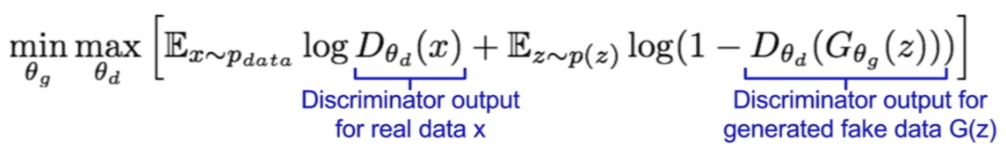Introducción
En el campo de la imagen médica, la posibilidad de transformar una modalidad en otra, como generar imágenes de tomografía computarizada (CT) a partir de resonancia magnética (MRI) o tomografía por emisión de positrones (PET) se está convirtiendo en una herramienta revolucionaria. Modelos como las redes generativas antagónicas (GANs) permiten esta conversión de forma precisa y sin necesidad de someter al paciente a múltiples escaneos, lo que reduce la exposición a radiación [1], ahorra costes clínicos y facilita el uso de sistemas diseñados específicamente para trabajar con imágenes CT. Además, estas imágenes sintéticas permiten ampliar conjuntos de datos para entrenar algoritmos, mejorar la planificación quirúrgica o radioterápica y avanzar hacia una medicina más personalizada y eficiente [2]. La generación de CT sintéticas a partir de MRI o PET representa así una solución elegante y práctica a varios de los retos actuales en diagnóstico por imagen.
Para entender la aplicación de esta GAN en la transformación de imágenes médicas lo primero que tendremos que hacer será aprender las características del formato de imágenes que vamos a utilizar:
Imágenes por Resonancia Magnética (MRI)
La resonancia magnética se utiliza para visualizar tejidos blandos con gran detalle, cómo el cerebro, los músculos o los ligamentos, sin necesidad de radiación ionizante. Es especialmente útil en neurología y traumatología.

Tomografía por Emisión de Positrones (PET)
Las imágenes PET permiten observar procesos metabólicos en el cuerpo, siendo muy eficaces para detectar tumores activos y hacer seguimiento en tratamientos oncológicos. Proporcionan una visión funcional más que estructural.

Tomografía Computarizada (CT)
La CT permite visualizar con alta resolución huesos, pulmones y vasos sanguíneos, siendo fundamental en urgencias médicas y en la planificación de tratamientos como la radioterapia. Emplea rayos X y produce imágenes detalladas del cuerpo.

Arquitectura
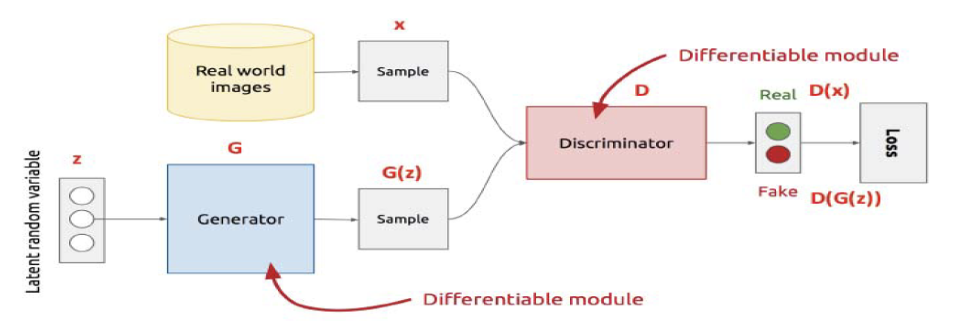
La arquitectura de MedCycleGAN surge como una combinación estratégica entre la estructura de entrenamiento no pareado de CycleGAN y la potencia generativa de MedGAN [3]. El objetivo es obtener imágenes sintéticas de alta calidad sin la necesidad de datasets emparejados, una limitación importante en entornos médicos reales.
Dataset y configuración
En esta implementación, los modelos fueron entrenados con 1595 imágenes por dominio, sin emparejamiento directo. El entrenamiento sigue el flujo estándar de CycleGAN, pero se beneficia de la mayor capacidad de modelado de CasNet para refinar progresivamente los detalles anatómicos de las imágenes generadas
Generadores con arquitectura CasNet
El elemento central del modelo generador es CasNet (Cascaded U-Net), introducido originalmente en MedGAN. Esta arquitectura consiste en una secuencia de U-Nets encadenadas, donde la salida de una U-Net es usada como entrada de la siguiente. Cada U-Net tiene la capacidad de preservar detalles espaciales mediante skip connections, lo que favorece la reconstrucción estructural en imágenes médicas. En el modelo original, se empleaban 6 U-Nets, pero en esta implementación se ha reducido a 3 U-Nets para disminuir la carga computacional sin comprometer drásticamente la calidad [3].
Formalmente, si denotamos una U-Net como UUU, y una entrada xxx del dominio fuente (por ejemplo, MR), el generador actúa como:

