El aprendizaje automático es una rama de la Inteligencia Artificial que permite que un sistema aprenda y mejore de forma autónoma, mediante técnicas como las redes neuronales y el aprendizaje profundo, sin tener que ser programado explícitamente. Con el desarrollo de nuevas técnicas dentro de este campo, van saliendo nuevos problemas que buscan desafiar la forma en la que las máquinas aprenden los algoritmos, no solo para solucionar dichos problemas, sino para mejorar la eficiencia y el rendimiento con el que lo hacemos.
Uno de esos nuevos problemas, el cual ganó bastante popularidad en las redes a mediados de 2016, es el famoso problema ‘Muffin VS Chihuahua’. Se presenta una serie de imágenes de perros (más concretamente de Chihuahuas) y de magdalenas de arándanos, y el objetivo es que la máquina sea capaz de identificar qué imágenes son de perros y cuáles de muffins. Este caso no es más que un ejemplo de un problema mayor, que lleva varios años siendo estudiado y abordado mediante varios métodos y técnicas dentro del área del aprendizaje automático: que una máquina sea capaz de identificar y clasificar imágenes correctamente.

En este blog, abordaremos el problema del Muffin Chihuahua haciendo uso de tres grandes campos dentro del aprendizaje automático, que solaparemos entre ellos para cumplir el objetivo de identificar si la imagen es de un perro o de una muffin. Estos son los campos del aprendizaje profundo, el aprendizaje por transferencia, y el aprendizaje multi-tarea.
1. Estado del arte
Para enfrentarnos a este problema, empezamos tratando de responder a la siguiente pregunta: ¿Cuáles son las técnicas disponibles en el campo del aprendizaje automático?
Después de explorar las diferentes alternativas existentes dentro del aprendizaje profundo, decidimos centrarnos en en el aprendizaje por transferencia y aprendizaje multi-tarea.
Aprendizaje por transferencia [2]
El aprendizaje por transferencia hace referencia a aquel aprendizaje que hace uso de parte del conocimiento adquirido por un algoritmo para otro. En vez de empezar completamente desde cero, aprovechas las arquitecturas y los pesos de tareas y dominios parecidos para tu propia tarea y dominio.
Aprendizaje multi-tarea [3]
El aprendizaje multitarea consiste en entrenar un modelo para realizar múltiples tareas relacionadas simultáneamente. A diferencia del enfoque tradicional de entrenar modelos separados para cada tarea, el aprendizaje multitarea busca aprovechar las similitudes entre las tareas para mejorar el rendimiento global. Las tareas comparten un conjunto común de características aprendidas por el modelo. Estas actúan como un vínculo entre las diferentes tareas, permitiendo que el conocimiento adquirido en una tarea influya en el rendimiento de las demás tareas[4]. De esta manera, podemos evitar los principales problemas que nos encontramos a la hora de crear nuevas redes neuronales: el elevado tiempo que requiere entrenarla y la baja cantidad de datos que suele haber para el entrenamiento de una nueva tarea.
Dentro de este campo, hay un espectro de posibles formas de implementar dicho aprendizaje[5]. En los extremos de dicho espectro se encuentran el hard parameter sharing y el soft parameter sharing. [6]
