Introducción
Las Redes Generativas Adversarias (GANs) son una clase de modelos de aprendizaje profundo compuesto por dos redes neuronales, una red generativa y una discriminativa, que se entrenan en un proceso de competencia:
- El generador es responsable de crear nuevos datos que se parezcan lo máximo posible al conjunto de datos original.
- El discriminador, por su parte, tiene como objetivo distinguir entre los datos generados por el generador y los reales del conjunto original.
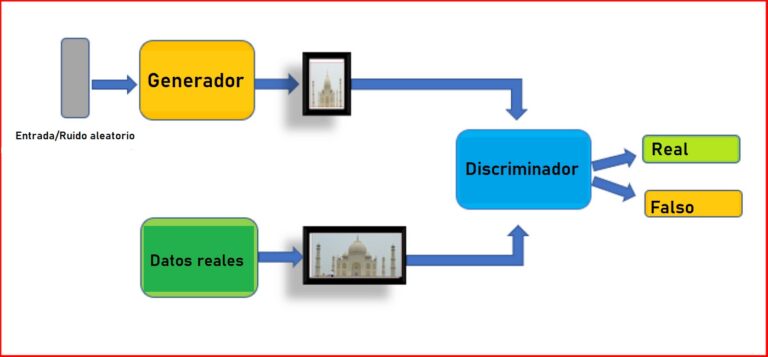
Esta competición entre el generador y el discriminador empuja a ambas redes a mejorar. Es decir, el generador aprenderá a producir datos más realistas y el discriminador mejorará en la distinción entre datos reales y falsos.
Las GANs han abierto un abanico de posibilidades en distintos campos, desde la generación de imágenes hasta la mejora de la resolución de fotografías o incluso el aumento del conjunto de datos de entrenamiento para un modelo de aprendizaje automático. En este blog nos centraremos en la generación de rostros humanos mediante el uso de una Deep Convolutional GAN (DCGAN). Estas, a diferencia de una GAN básica, utilizan redes neuronales convolucionales, lo que las hace especialmente aptas para trabajar con imágenes.
Estado del Arte
En el año 2014, Ian Goodfellow y sus colaboradores propusieron lo que hoy en día conocemos como Redes Generativas Adversarias: un enfoque innovador para entrenar modelos generativos mediante un proceso adversarial, en el que se entrenan simultáneamente dos redes neuronales: un generador (G) y un discriminador (D).
En este proceso, el generador toma ruido aleatorio y lo convierte en muestras sintéticas, que intentan imitar los datos reales. El discriminador, por su parte, recibe tanto muestras reales como generadas, calcula la probabilidad de que cada muestra provenga de los datos reales en lugar del generador.
Este entrenamiento está basado en un juego de minimax, donde el generador busca engañar al discriminador, y el discriminador intenta no ser engañado. Matemáticamente, esto se expresa como:
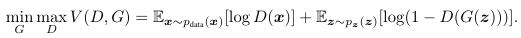
En 2015, se propuso una mejora significativa de las GANs originales conocida como Deep Convolutional GANs (DCGANs). La principal diferencia radica en la sustitución de las redes totalmente conectadas por redes neuronales convolucionales (CNNs) tanto en el generador (G) como en el discriminador (D). Esta modificación permite que las DCGANs sean más efectivas para trabajar con imágenes, ya que las CNNs son capaces de capturar las relaciones espaciales y estructurales dentro de los datos, lo que resulta en la generación de imágenes de mucho mayor calidad.
Desarrollo
Hemos decidido implementar una DCGAN para poder crear rostros humanos a partir del dataset CelebA que se puede encontrar en Kaggle.
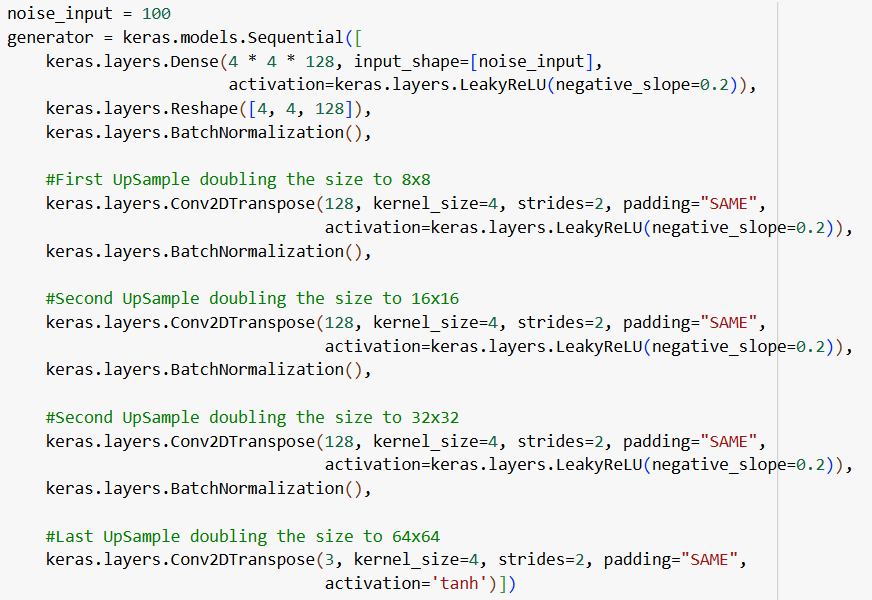
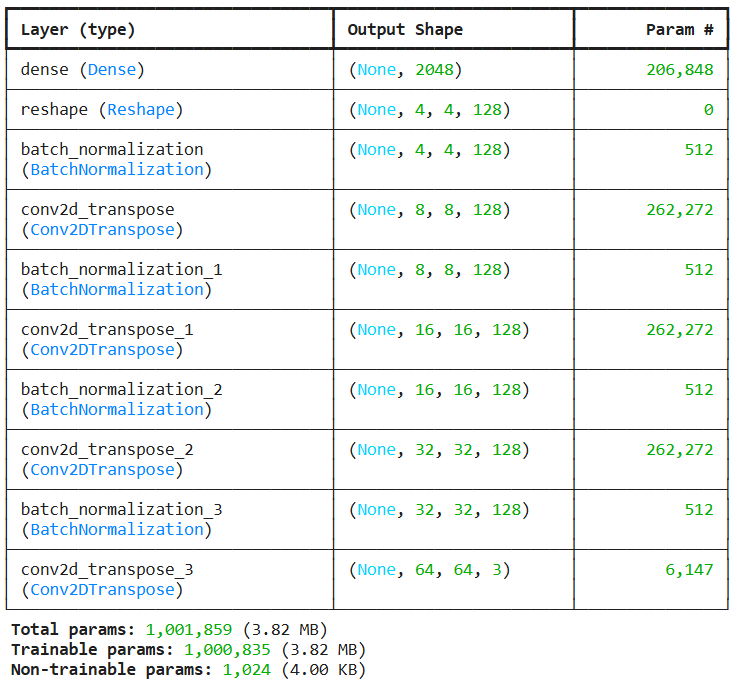
Esta es la arquitectura de nuestro generador. Está compuesta por 5 capas convolucionales y 1 densa inicial que convierte el vector de ruido a una una representación de 4x4x128 usando la activación LeakyReLU. Después hay 4 capas de upsampling para poder producir imágenes de 64×64 con tres canales de color RGB. El Batch Normalization es una técnica que se utiliza para mejorar la estabilidad y el rendimiento durante el entrenamiento normalizando las activaciones de las capas de la red.
El discriminador se compone de 4 capas de convolución 2D con activaciones LeakyReLU para mejorar la propagación del gradiente e intercalando capas de Dropout para reducir el sobreajuste. Finalmente el discriminador aplana las características y a través de una capa densa con activación sigmoide saca una variable binaria para indicar si la entrada es real o falsa.

