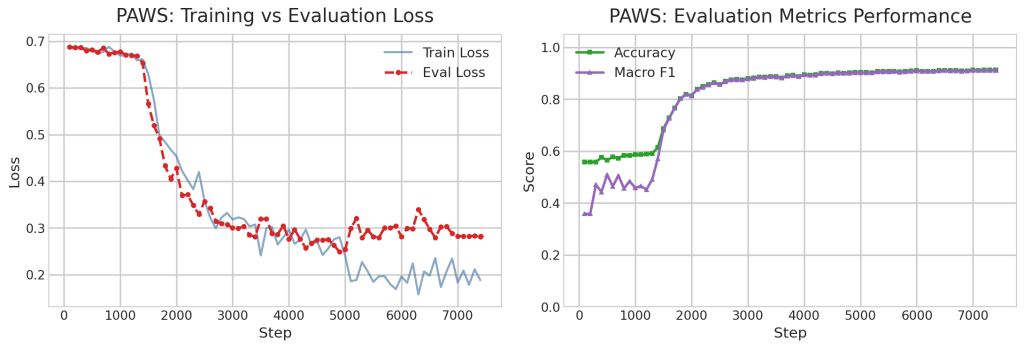
6.2. Resultados globales
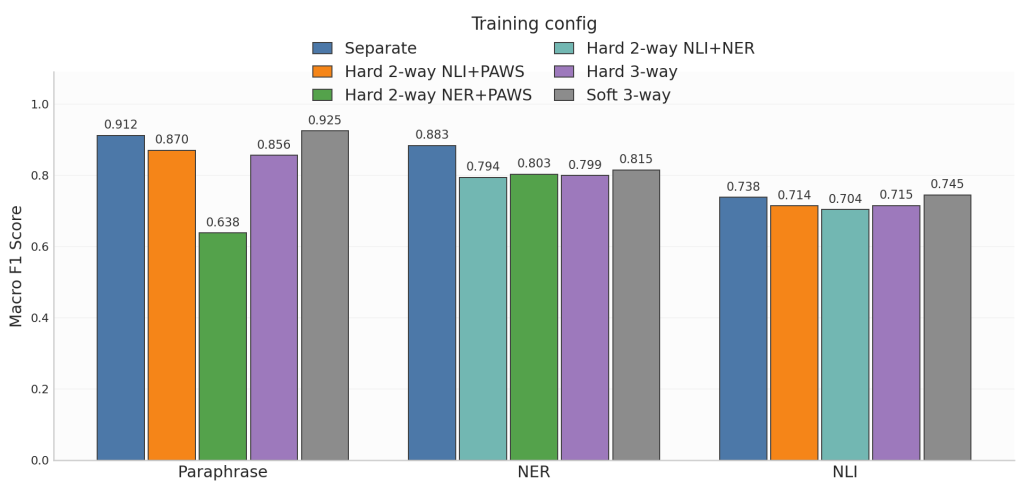
Ahora pasamos a analizar los resultados globales, empezando por Hard Parameter Sharing. Como cabría esperar, el entrenamiento de cada tarea por separado obtiene mejores resultados. Sin embargo, los resultados de Hard Sharing para cada una de las tareas son aceptables y bastante consistentes. A primera vista, no hay dos tareas más cercanas que otras, y únicamente hay una combinación que resulta especialmente negativa en el aprendizaje: NER + PAWS para PAWS (tampoco indica necesariamente que estas tareas sean lejanas, pues NER + PAWS funciona bien para NER).
El aspecto más interesante está en Soft Parameter Sharing: no sólo iguala los resultados del entrenamiento por separado, sino que en dos de las tareas los mejora ligeramente. Una posible hipótesis es que la información de las otras tareas da robustez al modelo, y en este caso sin perder riqueza como sí había sucedido con Hard Sharing.
