1. Introduction
CLIP, which stands for “Contrastive Language–Image Pretraining”, is an artificial intelligence model developed by OpenAI that has been trained to understand images and text together. This allows it to perform tasks involving a combination of text and image processing, which sets it apart from many other AI models.
The CLIP model is trained using a method known as “contrastive learning”. This approach involves presenting the model with pairs of images and text that correspond to each other (for example, a picture of a dog and the phrase “a dog”) and pairs that do not correspond (for example, the same picture of a dog and the phrase “a coffee cup”). The model’s goal is to learn to correctly associate images with their corresponding text and reject incorrect pairings.
One of the most interesting aspects of CLIP is that, unlike many AI models that are trained for a specific task, CLIP is capable of performing a wide range of text and image processing tasks without any additional training. This is due to its ability to understand and generate representations of images and text in a shared feature space.
For instance, you could ask CLIP to classify images according to a variety of text descriptions, generate descriptive text for an image, or find the most relevant image for a given phrase. This makes it highly versatile and useful for a variety of applications.
2. State of the art
CLIP model strongly relies on three modern concepts of Artificial Intelligence: Firstly, it uses zero-shot transfer learning so that the model, that has been trained on one task, can later be applied to a different, unseen task without any task-specific training data. Secondly, it uses natural language supervision (human-generated natural language annotations or labels to guide and train machine learning models rather than a set of predefined features) and lastly, it is also a multimodal model since it processes data from two different modalities: text and image.
These disciplines had been explored for the last decade with the main goal of achieving generalised predictions of unseen object categories. One of the most important insights on this line of investigation was leveraged in 2013 by Richer Socher and co-authors at Stanford: They trained a model on CIFAR-10 dataset that was able to make predictions in a word embedding space that was able to predict two unseen classes. In that same year, DeVISE successfully scaled this approach and showcased the feasibility of fine-tuning an ImageNet model, enabling accurate predictions of objects beyond the original 1000 classes in the training set [2].
One of the most inspiring works for CLIP was made by Ang Li and his co-authors at FAIR in 2016 [3]. They made a paper in which they showcased the use of natural language supervision to enable zero-shot transfer learning on popular computer vision classification datasets, including the well-known ImageNet dataset. By fine-tuning an ImageNet CNN with the help of textual information from titles, descriptions, and tags of a vast collection of Flickr photos (around 30 million), they successfully expanded the model’s ability to predict a broader range of visual concepts (visual n-grams). As a result, they achieved an impressive accuracy of 11.5% on zero-shot ImageNet classification.
CLIP belongs to a line of investigation about learning visual representations from natural language supervision. Most of the papers that study this concept use modern AI techniques and architectures such as transformers, autoregressive language modelling, masked language modelling and other approaches of contrastive learning in different fields such as medical imaging [2].
3. Development
3.1. Architecture
According to [6], CLIP is based on two different encoders to codify the images and text, respectively:
- For the image encoder they proposed two different architectures, initially a ResNet-50 was used (along with other modifications for this base architecture), and a Visual Transformer (ViT). The final architecture to use was ViT due to the better efficiency shown than ResNet (up to 3 times more efficient).
- For the text encoder they used a transformer model, with some modifications, following the base architecture from GPT-2 ([8])
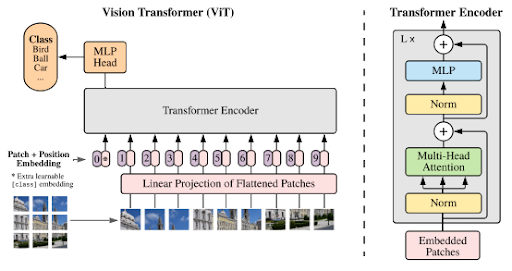
These two Transformers are used jointly to get powerful image and text representations, and be able to relate both representation types.
