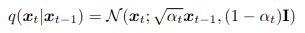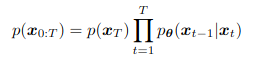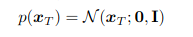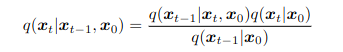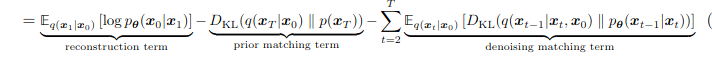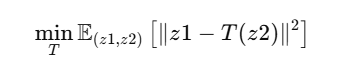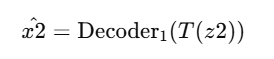1. Introducción
En muchas situaciones reales, como la vigilancia nocturna o la conducción con poca visibilidad, es clave disponer de imágenes que ofrezcan tanto los detalles visuales del espectro visible como la capacidad del infrarrojo para ver en la oscuridad. Sin embargo, por separado, cada tipo de cámara tiene sus limitaciones: las visibles no funcionan bien sin luz y las infrarrojas no muestran bien los contornos ni las texturas. Por eso surge la fusión de imágenes, una técnica que combina lo mejor de ambas para obtener una imagen única, más completa y útil.

Esta fusión consiste en integrar imágenes captadas por distintos sensores para conservar la información más relevante de cada una. Se usa en múltiples ámbitos como la visión nocturna, la seguridad, la medicina o los sistemas de navegación autónoma. El desafío está en combinar esas imágenes sin perder calidad ni introducir errores visuales, algo que no es sencillo.
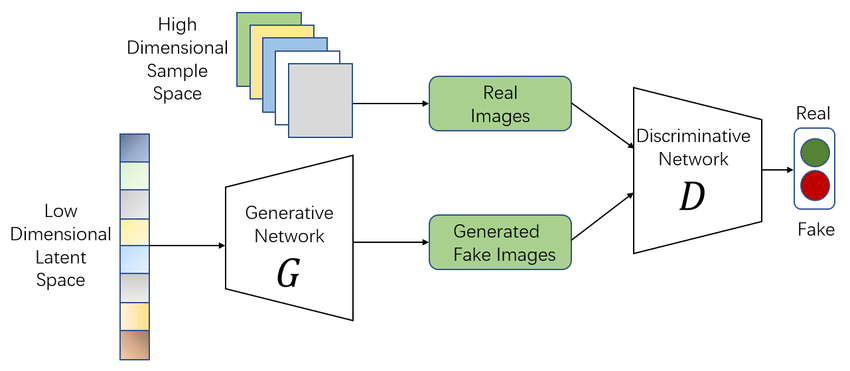
Las redes neuronales, y en particular U-Net, resultan muy útiles para fusionar imágenes, ya que su estructura en forma de U con conexiones internas permite combinar eficazmente tanto los detalles finos como la forma general de cada imagen.
En este proyecto, vamos a desarrollar un sistema de fusión de imágenes visibles e infrarrojas usando U-Net en TensorFlow. Evaluaremos su rendimiento tanto visualmente como con métricas objetivas como SSIM y PSNR, y compararemos sus resultados frente a métodos clásicos para ver si realmente ofrece una mejora significativa.
2. Estado del arte
La fusión de imágenes ha sido una herramienta clave en el procesamiento de señales. Inicialmente, se utilizaban técnicas matemáticas tradicionales como la transformada wavelet, el análisis de componentes principales (PCA) y la transformada de Laplace. Estas técnicas se basaban en descomponer las imágenes en diferentes componentes para luego combinarlas según ciertos criterios (como, la varianza) pero tenían ciertas limitaciones al preservar simultáneamente detalles finos y estructuras globales.

Con la llegada del aprendizaje profundo, las redes neuronales convolucionales (CNN) revolucionaron este campo. Estas redes pueden aprender automáticamente qué características conservar y cómo combinarlas, sin necesidad de definir reglas manualmente. Esto ha permitido resultados más adaptativos y robustos frente a variaciones en las condiciones de entrada.
