Introducción
En el campo del procesamiento avanzado de señales y datos, una de las tecnologías más innovadoras y prometedoras que ha surgido en los últimos años son las Redes Adversarias Generativas, comúnmente conocidas como GANs. Estas redes neuronales han revolucionado la manera en que generamos y procesamos información, abriendo un abanico de posibilidades en campos como la visión por computadora, la generación de contenido creativo y la simulación de datos realistas.
La generación de imágenes realistas de rostros humanos ha sido durante mucho tiempo un desafío en el campo del aprendizaje automático. Sin embargo, gracias a los avances en las GANs, ha surgido una técnica revolucionaria que ha permitido la creación de imágenes faciales sorprendentemente realistas a partir de datos aleatorios. En esta entrada de blog, exploraremos el enfoque específico de la generación de caras mediante GANs, examinando los avances más destacados, las técnicas utilizadas y los desafíos pendientes. Nos centraremos en aspectos clave, como el uso de arquitecturas específicas como StyleGAN, la mejora de la calidad de las imágenes generadas y la manipulación de atributos faciales.

Estado del arte
Antes de sumergirnos en el funcionamiento y las aplicaciones de las GANs, es importante realizar una breve revisión del estado del arte en este campo. Desde su introducción por Ian Goodfellow en 2014, las GANs han captado rápidamente la atención de la comunidad científica y tecnológica. Diversos avances han permitido mejorar la estabilidad y la calidad de las generaciones, así como la capacidad de aprender y representar distribuciones complejas de datos. Estos avances han dado lugar a aplicaciones sorprendentes en áreas como la síntesis de imágenes, el procesamiento de voz y el diseño de fármacos, entre otros. [1]
Una arquitectura que ha destacado es StyleGAN, que permite el control y la manipulación fina de los atributos faciales en las imágenes generadas. Además, la incorporación de técnicas como la normalización por lotes estilizada (Style-based Batch Normalization) y el uso de redes generadoras y discriminadoras de múltiples escalas ha mejorado aún más la calidad y la diversidad de las imágenes generadas. [2]
Desarrollo
Las GANs se basan en un enfoque novedoso que involucra la interacción entre dos redes neuronales: el generador y el discriminador. El generador tiene como objetivo crear muestras sintéticas que se asemejen a las muestras reales, mientras que el discriminador busca distinguir entre las muestras generadas y las reales. Ambas redes se entrenan de manera simultánea, en un proceso de competencia adversarial, donde el generador busca engañar al discriminador y, este último, trata de mejorar su capacidad de discriminación.
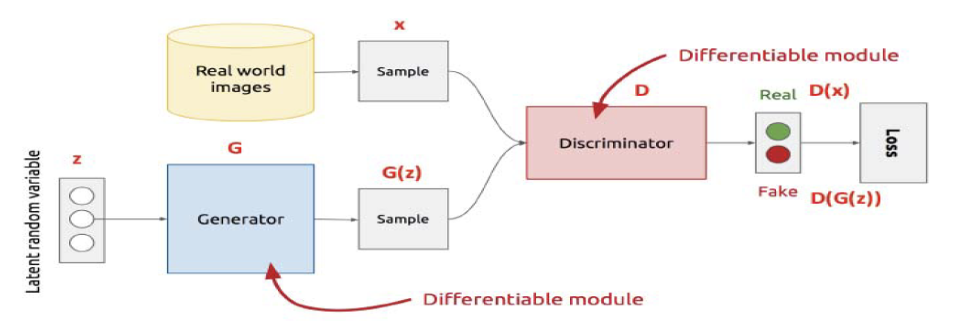
En el proceso de generación de caras mediante GANs, el generador mapea un espacio latente de datos aleatorios a imágenes de caras realistas. El discriminador, por su parte, se entrena para distinguir entre imágenes generadas y reales.
El enfoque de StyleGAN ha permitido avances notables en la generación de caras realistas. Al introducir una descomposición de estilo en el generador, se puede controlar de manera más precisa el aspecto de las imágenes generadas, como la edad, el género, la expresión facial y otros atributos específicos. Además, la incorporación de técnicas de normalización por lotes estilizada y la generación en múltiples escalas ha llevado a una mejora significativa en la calidad visual y la diversidad de las imágenes generadas.
Materiales
El uso de derivaciones matemáticas es fundamental para comprender el funcionamiento de las GANs y optimizar su entrenamiento. La minimización de una función de pérdida, como la divergencia de Kullback-Leibler o la pérdida de Wasserstein, permite establecer una dinámica de aprendizaje entre el generador y el discriminador. Estos conceptos matemáticos fundamentales se ven reflejados en el código de implementación de las GANs, que consta de la definición de las arquitecturas de las redes, la elección de la función de pérdida y la configuración de los hiperparámetros.