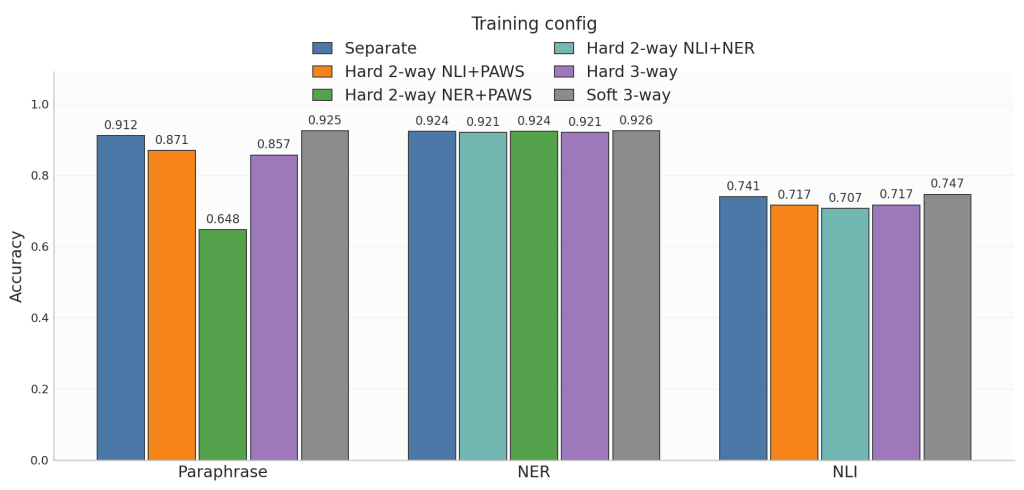
Si nos fijamos en el Accuracy, la visión que obtenemos es similar, con unos resultados más ajustados si cabe:
6.3. Evolución del entrenamiento
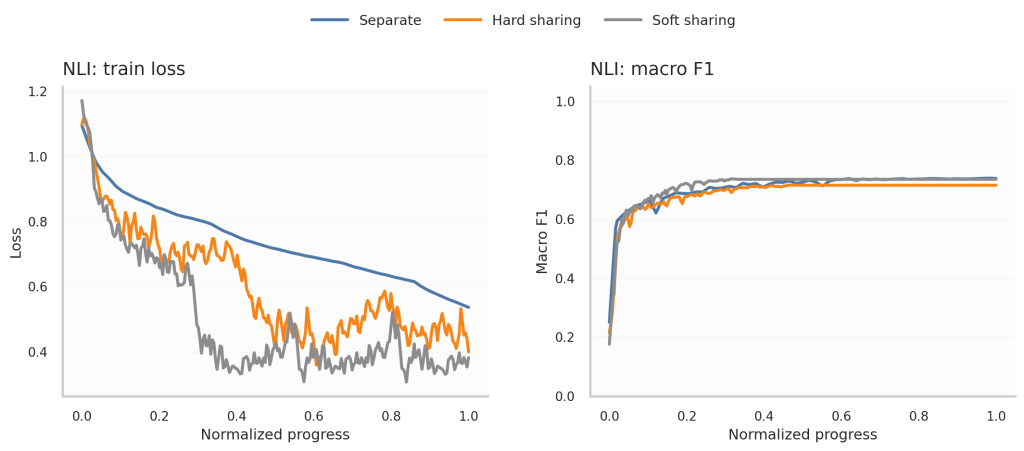
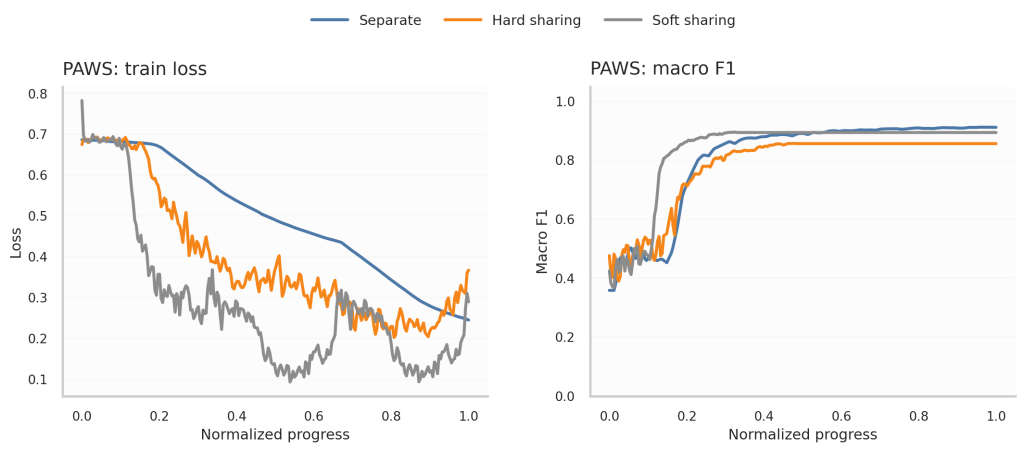
Uno de los aspectos más interesantes a analizar es la evolución de las curvas de entrenamiento. Para ello, esta vez nos fijamos en la función de pérdida (Train) y la métrica Macro F1 Score. Inmediatamente observamos que el entrenamiento por separado es más estable que ambos tipos de compartición, ya que no hay otras tareas interfiriendo en el mismo.
Conviene tener en cuenta que los steps no son directamente comparables entre entrenamientos y épocas: en Multi-Task Learning, el modelo se actualiza más veces porque alterna entre tareas, aunque el número de épocas sea el mismo. Por eso, al comparar las curvas de entrenamiento, normalizamos el progreso al intervalo [0,1]. En este contexto, el entrenamiento separado puede parecer más lento en converger, probablemente porque en el entrenamiento compartido el modelo también recibe actualizaciones procedentes de las otras tareas, algo que no queda reflejado en esa normalización.
Finalmente, Soft Sharing converge y mejora las métricas antes que Hard Sharing, algo esperable siendo una configuración con mayor riqueza y menor rigidez.