En particular, la arquitectura U-Net, ha demostrado ser especialmente eficaz para tareas de procesamiento de imágenes donde es crucial mantener tanto la resolución espacial como el contexto semántico. Su diseño de encoder-decoder con conexiones de salto (skip connections) permite preservar detalles a diferentes escalas. Esto la convierte en una candidata ideal para la fusión de imágenes visibles e infrarrojas.
Investigaciones recientes han adaptado U-Net para esta tarea. Por ejemplo, Zhang et al. (2021) integraron mecanismos de atención para mejorar la selección de características. Ma et al. (2020) destacaron su equilibrio entre calidad y eficiencia computacional. Además, el repositorio IVIF_ZOO ofrece implementaciones de U-Net evaluadas en benchmarks como TNO y RoadScene.
3. Fundamentos matemáticos
U-Net es una arquitectura de red neuronal convolucional que se ha convertido en una herramienta muy versátil en el ámbito del procesamiento de imágenes. Aunque fue concebida originalmente para tareas de segmentación médica, su capacidad para preservar detalles finos mientras captura el contexto global la ha hecho popular en muchos otros escenarios, como la reconstrucción y, en este caso, la fusión de imágenes visibles e infrarrojas.
Su estructura, con forma de “U”, consta de dos partes simétricas:
- Un codificador (encoder), que realiza una serie de convoluciones y max-pooling para capturar el contexto global de la imagen, reduciendo su resolución.
- Un decodificador (decoder), que realiza upsampling progresivo (mediante convoluciones transpuestas) para reconstruir una imagen de la misma dimensión original.
Lo más distintivo de esta red son las llamadas conexiones de salto, que permiten transmitir directamente la información desde las capas del codificador a las correspondientes del decodificador. Gracias a estas conexiones, se consigue combinar de forma eficaz tanto los detalles locales como la estructura general de la imagen, algo fundamental cuando se fusionan fuentes tan distintas como el espectro visible y el infrarrojo.
En este proyecto, implementamos U-Net en TensorFlow/Keras para combinar imágenes de dos canales (visible e infrarrojo) en una imagen fusionada de un solo canal. Como no existe una imagen ideal de referencia, se usó como guía la fusión por máximo por píxel entre los dos canales.
Para este proyecto empleamos el dataset LLVIP, una colección específicamente diseñada para condiciones de baja iluminación, que contiene pares de imágenes visibles e infrarrojas capturadas de forma sincronizada. Este conjunto resulta especialmente adecuado para tareas de fusión de imágenes multiespectrales, ya que refleja escenarios reales donde la información visual y térmica debe combinarse para obtener una visión más completa.
La evaluación de los resultados se realizó utilizando dos métricas: SSIM que mide la similitud estructural entre la imagen fusionada y una de las originales, capturando aspectos como el contraste, la luminancia y la textura; y PSNR que cuantifica la fidelidad de la señal en términos de error cuadrático medio. Ambas métricas fueron calculadas respecto a las imágenes visibles e infrarrojas por separado, lo que nos permitió analizar qué tipo de información retiene mejor el modelo en la imagen resultante.