donde GGG representa el generador completo. Cada U-Net es un autoencoder con convoluciones convolutivas y deconvolutivas simétricas, seguidas de normalización y activaciones ReLU o LeakyReLU.
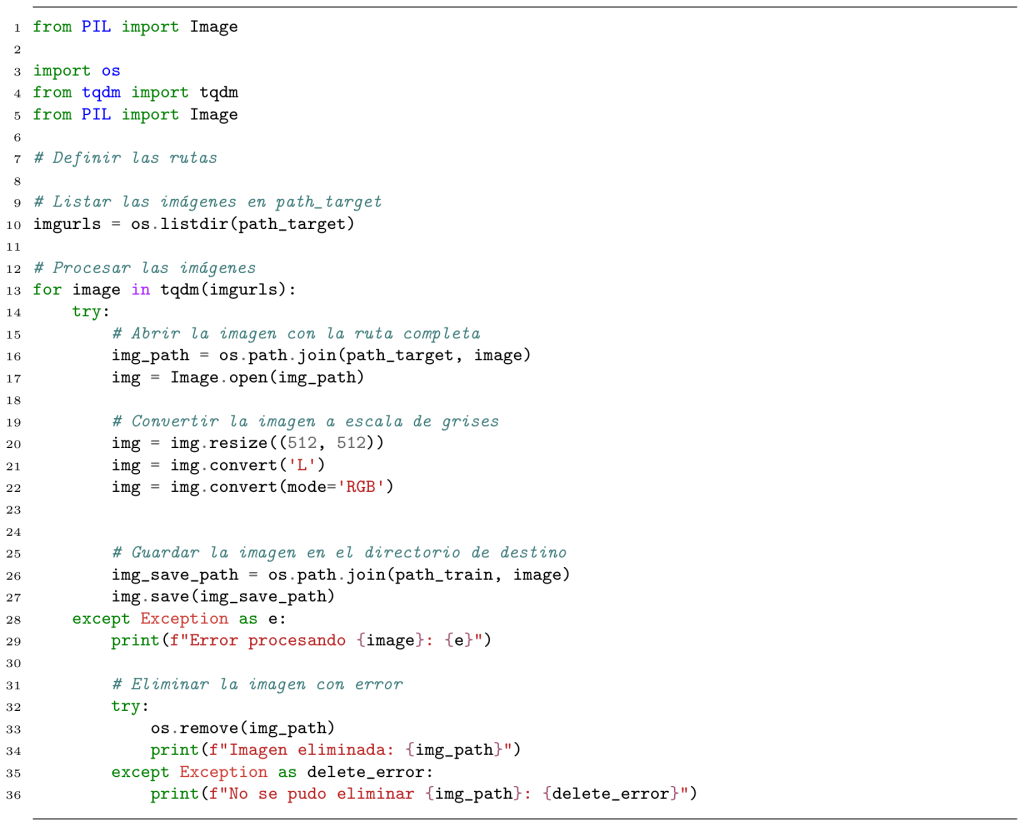
El código que utilizamos para el generador está compuesto por las siguientes celdas las cuales las explicaremos una a una tras mostrarlas:

Esto reduce el tamaño espacial sin sesgo pero aumenta la profundidad también. Se utiliza la normalización por lotes para estabilizar el entrenamiento.

Esta función ayuda a reconstruir detalles finos que se pierden en el encoding. Utiliza Conv2DTranspose para aumentar la resolución.