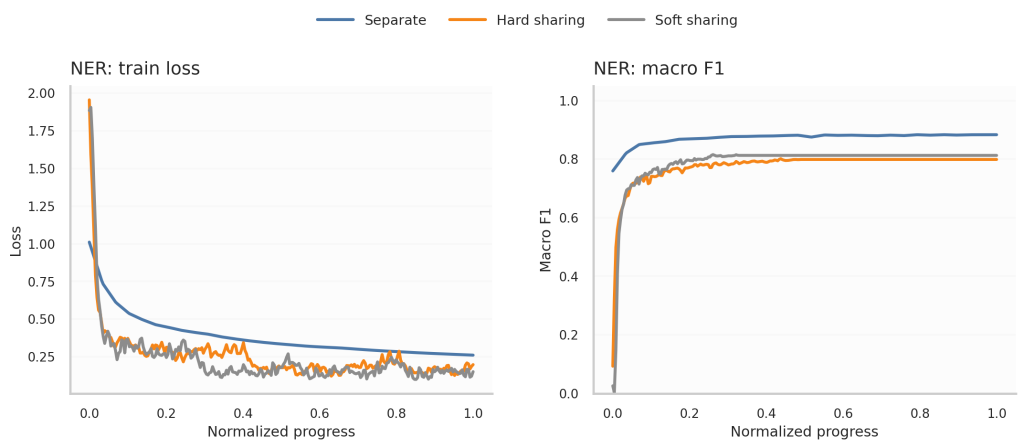
8. DISCUSIÓN
El primer aspecto que podemos plantear es por qué ha funcionado este enfoque. Una razón necesaria es que las tareas de NLP abordadas son lo suficientemente cercanas entre sí como para que lo que aprende una de ellas ayude, o al menos no perjudique, a las demás. Esto puede parecer obvio en tareas de clasificación de texto basadas en un modelo de lenguaje, pero no tiene por qué cumplirse siempre.
En esa misma línea, tan importante como analizar los posibles beneficios de compartir información entre tareas es considerar los posibles efectos negativos de forzarlas a convivir. Aunque apenas hemos conseguido una mejora marginal con los entrenamientos conjuntos, sí hemos observado que una de las combinaciones de Hard Sharing empeoraba de forma muy notable los resultados. Es fácil deteriorar el entrenamiento cuando se agrupan tareas que, en alguna de sus combinaciones, no encajan bien entre sí.
Otro aspecto relevante es el equilibrio entre coste computacional, complejidad del modelo y capacidad de representación. Hard Sharing es la opción más eficiente desde el punto de vista computacional, ya que implica entrenar un único modelo, incluyendo sus capas de salida. Sin embargo, esa simplicidad también limita la riqueza del aprendizaje, y en nuestros experimentos ha sido la configuración que peores métricas ha devuelto. En el extremo opuesto, el entrenamiento por separado ofrece la mayor flexibilidad, porque cada tarea se modela de forma independiente, pero a costa de multiplicar el número de modelos y, con ello, el gasto computacional.
Precisamente el interés de estas técnicas radica en conseguir mejorar ambas dimensiones al mismo tiempo. En nuestro caso, lo hemos conseguido con Soft Sharing: se mantiene una estructura eficiente al introducir relaciones entre parámetros, y el resultado no solo no empeora respecto al entrenamiento por separado, sino que mejora ligeramente el baseline en algunas configuraciones.
Para terminar, nos quedamos con la idea de que no existe una receta universal para obtener buenos resultados en Multi-Task Learning. Más bien, hay que combinar distintas estrategias según las características de los datos, las tareas y el objetivo final, y entender bien cuándo compartir información entre tareas aporta valor y cuándo, por el contrario, introduce ruido o interferencia.
9. REFERENCIAS
- [1] Müller, A. et al. “Cross-lingual Transfer and Multilingual Training in NLP.” Proceedings of EACL 2023. Disponible en: https://aclanthology.org/2023.eacl-main.66.pdf
- [2] Sanh, V., Debut, L., Chaumond, J. y Wolf, T. “DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter.” arXiv preprint arXiv:1910.01108 (2019). Disponible en: https://arxiv.org/abs/1910.01108
- [3] Plank, B. “Multi-task learning for NLP.” LxMLS 2021 Lecture Notes / Tutorial. Disponible en: https://lxmls.it.pt/2021/wp-content/uploads/2021/07/LxMLS2021-bplank.pdf
- [4] “Article / paper on ACM DOI 10.1145/3663363.” ACM Digital Library. Disponible en: https://dl.acm.org/doi/10.1145/3663363
- [5] Wang, A. et al. “GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding.” arXiv (2018). Disponible en: https://arxiv.org/abs/1804.07461
- [6] Pan, X. et al. “Cross-lingual Name Tagging and Linking for 282 Languages.” ACL (2017). WikiANN / PAN-X corpus. Disponible en: https://aclanthology.org/P17-1174/
- [7] Zhang, Y., Baldridge, J., He, L. y Gildea, D. “PAWS: Paraphrase Adversaries from Word Scrambling.” NAACL (2019). Disponible en: https://aclanthology.org/N19-1131/
Sergio González Girones · Adrián Maldonado Robles · Alicia Mao Zhu