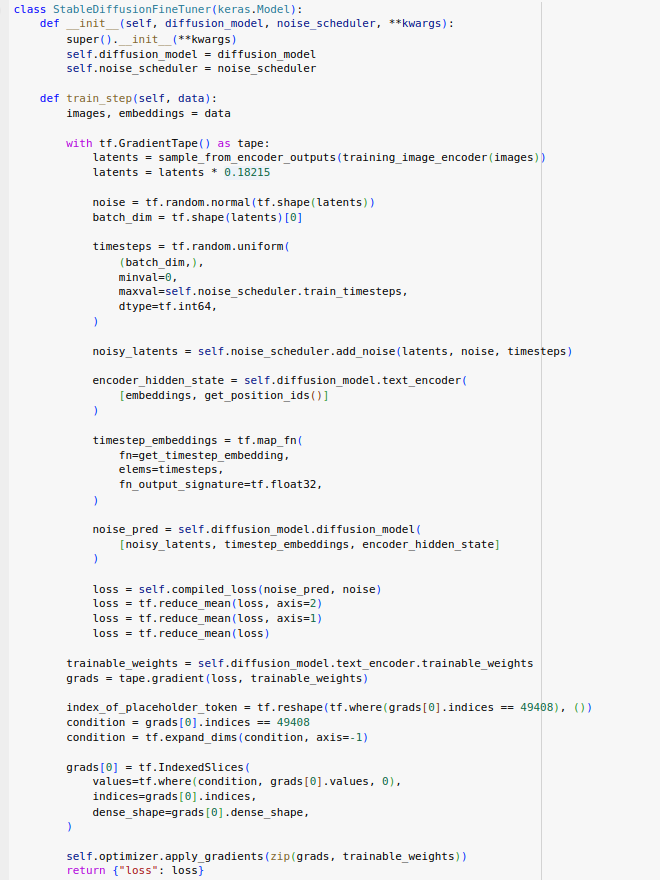
4. Implementación
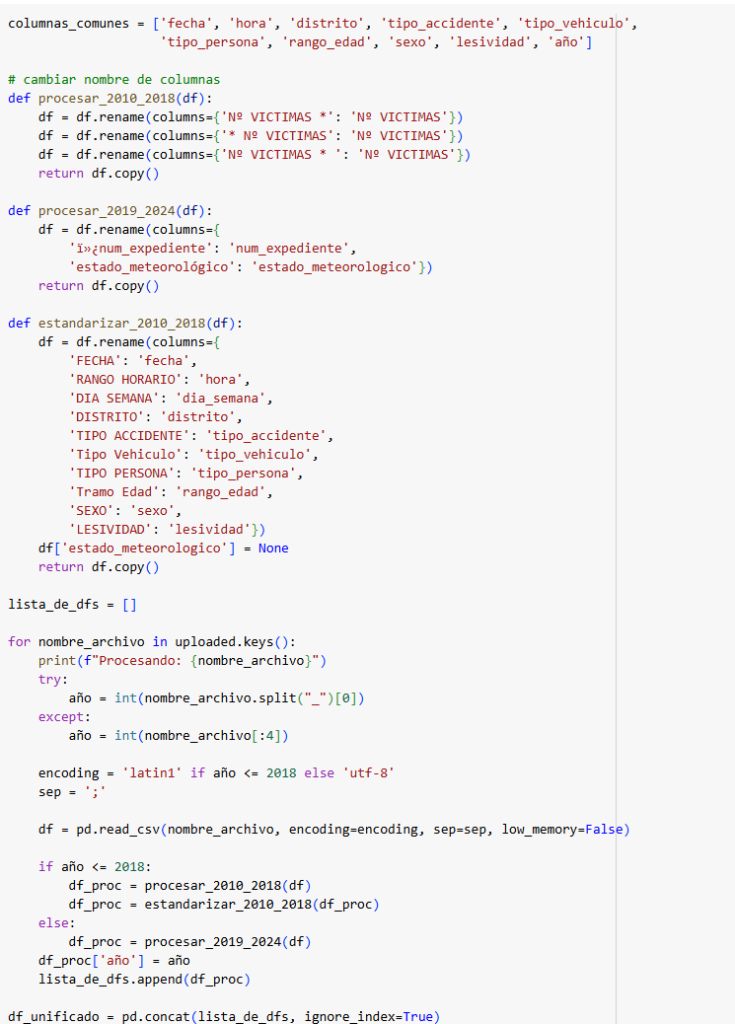
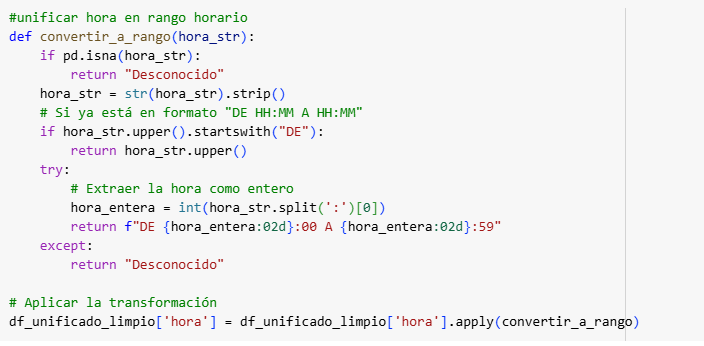
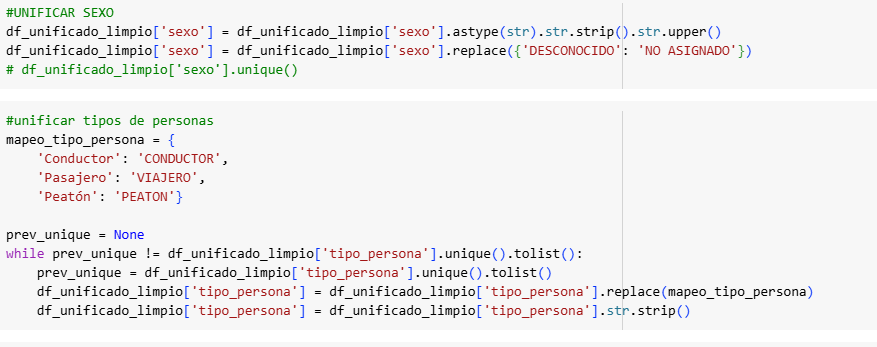
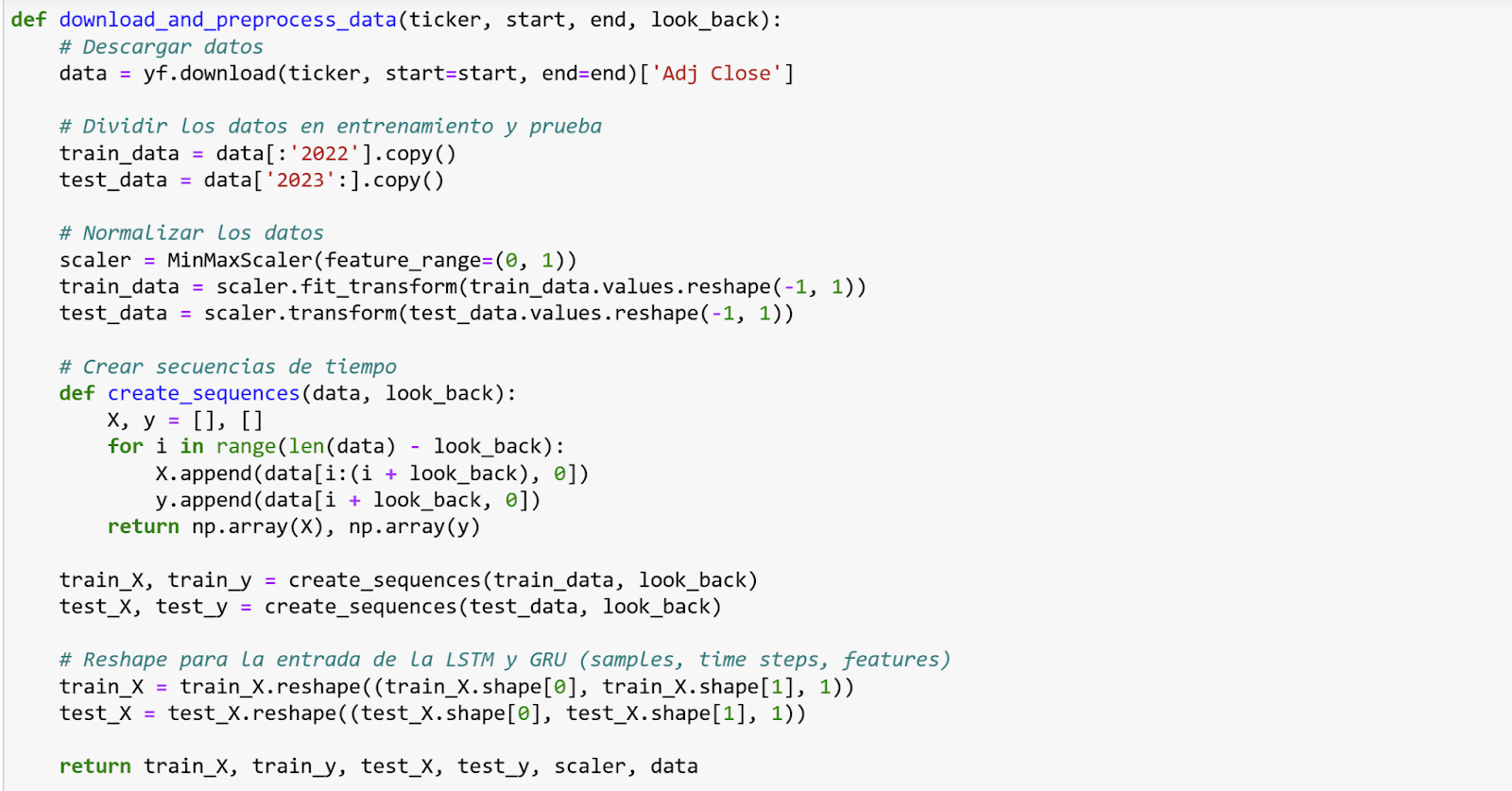
Para este proyecto se ha utilizado el dataset LLVIP, un conjunto de datos en abierto que contiene imágenes visibles e infrarrojas