La generación de imágenes realistas se logra mediante la minimización de la función de pérdida adversarial. La función objetivo se define como:
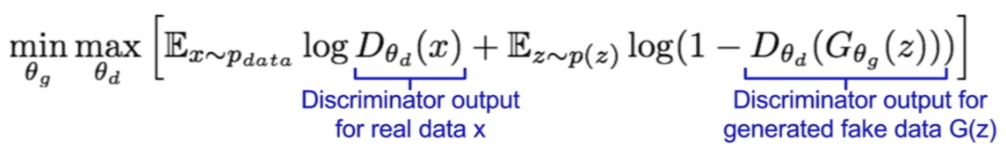
Donde D(x) es la estimación del discriminador de la probabilidad de que la instancia de datos reales x sea real, Ex es el valor esperado sobre todas las instancias de datos reales, G(z) es la salida del generador cuando se da ruido z, D(G(z)) es la estimación del discriminador de la probabilidad de que una instancia falsa sea real, Ez es el valor esperado sobre todas las entradas aleatorias al generador (en efecto, el valor esperado sobre todas las instancias falsas generadas G(z)). pdata es la distribución real de los datos y p(z) es la distribución de ruido latente. [11]
El generador intenta maximizar esta función de pérdida mientras que el discriminador intenta minimizarla, creando la competencia adversarial.
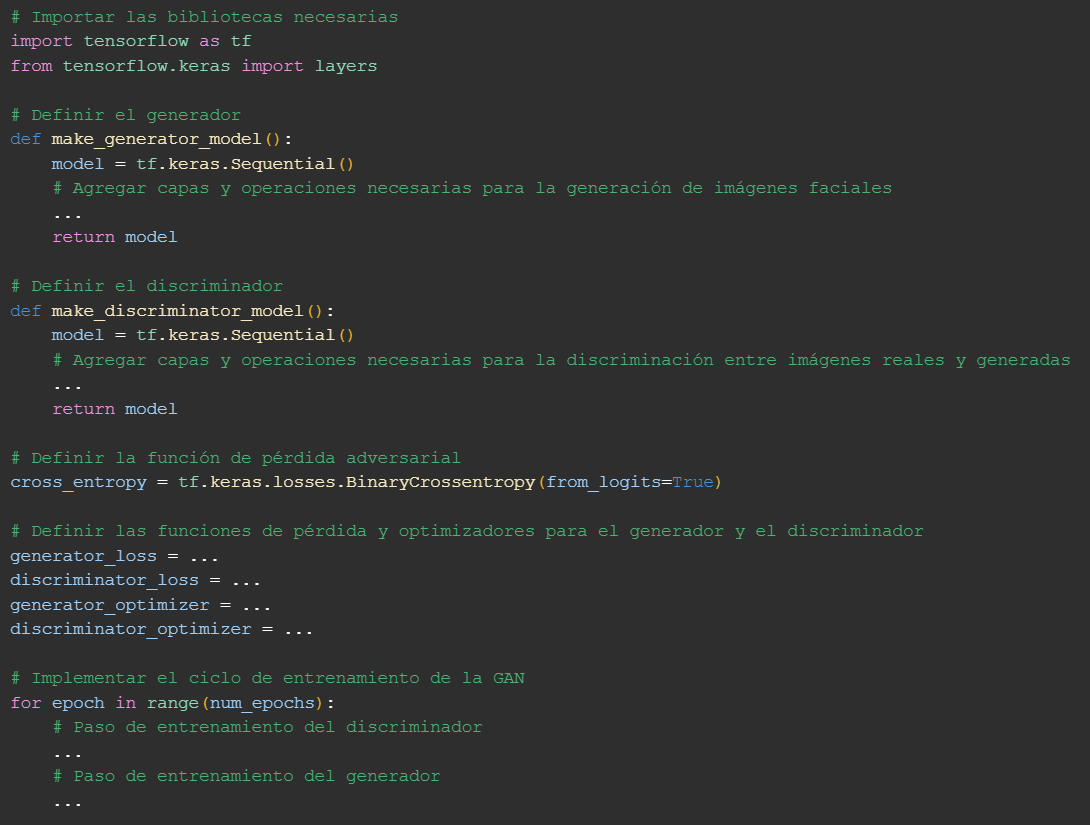
A continuación, se presenta un ejemplo de estructura de una implementación básica de una GAN para la generación de caras utilizando la biblioteca de Python TensorFlow:
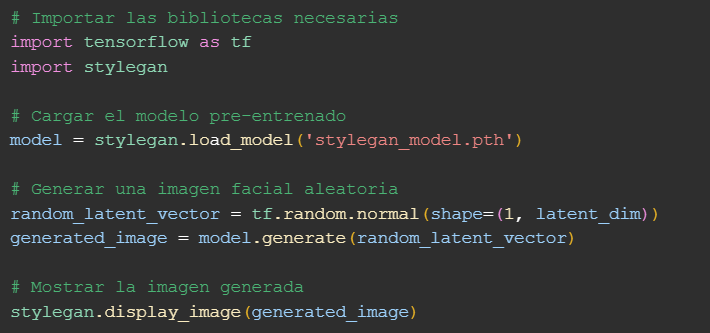
Y, usando la arquitectura StyleGAN:
Discusión de los resultados
La potencia de las GANs se hace evidente al observar los resultados obtenidos en diversos experimentos. Mediante la aplicación de GANs, se ha logrado generar imágenes hiperrealistas, imitar el estilo de artistas famosos, completar imágenes dañadas o faltantes, e incluso simular la evolución de enfermedades en datos médicos.