El “hard parameter sharing” es una técnica en el campo del aprendizaje automático que implica compartir los mismos pesos y conexiones en diferentes partes de una red neuronal. A diferencia de tener parámetros separados para cada tarea o módulo, se comparten los mismos parámetros entre ellos. Esta estrategia resulta especialmente útil cuando se trabaja con múltiples tareas relacionadas que comparten características comunes. Al compartir los parámetros, se aprovecha el conocimiento aprendido en una tarea para mejorar el rendimiento en otra tarea, logrando así una mejor utilización de los recursos computacionales y una mayor generalización del modelo.
El hard parameter sharing tiene la ventaja de poder aprender representaciones compartidas, es decir, la red neuronal puede capturar características útiles que son relevantes para todas las tareas. Esto resulta especialmente beneficioso cuando las tareas están estrechamente relacionadas y comparten patrones subyacentes. Al compartir los parámetros, la red puede aprender estas características de manera más efectiva. No obstante, existen limitaciones en esta técnica. Por ejemplo, si las tareas son muy diferentes entre sí y requieren representaciones muy distintas, el hard parameter sharing puede no ser la opción más adecuada. Además, si una tarea dominante está presente y domina a los demás módulos, el rendimiento en las tareas secundarias puede verse afectado negativamente.
La estructura que suele presentar es la siguiente:
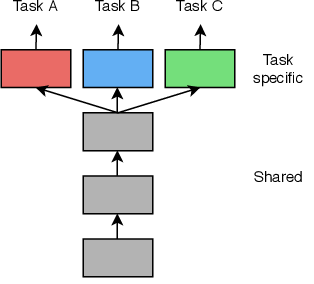
Las primeras capas de la red son compartidas entre todas las tareas. Por ello, los parámetros y los pesos obtenidos en dichas capas son iguales para todas las tareas y no hacen distinción. Es en las últimas capas donde nos centramos en extraer las características para cada tarea en concreto, obteniendo cada una de ellas sus propios pesos y resultados.
Por otro lado, tenemos el “soft parameter sharing”, que se podría considerar el otro extremo del espectro del aprendizaje multitarea. En vez de tener una sola estructura, una sola red para todas las tareas, tendremos una red individual para cada una de ellas. A pesar de ello, todavía buscamos que los parámetros de todas las redes se parezcan un poco. En el caso anterior, los parámetros se compartían directamente, pero con esta técnica, utilizaremos mecanismos de penalización para conseguir que los parámetros correspondientes se parezcan más entre sí. De esta manera, conseguimos una mayor adaptabilidad y capacidad de fine-tuning, ya que el algoritmo se beneficia de la transferencia de conocimiento mientras mantiene la capacidad de aprender características distintas en cada parte específica de la tarea.
El soft parameter sharing[8] es una técnica muy amplia y diversa en su propio campo, por lo que las formas de implementarla son múltiples. Al igual que en el hard parameter sharing, es el desarrollador el que toma decisiones de diseño, como que se comparta el conocimiento entre capas. A pesar de ello, podemos definir una estructura general, la cual es la siguiente:
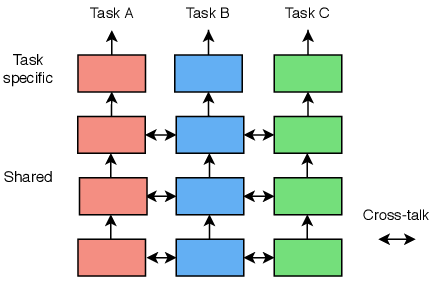
En esta podemos ver que se puede compartir el conocimiento adquirido de las primeras capas de cada red y dejar las últimas para que sean específicas para cada tarea.
2. Desarrollo
Una vez realizada la investigación para identificar la situación actual y las diferentes técnicas que pueden ser usadas para nuestro problema, podemos comenzar a desarrollar nuestro trabajo. Para ello, necesitaremos poner en práctica la información obtenida en el apartado anterior y encontrar el material necesario. Más concretamente, podemos dividir el desarrollo de esta trabajo en dos partes:
- ¿Cuáles son los recursos disponibles sobre este problema?
- Implementación de las técnicas sobre el problema.
2.1 ¿Cuáles son los recursos disponibles sobre este problema?
Empezamos haciendo una búsqueda sobre los recursos disponibles sobre el problema del Muffin Chihuahua [1]. Dado que lo que pretendíamos era entrenar un algoritmo para aprender a diferenciarlos, necesitábamos tener los suficientes datos para dicho entrenamiento. Por ello, empezamos viendo qué datos había disponibles para dicha labor.
Al ser un problema conocido dentro del campo del aprendizaje automático, el número de artículos sobre el mismo es abundante. Incluso hay varios apartados en la comunidad de Kaggle[8] orientados a la resolución de este problema. Dichos apartados fueron un punto de partida para la investigación para este blog[9]. En especial nos interesaron aquellos resultados que hacían uso de redes neuronales, ya que nuestro primer objetivo era aplicar aprendizaje profundo para resolver el problema.
Encontramos así una base de datos abierta en el propio Kaggle con 5917 imágenes de chihuahuas y muffins[10]. Esta será el material utilizado para el algoritmo.
2.2 Implementación de las técnicas sobre el problema.
Una vez definidos los recursos del problema y las técnicas que queremos aplicar para tratar de resolver el mismo, combinamos el conocimiento adquirido para aplicarlo a la práctica. Lo que decidimos hacer fue hacer uso de las redes ya entrenadas en los códigos del Kaggle[9] para aplicar aprendizaje por transferencia. Sobre los pesos congelados de esa red, aplicaríamos después los dos extremos del aprendizaje multitarea. En el caso de hard parameter sharing, las capas compartidas entre tareas serían aquellas congeladas del algoritmos entrenado previamente y las capas específicas para cada tarea serían entrenadas por separado. En el caso del soft parameter sharing, en vez de enfocarlo con conocimiento compartido entre las distintas redes, decidimos implementarlo congelando las primeras capas con los pesos del algoritmo entrenado y dejar el resto de capas entrenarse específicamente para la tarea de cada una de las redes, haciendo así un modelo híbrido más asequible teniendo en cuenta que no contamos con recursos computacionales muy potentes.
Para implementar esto, hicimos uso de un código base desarrollado en Kaggle[10.1] que conseguía una exactitud del 90% en la clasificación. Dicho código implementaba una red convolucional para resolver el problema. Además, la forma en la que cargamos y evaluamos los datos se basó en dicho código también. El código implementa pytorch en vez de keras, pero al estar más familiarizados con la segunda, decidimos adaptarlo a dicha librería.
Debido a que muchas de las decisiones tomadas para el trabajo se basan en este código, explicaremos a continuación el contenido del mismo. Muchos cambios han sido realizados sobre este código para adaptarlo, así que mencionaremos en detalle solamente aquellas partes del código que utilizamos nosotras a la hora de desarrollar el propio. El notebook está dividido en 5 partes.
Comienza con una breve introducción en la que define los conjuntos de train y de test. Nosotras realizamos esto mismo de la misma forma. Primero define la función build_metadata(), la cual tiene como objetivo coger una ruta donde están los datos y devolver un dataframe donde tenemos una columna con los datos (en este caso las imágenes) y otra columna con las etiquetas de estos.