de personas en entornos con baja iluminación. Las imágenes fueron preprocesadas adaptándolas en tamaño a 256×256 píxeles, normalizadas al rango [0,1], y combinadas como canales de entrada a la red.

El modelo se implementó en TensorFlow/Keras siguiendo una arquitectura U-Net, compuesta por un codificador, un cuello de botella y un decodificador con conexiones de salto. La salida generada es una imagen fusionada a nivel de píxel.


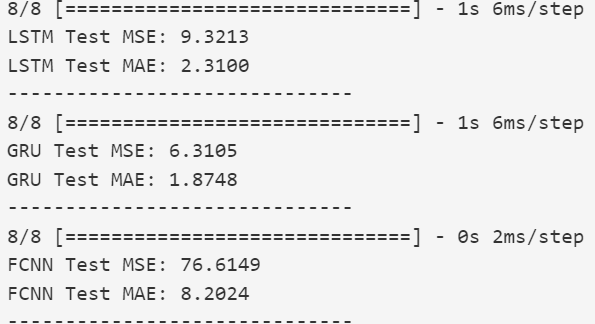
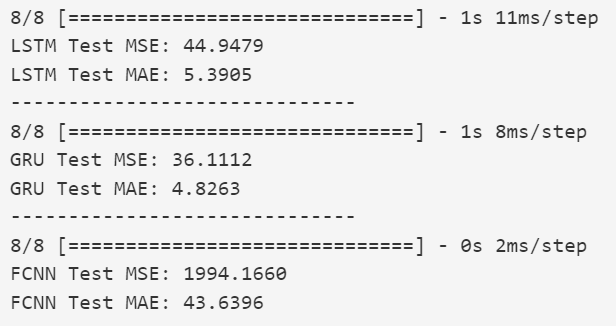
El entrenamiento se llevó a cabo en Google Colab durante 20 épocas, utilizando el optimizador Adam y la función de pérdida MSE. Como métricas de evaluación se emplearon SSIM y PSNR.