Construimos una U-Net completa aplicando 8 bloques encoder (el último sin conexión skip), reconstruyendo la imagen pasando por 7 bloques decoder y rehusando los skip connections.

Define los tamaños de los encoder y decoder, y construye un modelo de Keras.
Funciona de manera que, si tienes una imagen de entrada de tamaño 256×256, este generador la transforma mediante 3 pasos U-Net, comprimiendo y descomprimiendo con saltos de conexión, buscando generar una imagen sintética coherente con los datos reales.
Discriminador
El discriminador en MedCycleGAN se mantiene deliberadamente ligero, con tres capas convolucionales, lo que recuerda a la arquitectura de PatchGAN utilizada en CycleGAN. Su función no es clasificar la imagen entera como real o falsa, sino verificar patches locales, lo cual es más efectivo en imágenes médicas donde los detalles estructurales finos son relevantes [4]. Esta elección arquitectónica reduce significativamente el tiempo de entrenamiento y evita el sobreajuste, especialmente con datasets pequeños.
Flujo cíclico y consistencia
Como en CycleGAN, se utiliza un enfoque bidireccional:
- Un generador G: X→ Y : X (por ejemplo, MR → CT)
- Un generador inverso F: Y→X
- Dos discriminadores Dx y Dy para cada dominio.
Se aplica una pérdida adversarial sobre cada par (G, Dy) y (F, Dx), y una pérdida de consistencia cíclica

Esto obliga al sistema a mantener información relevante entre las transformaciones, asegurando que la ida y vuelta entre dominios no distorsione los datos originales.

Nuestro código del discriminador aplica una arquitectura tipo PatchGAN, evaluando pequeñas regiones de la imagen para determinar si son reales o generadas.
Usa convoluciones con normalización y activación LeakyReLU para extraer características, terminando con una salida sigmoid que da probabilidades por parche.
Esta combinación permite generar imágenes de alta calidad con coherencia visual y detalles consistentes.
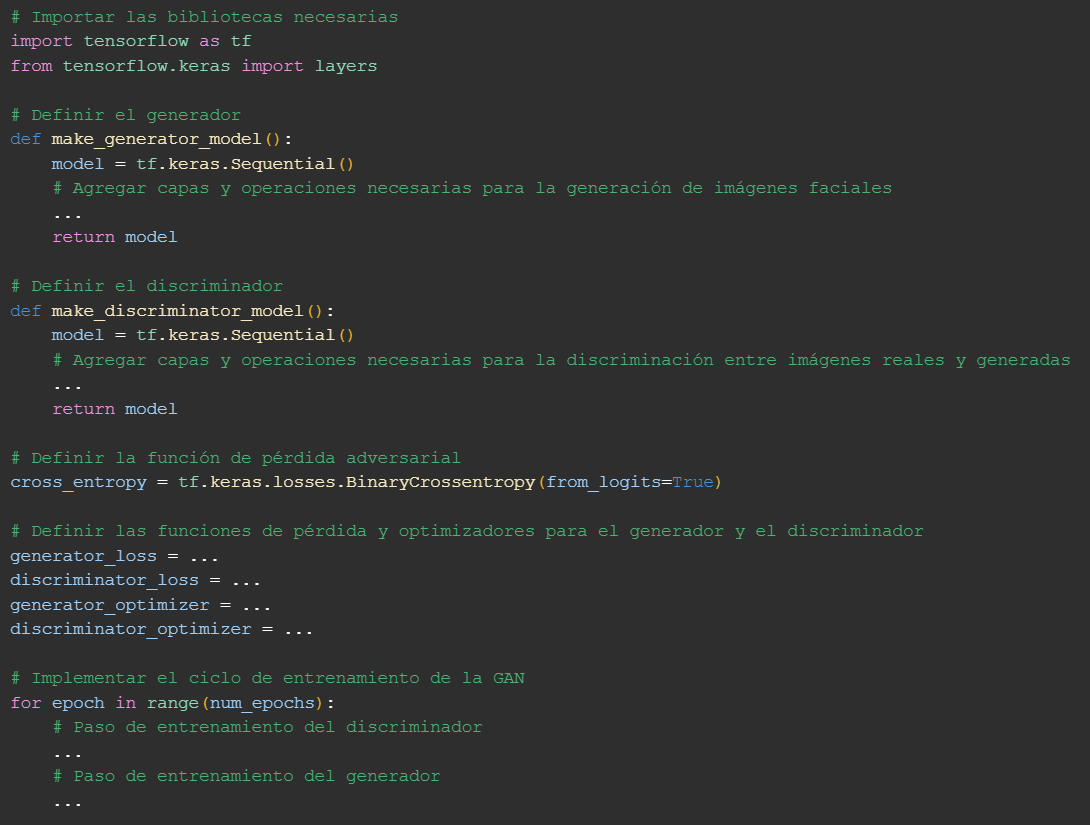
Entrenamiento
El entrenamiento se basó en una arquitectura tipo CyvleGAN con dos generadores y dos discriminadores, permitiendo la conversión bidireccional entre dominios de imagen.
Se utilizaron pérdidas adversariales junto con pérdidas de ciclo y de identidad para asegurar coherencia estructural y fidelidad en la transformación.
El optimizador Adam, con parámetros ajustados, garantiza una convergencia estable. Cada paso de entrenamiento actualiza todos los modelos simultáneamente usando tf.GradientTape y los checkpoints permiten continuar el entrenamiento sin pérdidas.
Los resultados visuales por época muestran una mejora progresiva en la calidad de las imágenes generadas.
Testing MR images
La figura muestra imágenes reales de resonancia magnética frente a las generadas por el modelo. Se aprecia que el modelo reproduce con buena fidelidad la estructura cerebral, lo que demuestra su capacidad para generar imágenes médicamente coherentes a partir de datos sintéticos.