Una vez tiene la función, como el Kaggle proporciona el dataset de imágenes tanto de entrenamiento como de test, llama a esta función para ambos, definiendo así los dataframe de train y test.

Termina la introducción cambiando las etiquetas. Las etiquetas son strings que marcan ‘muffin’ o ‘chihuahua’. Lo que hace es cambiarlo a valores numéricos para poder trabajar mejor con ellas. Quedan así los mismos dataframes pero la columna de ‘label’ es una colección de 0 (muffin) y 1 (chihuahua).

Una vez definido esto pasa a la siguiente parte del notebook, que está dedicada a definir clases a las que se llamarán para conseguir el dataset de imágenes en el formato deseado y conseguir dataloaders. En nuestro caso, esto lo hacemos de manera distinta por lo que el código desarrollado en el notebook en esta sección no es de especial interés de cara a entender el por qué del código desarrollado por nosotras.
La siguiente sección, sin embargo, si que vuelve a ser de interés, ya que define el modelo. Como dicho anteriormente este modelo será la base de nuestros modelos de multitask, entrenaremos este y luego congelaremos las capas para quedarnos con parte de su arquitectura. A pesar de que está definido en PyTorch y nosotras lo adaptamos a keras, la arquitectura es la misma.

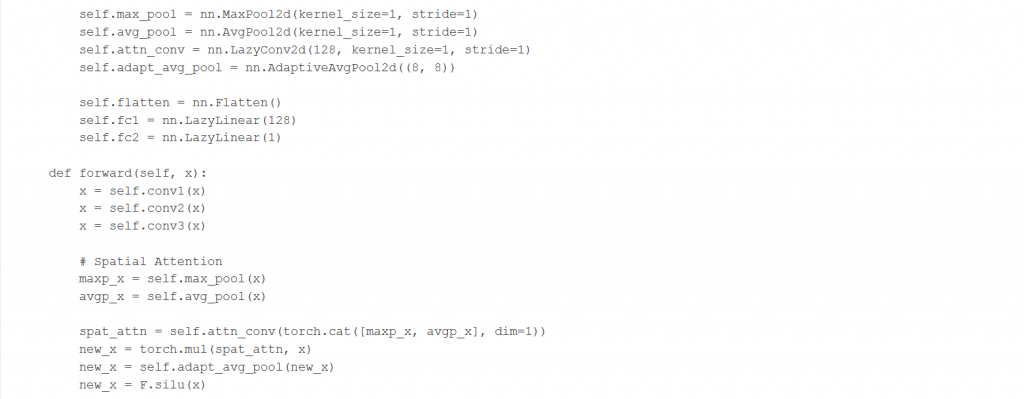

Define la red como una serie de convoluciones combinadas con capas de MaxPooling y normalización del Batch. Además, dentro de la clase define una serie de funciones que marcan el tamaño de los pasos de train, test y validación. Eso no lo aplicaremos en nuestro código, por lo que no entraremos en detalle. A partir de aquí además, lo restante del código está completamente cambiado y muchas partes no son de utilidad para nosotras.
El desarrollo que se siguió para obtener el código y los resultados que se verán en detalle en la siguiente parte partieron de este código. Teniendo los datos cargados y entrenados, guardamos los pesos de la red para poder hacer el aprendizaje por tranferencia con dichos pesos aprendidos. Una vez hecho eso, y una vez adaptado el código, tomamos las dos rutas explicadas anteriormente. En el caso del hard parameter sharing, congelamos todas las capas salvo las 7 últimas, las cuales serían las capas task specific. En el caso del soft parameter sharing, decidimos congelar incluso menos capas y jugar con redes más distintas entre sí, por lo que solamente congelamos las 5 primeras capas del modelo entrenado y las demas las adaptamos a los que buscábamos.
Una vez hecho esto, sacamos varias métricas sobre los modelos para comparar los resultados no solo entre el hard y el soft parameter sharing, sino también con la red original, para ver si aplicar estas técnicas de transfer learning y multitask learning verdaderamente suponen una mejora sobre la red solamente.
Proceso hard
La implementación de la teoría al código empieza con la definición de muestro modelo, el cual definimos en la función create_multi_task_learning_model() de nuestro código.
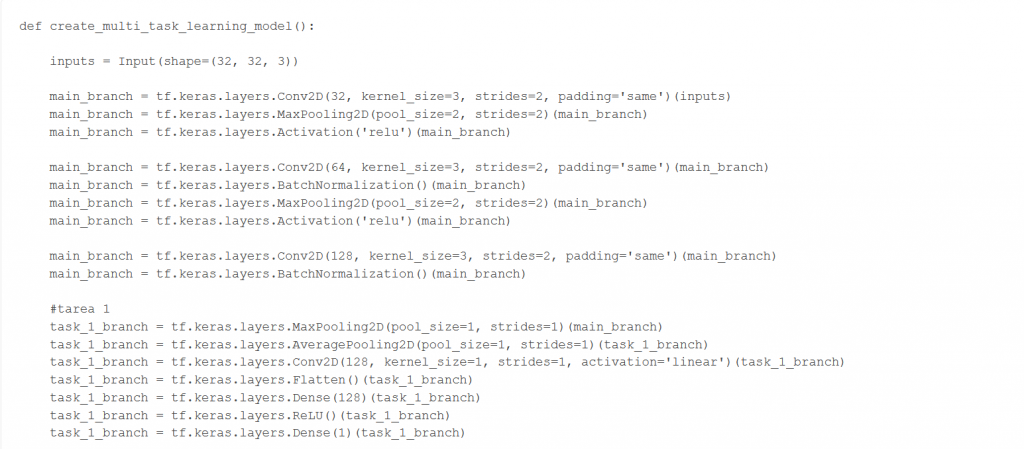
Para aplicar Hard parameter sharing en multi-task learning (MTL), partimos de un modelo base (el definido), al que nos referiremos como main_branch. En este, tenemos capas convolucionales con los parámetros que compartirán nuestras tareas. Este será el modelo que entrenamos con el objetivo de obtener los pesos y congelarlos sobre las capas de nuestra arquitectura de Hard Parameter Sharing.
Cargamos los datos de entrenamiento y de validación, definimos un modelo, compilamos, entrenamos y evaluamos:
Los pesos del modelo los guardamos en un archivo para poder cargarlos en la futura arquitectura.