Se utilizaron herramientas auxiliares como OpenCV, Matplotlib, Pandas y scikit-image. Todo el código ejecutable y los resultados se encuentran disponibles en el archivo entregado: pasd.zip, que incluye el notebook completo y los ficheros necesarios para su reproducción.
5. Resultados
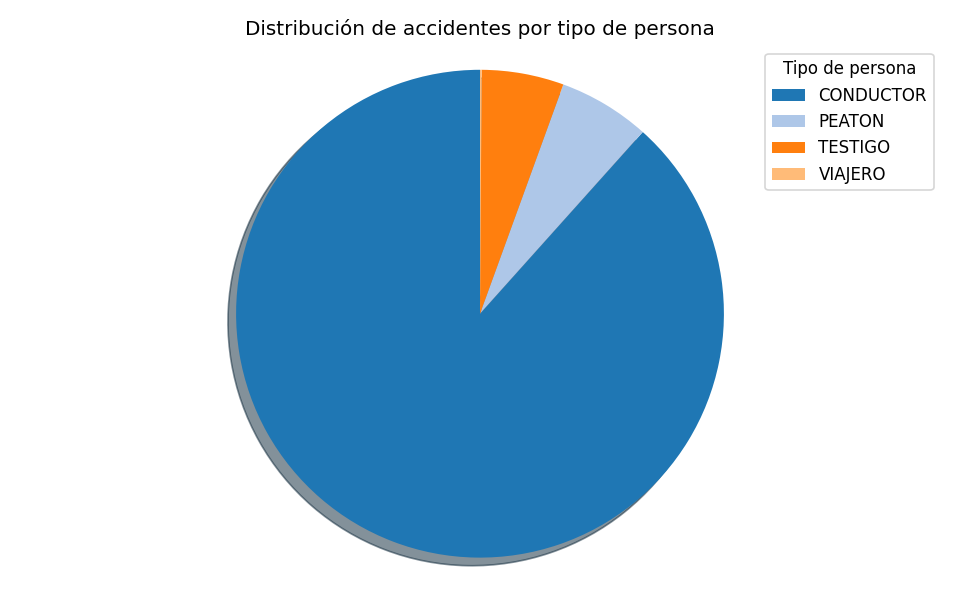
Para evaluar la calidad de las imágenes fusionadas, se calcularon las métricas SSIM y PSNR comparando cada imagen fusionada con sus respectivas versiones visibles e infrarrojas.


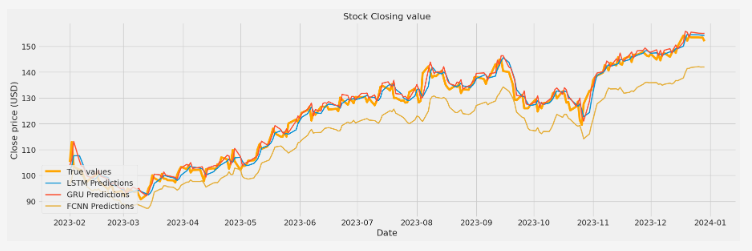
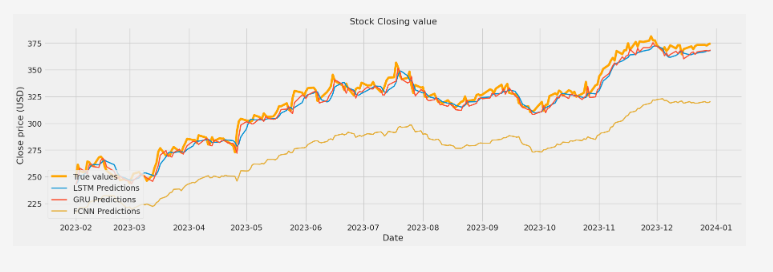
Los valores obtenidos indican que la imagen fusionada conserva principalmente la estructura del canal infrarrojo, lo cual es adecuado para aplicaciones como la visión nocturna.