Testing PET images
Las imágenes muestran comparaciones entre datos PET reales (izquierda) y generados (derecha). El modelo logra replicar correctamente las regiones de mayor actividad metabólica, conservando la estructura general y la distribución de intensidades, clave para el análisis funcional.



Discusión
Los resultados obtenidos con imágenes MR y PET muestran que el modelo MedCycleGAN es capaz de generar imágenes sintéticas con una estructura anatómica y funcional coherente en comparación con las imágenes reales. En el caso de las MR, las imágenes generadas preservan bien los contornos cerebrales y detalles relevantes, lo que sugiere una buena capacidad del modelo para mantener la integridad espacial.
Para las PET, aunque la resolución original es menor y el ruido es más evidente, las imágenes generadas reproducen con acierto las zonas de alta actividad metabólica, lo cual es esencial en contextos oncológicos o neurológicos. Esto indica que el modelo no solo transfiere el estilo, sino también información clave para el análisis clínico.
En conjunto, estos resultados apoyan la utilidad del modelo como herramienta para aumentar la resolución, generar datos sintéticos para entrenamiento y reducir la necesidad de escaneos múltiples, con un impacto potencial en la mejora de calidad diagnóstica y eficiencia clínica.
BIBLIOGRAFÍA
1. Osuala, R. et al. (2022). medigan: a Python library of pretrained generative models for medical image synthesis. arXiv. https://arxiv.org/abs/2203.13765
2. Khader, F. et al. (2022). Medical diffusion: Denoising diffusion probabilistic models for 3D medical image generation. arXiv. https://arxiv.org/abs/2211.07804
3. Armanious, K., Jiang, C., Fischer, M., Küstner, T., Hepp, T., Nikolaou, K., … & Yang, B. (2020). MedGAN: Medical Image Translation using GANs. Computerized Medical Imaging and Graphics, 79, 101684. https://doi.org/10.1016/j.compmedimag.2020.101684
4. Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. In ICCV 2017. https://arxiv.org/abs/1703.10593
Datasets
Imágenes MRI y PET descargadas en OASIS 3, requiere un registro para descargarlas https://sites.wustl.edu/oasisbrains/home/oasis-3
Imágenes CT descargadas de Qure.ai https://web.archive.org/web/20220816011051/http://headctstudy.qure.ai/
Este blog ha sido creado por Antonio Verdú, José Ángel Bello y Jaime Sichar