Ahora, podemos añadir nuevas tareas.
Estas tareas, denotadas como task_1_branch, task_2_branch y task_3_branch, comparten la estructura inicial, pero tienen sus propias capas finales las cuales se encargarán de obtener diferentes características y las cuales tendrán sus propios parámetros (a los que se sumarán los parámetros de la red base).
- Tarea 1: Decidimos mantener la primera tarea con el modelo original, para incluirlo con todas las capas originales en la nueva arquitectura.
- Tarea 2: Capa de max pooling y average pooling para reducir la dimensionalidad. Luego, aplicamos una capa de convolución lineal y una capa Flatten para generar un vector a la salida. Aplicamos después una capa Dense con 128 neuronas y una función de activación ReLU. Tras eso, añadimos la capa de Dropout de 0.2, que lo hacemos para quedarnos con menos neuronas activadas y de esta forma evitar sobre ajuste. Al final, aplicamos una capa Dense de 64 neuronas con función de activación ReLU y otra capa Dense con 1 neurona que produce la salida de nuestro problema.
- Tarea 3: Capa de max pooling y average pooling para reducir la dimensionalidad. Después, añadimos una capa de convolución y capa Flatten. Por último, nos encontramos con una capa Dense con 128 neuronas, una capa de Dropout para quedarnos con menos neuronas activadas y dos capas Dense con 64 y 1 neurona, respectivamente.


En cuanto a los parámetros, la capa principal (main_branch) está formada por 93,248 parámetros y las tareas 1, 2, y 3 están formadas por 332,025, 49.537 y 32.025 parámetros respectivamente.
Creamos un nuevo modelo donde utilizaremos el mismo main_branch del que cargaremos los pesos guardados y le añadiremos 3 nuevas tareas, que detectarán características distintas. Cargamos los pesos del modelo base (las 9 primeras capas).

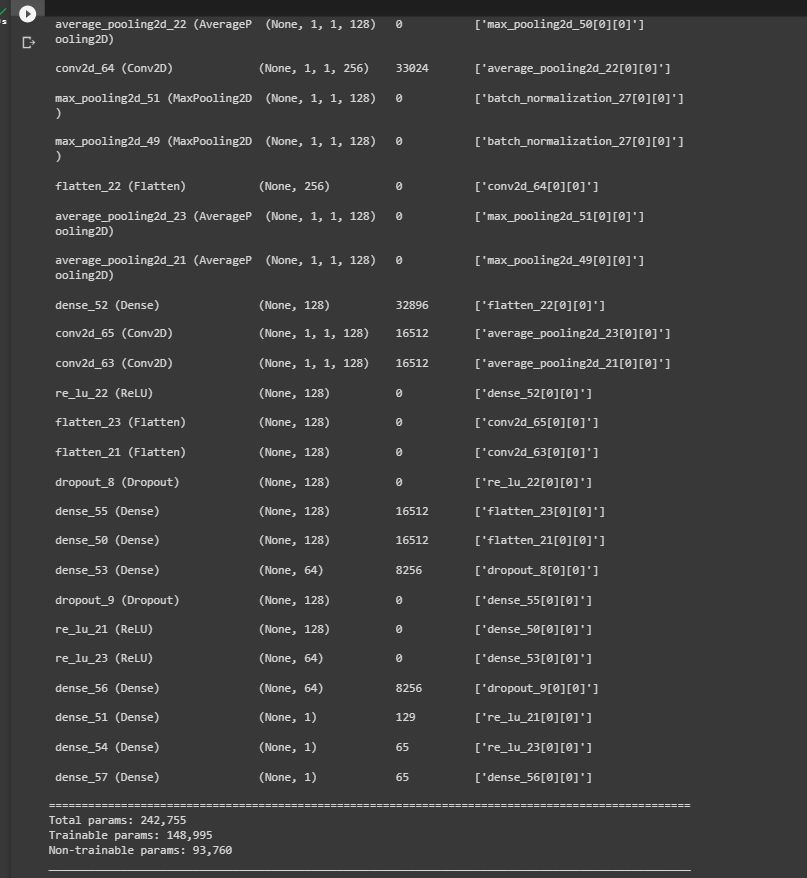
Congelamos las capas del modelo base para que se actualicen los pesos de nuestras tareas con los obtenidos tras el entrenamiento, pero que estos no se cambien al volver a ejecutar la arquitectura (no se entrenen).
Entrenamos el modelo:

Como queremos comparar el rendimiento de ambos casos, con una sola tarea (o modelo original) y con 3 tareas, hemos cogido las mismas métricas para analizarlas: binary_crossentropy como función de pérdida y accuracy como métrica. Además, aplicamos el mismo optimizador ‘Adam’.
Evaluamos resultados:


Resultados y discusión de resultados:
Al haber usado un modelo base cuyo objetivo era clasificar entre un muffin y un chihuaha y nuestras tareas estaban altamente relacionadas, esperabamos un rendimiento bueno al aplicar hard parameter sharing .
Observando los resultados, vemos que en general dan resultados similares, salvo por la tarea 1 que da un accuracy menor que en el modelo original. Esto puede ser debido a que esa tarea fue usada junto al modelo base para sacar los pesos que guardaríamos y ahora al entrenarlo con más tareas, el accuracy se ve afectado.
La tarea 1 parece ser la más desafiante, ya que tiene la pérdida más alta.
La tarea 2 obtiene bastantes buenos resultados, teniendo en cuenta que tiene menos parámetros en comparación con las otras dos tareas con una pérdida de 0.8081 y una precisión de 0.6993.
Por último, la tarea 3 da mejores resultados que en el entrenamiento y test del modelo base (que había obtenido un accuracy de 0.71) con una pérdida de 0.5851 y una precisión de 0.7297
Estos resultados dependen de cómo se definan nuestras tareas y las capas que la componen. En general, podemos concluir que el modelo tiene un desempeño promedio en nuestras tres tareas altamente relacionadas.
Nos hemos ahorrado bastante tiempo de cómputo y de memoria al no tener que entrenar el modelo de cero teniendo los pesos de main_branch guardados. Además, si queremos añadir tareas o utilizar tareas distintas podemos volver a utilizar estos pesos e incluso usar los pesos de alguna tarea y hacer fine-tunning dependiendo de nuestros objetivos
Proceso soft
Hemos tenido algunas dificultades a la hora de implementar este proceso, ya que la documentación y los ejemplos son escasos. Además, se requiere un tiempo y recursos computacionales elevados, algo que no tenemos disponible. Por estos motivos, no hemos logrado obtener resultados para este apartado; sin embargo, describiremos el proceso seguido y el problema principal que nos ha dificultado el desarrollo.
Para ahorrar recursos computacionales, no creamos un modelo soft puro, sino que se definió un híbrido. Comenzaremos de la misma manera que en el hard, con la función create_multi_task_learning_model() para definir nuestro modelo original, cargar los datos de entrenamiento y validación, compilar, entrenar y evaluar.
Una vez hecho esto, crearemos tres nuevos modelos basados en el modelo definido anteriormente, cogiendo las 5 primeras capas y congelándolas (evitando que se entrenen). Para ello, usaremos las siguientes líneas de código:

Repetiremos este proceso para las tres redes, que realizarán una tarea distinta cada una. A continuación, crearemos las capas específicas para cada una de ellas. Serán más abundantes que en el caso anterior, ya que queremos acercarnos lo máximo posible a una arquitectura soft pura.
La tarea 1 estará basada en una red VGG16[15], con una capa lineal, una ReLU, un dropout, otra lineal y por último una función de activación sigmoid. Para hacer las capas lineales en keras, hemos usado una Dense pasando como parámetro 256 píxeles.