Sin embargo, también se observa que la similitud con la imagen visible es más baja, lo que sugiere que el modelo tiende a priorizar el contenido térmico. Esto puede ser una ventaja en contextos de vigilancia, pero en aplicaciones donde los detalles visuales sean importantes (como el reconocimiento facial o la navegación autónoma diurna), podría requerir un ajuste de pesos o entrenamiento más equilibrado.
6. Discusión
Los resultados obtenidos muestran que el modelo basado en U-Net es capaz de realizar una fusión efectiva entre imágenes visibles e infrarrojas, preservando especialmente la información térmica, tal como reflejan los altos valores de SSIM y PSNR frente al canal infrarrojo. Este comportamiento es deseable en aplicaciones donde el contenido térmico es prioritario, como en seguridad nocturna o detección de personas en condiciones adversas.
Sin embargo, también se ha observado que la similitud con la imagen visible es notablemente más baja. Este fenómeno puede explicarse por dos razones principales: por un lado, la imagen infrarroja tiende a dominar la estructura global en la fusión; por otro, al utilizarse como supervisión una imagen construida mediante el máximo por píxel entre los dos canales, el modelo tiende a favorecer la información del canal con mayor intensidad, que suele ser el térmico.
Entre las principales limitaciones encontradas destaca el tamaño efectivo del dataset. Aunque LLVIP es una base de datos estándar, el número de imágenes disponibles tras el preprocesado y la división en entrenamiento y prueba puede ser insuficiente para entrenar redes profundas que generalicen bien a nuevas escenas. Además, se ha trabajado con una resolución fija de 256×256 píxeles para simplificar el entrenamiento, lo que puede haber afectado a la calidad visual en detalles finos, como bordes o texturas.
A pesar de los buenos resultados, este trabajo deja abiertas varias vías de mejora. Usar otros datasets como TNO o RoadScene podría aumentar la capacidad de generalización. También se podrían probar funciones de pérdida más perceptuales o modelos como GANs para obtener fusiones más realistas.
Además, sería interesante explorar arquitecturas más avanzadas, como Attention U-Net o redes con ramas separadas para cada canal, e incluso probar con Transformers. Por último, aplicar técnicas de postprocesado ayudaría a mejorar bordes, contraste y detalles finos en las imágenes fusionadas.
7. Conclusiones
En este proyecto hemos abordado la fusión de imágenes visibles e infrarrojas usando redes neuronales profundas, concretamente la arquitectura U-Net. Los resultados muestran que este enfoque permite combinar eficazmente la información visual y térmica, generando imágenes más completas que las captadas por sensores individuales. El modelo, implementado en TensorFlow/Keras y entrenado con el dataset LLVIP, logró buenas puntuaciones en SSIM y PSNR, lo que confirma su efectividad.
8. Referencias
- Artículos científicos y papers citados
- Ronneberger, O., Fischer, P., & Brox, T. (2015): U-Net: Convolutional Networks for Biomedical Image Segmentation https://arxiv.org/abs/1505.04597
- Zhang et al. (2021): IFCNN: A general image fusion framework based on convolutional neural network https://doi.org/10.1016/j.inffus.2020.10.011
- Ma et al. (2020): Infrared and Visible Image Fusion via Detail-Preserving Deep Neural Network https://doi.org/10.1109/TIP.2020.2972127
- Datasets
- LLVIP Dataset – Low-Light Visible and Infrared Person Dataset
https://github.com/dawnlh/LLVIP
- Repositorios relacionados
- IVIF_ZOO – Infrared and Visible Image Fusion Models
https://github.com/RollingPlain/IVIF_ZOO
Trabajo realizado por Julia Galán, Sara Reyes y Silvia Cordero.
PASD 2025.