Se han logrado imágenes faciales altamente realistas, con detalles finos y una calidad visual sorprendente. Además, la capacidad de controlar los atributos faciales ha permitido la creación de imágenes personalizadas y la manipulación de características específicas.
Sin embargo, a pesar de estos avances, aún existen desafíos importantes que deben abordarse en la generación de caras mediante GANs. Uno de estos es lograr una mayor estabilidad en el entrenamiento de los modelos. A veces, las GANs pueden ser difíciles de entrenar y pueden sufrir de problemas como el colapso del modo, donde el generador produce imágenes similares y de baja diversidad. También es fundamental mejorar la interpretabilidad de los modelos y garantizar la ética en la generación de caras, evitando posibles sesgos y discriminación involuntaria. [6]
A continuación, se muestran algunos ejemplos de imágenes generadas utilizando una GAN entrenada para la generación de caras. Estas imágenes demuestran la capacidad de las GANs para producir resultados visualmente atractivos. Además, se pueden proporcionar métricas de evaluación, como el puntaje de Inception (Inception Score), para cuantificar la calidad y la diversidad de las imágenes generadas.

Conclusiones
Las Redes Adversarias Generativas han revolucionado el procesamiento de señales y datos, ofreciendo una poderosa herramienta para la generación y simulación de información compleja. Su capacidad de aprender y representar distribuciones de datos complejas ha permitido avances significativos en campos como la visión por computadora, la creatividad computacional y la generación de contenido realista.
La generación de caras mediante GANs ha alcanzado niveles sorprendentes de realismo y control de atributos faciales. La arquitectura StyleGAN ha sido un avance significativo en este campo, permitiendo una generación más precisa y diversa. Sin embargo, aún existen desafíos a superar, como la estabilidad del entrenamiento y la ética en la generación de imágenes faciales. La investigación continua se centra en mejorar estos aspectos y abrir nuevas posibilidades en la generación de caras.
Los avances en esta área de investigación continúan abriendo nuevas posibilidades en el campo del procesamiento avanzado de señales y datos. A medida que se superan los desafíos restantes, se espera que las GANs sigan evolucionando y proporcionando resultados aún más impresionantes.
Referencias
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680). [Enlace]
[2] Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4401-4410). [Enlace]
[3] Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2020). Training generative adversarial networks with limited data. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5937-5947). [Enlace]
[4] Zhao, S., Liu, Z., & Shen, X. (2021). Learning to Generate Faces: A Survey. arXiv preprint arXiv:2103.01763. [Enlace]
[5] Brock, A., Donahue, J., & Simonyan, K. (2018). Large scale GAN training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096. [Enlace]
[6] Brock, A., Donahue, J., & Simonyan, K. (2019). Large scale GAN training for high fidelity natural image synthesis. In International Conference on Learning Representations. [Enlace]
[7] Arjovsky, M., & Bottou, L. (2017). Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862. [Enlace]
[8] Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., & Metaxas, D. N. (2018). Self-attention generative adversarial networks. In International Conference on Machine Learning (pp. 7354-7363). [Enlace]
[9] Huang, X., Li, Y., Poursaeed, O., Hopcroft, J., & Belongie, S. (2017). Stacked generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition (pp. 6487-6495). [Enlace]
[10] Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In International conference on machine learning (pp. 214-223). [Enlace]
[11] Kaggle – Fake Faces with DCGANs. [Enlace]
[12] Moodle – Signals and Data Advanced Processing. Part1, Chapter 3: Deep Generative Models. 3.4. Generative Adversarial Networks. [Enlace]