La red de la tarea 2 está inspirada por una red EfficientNet [14], que tendrá una normalización, una capa ReLU, un dropout y una capa dense, y repetirá este proceso dos veces.

Por último, en la tarea 3 expandiremos las capas convolucionales[16] que se realizaban en la red original.

Una vez hecho esto, crearemos los nuevos modelos añadiendo a la main branch las tareas nuevas y evaluamos los resultados:


Es aquí donde nos hemos encontrado el siguiente problema:
ValueError: `logits` and `labels` must have the same shape, received ((None, 4, 4, 1) vs (None,)Nos indica que hay una discrepancia entre las formas de los logits (los valores de salida de la red neuronal antes de aplicarles una función de activación) y las etiquetas en la función de pérdida 'binary_crossentropy' (hemos probado con varias funciones de pérdida y el error persistía). Más concretamente, específica que se recibieron logits con forma (None, 4, 4, 1) y etiquetas con forma (None,). Revisamos la forma de crear las variables train_generator, val_generator y test_generator pero no detectamos ningún error. También probamos a cambiar varias secciones del código para modificar los dataframe que se generaban, volvimos a descargar los datos y revisamos el fichero de pesos generado, además de revisar distintos foros[NUM] y páginas de documentación[NUM] para intentar solucionar nuestro problema. Sin embargo, el error persistió.
Discusión de los posibles resultados:
Aunque no hemos conseguido obtener resultados, estudiaremos qué significarían los posibles resultados que podríamos obtener:
La arquitectura soft es mejor que la del modelo original
En este caso, obtendríamos una arquitectura capaz de clasificar mejor entre fotos de chihuahuas y muffins. Esto demostraría que las tareas están relacionadas, y por tanto compartir parámetros mejora nuestros modelos, haciendo que aprendan representaciones más robustas y generales. Además, conseguiríamos aprovechar los datos de manera más eficiente, algo muy útil cuando se cuenta con con un conjunto de datos muy pequeño o desequilibrado (el número de datos varía mucho entre las clases).
Si se diese esta situación, también sería probable que los resultados fuesen mejores a los obtenidos con hard parameter sharing, lo que indicaría que permitir más flexibilidad y capacidad de adaptación en las tareas es beneficioso en este caso. Se da la opción de que las tareas ajusten su propio conjunto de parámetros de manera independiente, por lo que se adapta a sus necesidades específicas y aprende las representaciones especializadas (todo esto manteniendo la compartición de parámetros entre ellas, ya que son tareas relacionadas)
La arquitectura soft es peor que la del modelo original
Podría ocurrir el caso contrario, que los resultado empeorasen frente al modelo original y por tanto frente al hard parameter sharing. Esto podría deberse a varias razones:
- Las tareas son muy diferentes entre sí: Si las tareas no tienen características o patrones comunes, la compartición suave de parámetros puede conducir a una interferencia negativa entre las tareas, afectando al aprendizaje de cada una
- Se produce un sobreajuste: Si el modelo comparte demasiados parámetros o se ajusta mucho a las características específicas de una tarea, se pueden tener dificultades generalizando nuevas imágenes o tareas, empeorando el resultado en el conjunto de test.
- Problemas de convergencia: El soft parameter sharing puede hacer que el modelo sea más complejo y difícil de entrenar, por lo que se corre más riesgo de que el modelo no llegue a converger.
La arquitectura soft y el modelo original obtienen resultados similares
Por último, podría ocurrir que los resultados entre las tres arquitecturas fueran muy similares. Puede ocurrir en dos casos:
- La compartición de parámetros no afecta al rendimiento: Si las tareas no son lo suficientemente similares (no comparten características ni patrones, o no tienen dependencias entre ellas) o compartir parámetros no es necesario para obtener un beneficio significativo, estos procesos no tendrán ningún impacto importante en el rendimiento de nuestro modelo.
- El modelo original ya tenía un rendimiento óptimo: El modelo original ya está diseñado y ajustado de manera óptima, por lo que compartir parámetros no ofrece mejoras adicionales.
3. Conclusión del trabajo
En resumen, en este blog hemos explorado dos de los enfoques más comunes en el multitask learning: Hard y Soft parameter sharing. Hemos visto en detalle su funcionamiento y posteriormente lo hemos aplicado a un problema concreto: diferenciar entre fotos de chihuahuas y muffins.
Para ello, hemos investigado diferentes arquitecturas de redes neuronales, centrándonos en las redes convolucionales debido a su eficacia en el procesamiento y clasificación de imágenes. También hemos revisado diversos recursos y artículos relacionados con el problema ‘Muffin vs Chihuahua’ para obtener información útil y orientación en la implementación de soluciones.
En la implementación del problema, hemos utilizado un conjunto de datos disponible en Kaggle que consta de varias imágenes de chihuahuas y muffins. Hemos adaptado un código base desarrollado en Kaggle, que utiliza redes convolucionales en PyTorch, a la biblioteca Keras para aplicar las técnicas de aprendizaje por transferencia y aprendizaje multi-tarea. También hemos realizado modificaciones en el código para congelar y entrenar diferentes partes de las redes según los enfoques de hard parameter sharing y soft parameter sharing.
Gracias a esto, tenemos un conocimiento mucho más extenso de estas dos técnicas y de las librerías pytorch y keras, que conocíamos de manera muy superficial.
De esta manera, hemos aprendido nuevos recursos para lidiar con problemas como contar con un dataset demasiado pequeño o desequilibrado, algo que consideramos fundamental a la hora de enfrentarnos a situaciones reales en un futuro.
Referencias
- https://www.freecodecamp.org/news/chihuahua-or-muffin-my-search-for-the-best-computer-vision-api-cbda4d6b425d/
- Diapositivas de la asignatura, transfer learning: https://moodle.upm.es/titulaciones/oficiales/pluginfile.php/11029780/mod_resource/content/6/TASD_TransferLearning2.pdf
- Diapositivas de la asignatura, multi-task learning: https://moodle.upm.es/titulaciones/oficiales/pluginfile.php/11029781/mod_resource/content/5/TASD_MultitaskLearning.pdf
- https://avivnavon.github.io/blog/parameter-sharing-in-deep-learning/
- https://avivnavon.github.io/blog/parameter-sharing-in-deep-learning/
- https://medium.com/analytics-vidhya/a-primer-on-multi-task-learning-part-2-a0f00796d0e5
- https://github.com/lolemacs/soft-sharing
- https://www.semanticscholar.org/paper/Revisiting-Multi-Task-Learning-in-the-Deep-Learning-Vandenhende-Georgoulis/6a248e075035cc6f17a64ed4336a507faad1f72e
- https://www.kaggle.com/
- Analizamos código de varios cuadernillos de kaggle:
- https://www.kaggle.com/code/dextermojo/cnn-attention-pytorch-lightning
- https://www.kaggle.com/code/shreyasm/muffin-chihuahua-classifier
- https://www.kaggle.com/code/felixkeith/felix-s-deep-learning
- https://www.kaggle.com/code/hamdi619/muffin-vs-chihuahua-using-resnet50
- https://www.kaggle.com/code/jakubwalczykowski/chihuahua-vs-muffin-round1
- https://www.kaggle.com/code/benjaminlawani/muffin-vs-chihuahua
- https://hipertextual.com/2017/05/deep-learning
- https://www.kaggle.com/datasets/samuelcortinhas/muffin-vs-chihuahua-image-classification
- https://machinelearningmastery.com/how-to-develop-a-convolutional-neural-network-to-classify-photos-of-dogs-and-cats/
- https://keras.io/api/layers/
- https://towardsdatascience.com/complete-architectural-details-of-all-efficientnet-models-5fd5b736142
- https://medium.com/@mygreatlearning/everything-you-need-to-know-about-vgg16-7315defb5918
- https://www.upgrad.com/blog/basic-cnn-architecture/