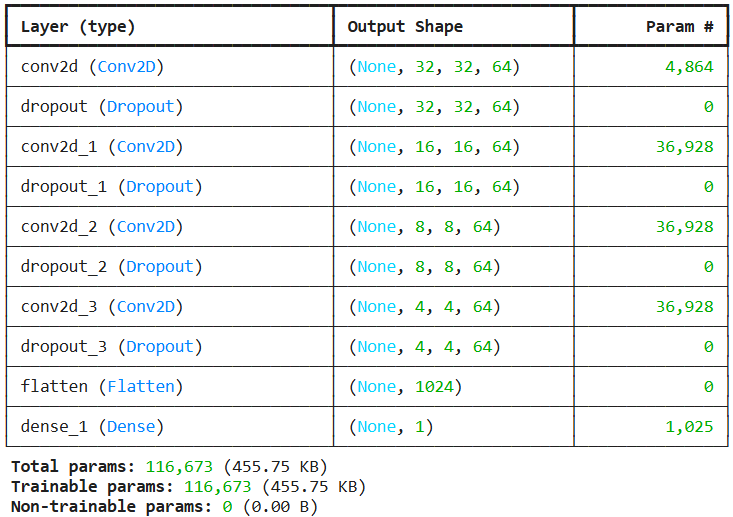
Después de establecer los optimizadores Adam para nuestra GAN el resultado de la misma sería este. Estos optimizadores permiten ajustar las tasas de aprendizaje de manera individual para cada parámetro, ayudando a mejorar la convergencia y permitiendo escapar al modelo de los mínimos locales.

Por último, esta es la función con la que hemos entrenado a nuestra GAN. Se define un ciclo de entrenamiento dividido en 2 fases. Durante la fase 1, el discriminador se actualiza usando un lote de imágenes mezcladas, mientras que en la fase 2 el generador se entrena para generar imágenes “reales” que engañen al discriminador.

Materiales
El dataset CelebA (CelebFaces Attributes Dataset) es un conjunto de 202.599 imágenes de rostros humanos extraídas de celebridades, que incluye aproximadamente 10.000 rostros diferentes. Estas imágenes están centradas y alineadas, lo que facilita su uso en tareas de visión por computador donde se requiere consistencia estructural en las entradas. Este es un ejemplo de rostros que aparecen en el dataset:

El uso de CelebA en el entrenamiento de redes generativas adversarias (GANs) ofrece diversas ventajas. Su gran volumen de datos, unido a la variedad de atributos y condiciones de iluminación, permite al modelo aprender representaciones ricas y generalizables del rostro humano.
Por otro lado, el código que hemos utilizado para nuestro estudio puede encontrarse en el siguiente enlace de GitHub:
- Enlace al Github: GANs/C2_GAN_CIFAR.ipynb at main · peremartra/GANs · GitHub
En este caso, el autor utiliza el dataset CIFAR. Nosotros lo hemos adaptado a la generación de rostros humanos con el dataset CelebA.
Resultados
Para demostrar la evolución de las imágenes a lo largo de las épocas vamos a graficar las imágenes cada 10 épocas y veremos la evolución a la hora de generar rostros. Representamos los resultados a través de una imagen tipo GIF a lo largo de las épocas.

También vamos a estudiar los resultados de la época 300 y 400:


Discusión de resultados
Inicio del entrenamiento (Primeras 10 épocas)
En el GIF, al comienzo, las salidas del generador son todo ruido. Esto es esperado, ya que el generador aún no ha aprendido ninguna distribución del conjunto de datos real. Podríamos decir que el generador convierte ruido en ruido, el discriminador rechaza todo lo generado, y el generador apenas comienza a recibir señales útiles para aprender.
Fase temprana del aprendizaje (Épocas 10-30)
Se empiezan a vislumbrar formas vagas que podrían parecer estructuras faciales: distribuciones de color más organizadas, manchas que se transformarán en ojos, bocas, etc. El generador empieza a “engañar” parcialmente al discriminador en ciertas regiones de la imagen.
Fase intermedia (Épocas 30-60)
Las caras empiezan a ser más reconocibles, aunque distorsionadas. Vemos características como rasgos faciales mal colocados, algunas caras simétricas, otras claramente defectuosas y mejora de la distribución de color (colores de piel más realistas). Hay signos de colapso parcial ya que algunas imágenes parecen repetirse con poca variabilidad.
Fase avanzada (Épocas 60-100)
Las imágenes generadas se parecen a rostros humanos completos. Podemos ya decir que genera colores realistas, proporciones más consistentes, mejora en la diversidad de rostros y rasgos faciales diferenciados. Aún así, la generación de imágenes sigue presentando errores más específicos que dejan la puerta abierta a una posterior mejora del modelo como: aumento de la diversidad de rostros, ojos o bocas desalineados, deformaciones en el fondo o cabello, y en algunas imágenes múltiples rostros superpuestos.
Fase mejorada (Épocas 300 y 400)
A pesar de la mejora de rostros, seguían existiendo los problemas mencionados. Por ello ejecutamos hasta las épocas 300 y 400. Vemos que a medida que el modelo avanza, se observa un refinamiento en las características faciales, mayor diversidad y detalles más precisos, aunque aún persisten pequeños defectos. Esto es una señal de que el generador está aprendiendo de manera efectiva las distribuciones de las caras humanas y está acercándose a un estado más realista en su capacidad para producir imágenes coherentes y variadas.
Referencias
- Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., Courville, A., & Bengio, Y. (2014). Generative Adversarial Nets. 1406.2661
- Martra, P. (2023, 20 de febrero). Tutorial GAN-2. Crear una GAN para imágenes a color. MARTRA UADLA. https://martra.uadla.com/tutorial-gan-2-crear-una-gan-para-imagenes-a-color/
- Rivera, M. (2020, septiembre). DCGAN: Redes Generadoras Antagónicas Convolucionales Profundas. Centro de Investigación en Matemáticas (CIMAT). https://www.cimat.mx/~mrivera/cursos/aprendizaje_profundo/dcgan/dcgan.html
- Radford, A., Metz, L. y Chintala, S. (2015, 19 de noviembre). Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks. https://arxiv.org/pdf/1511.06434
- Liu, Ziwei; Luo, Ping; Wang, Xiaogang; Tang, Xiaoou. (s.f.). Large-scale CelebFaces Attributes (CelebA) Dataset. CelebA Dataset
AUTORES: Alejandro González, José María Martín, Pablo Mateo y Daniel Vigil.