3.2. Contrastive Pre-training
Once we have explained the architecture, we now explain how to train both encoders (Contrastive Pretraining, [4]):
- Select “N” images and “N” text describing each one of the images, respectively, as a batch
- Codify the different images and texts with their respective encoder
- To evaluate the similarity of each pair possible between image and text, calculate the cosine similarity between each pair image/text to get a matrix [N x N] representing the cross-similarity between the images and texts. A higher value means a greater similarity (semantic) between the corresponding image and text, while a lower value means the opposite
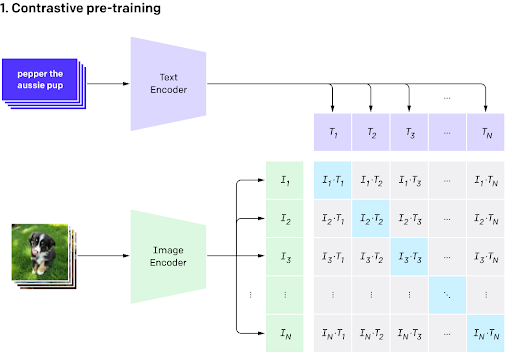
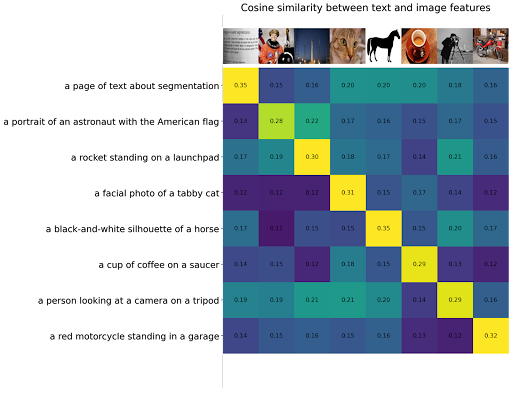
The objective is to maximize the values of the main diagonal (representing the pairs with the corresponding image/text) and minimize the other values. With this approach, we can describe the i-th picture only using the i-th description and not other independent descriptions. In the next image, we show the cosine similarity between text and image features for 8 images from the skimage dataset. As we have just mentioned, it can be clearly seen that this matrix adapts to a diagonal-matrix [5].
This approach allows us to train both text and image encoder to make better representations for the next point: Zero-Shot Learning.
3.3. Case of use: Zero-Shot Learning
Once we have explained the architecture, we put some examples to explain the different parts of the model. First of all, we need an image and different texts describing the image, some more detailed, others not, even wrong descriptions.
For the codification of the text and image, where use for both transformers (for image, a Vision Transformer; and for text, other similar to the used for image) already pre-trained with the “Conceptual Captions” dataset (a very large dataset with images of various web sources) for explication purposes.
3.4. Limitations
As we will see, the model shows a high potential to make a relationship between text features and image features, but also we can appreciate a little gap between the performance between using “prepared” data and real data due to these images can have noisy sections, affecting the representation produced by the encoder, giving less accurate predictions as a result.
The performance also depends on the used dataset. According to [1], if we use a lineal classification on the ImageNet Dataset using the CLIP features, the CLIP accuracy has a 10% increment in the results, but on average, using other datasets, the performance is worse, so we can conclude that there is an implicit “bias” depending on the dataset used.
The CLIP model used is focused on physical object recognition (chair, cat, tree…), but for other tasks more abstract like counting the different objects on an image (three cars, six chairs…); and more complex like predicting the depth of each object or making a facial emotion recognizer to predict the respective text according to the proposed image.
Lastly, CLIP isn’t able to generalize objects not included in the pre-trained dataset (for example, using images of the dataset MNIST (handwritten digits), the model’s accuracy decreases 10%), making the model very sensitive to how we must describe the images for a better or worse representation.
4. Results
In our case of use, we have followed two approaches:
- Applying it to some random images from the public dataset CIFAR100, which contains 32×32 images belonging to 100 different classes of objects.
- Testing CLIP’s real-world performance selecting some images to understand the behaviour of the model with images never seen by the pre-trained model.
For these 3 examples from CIFAR100, we show their top predictions, where it can be seen that CLIP wrongly predicts a lion whilst the real label is a lion. Nevertheless, the two following images are correctly classified.
import os
import clip
import torch
from torchvision.datasets import CIFAR100
import matplotlib.pyplot as plt
import random
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
# Get 4 random images from the dataset
id_images = random.sample(range(len(cifar100)), 3)
# Apply the model to the images
for i in id_images :
# Prepare the inputs
image, class_id = cifar100[i]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
# Print the original label with the image
print("Real label:", cifar100.classes[class_id])
plt.imshow(image)
plt.axis('off')
plt.show()



For some images from the internet, as it is mentioned by Nikos Kafritsas [4], we show that CLIP knows how to correctly understand the context and the background from a given image. This case distinguishes between a dog in different scenarios.
import torch
import clip
from PIL import Image
import pandas as pd
import os
import numpy as np
import matplotlib.pyplot as plt
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
dir_path = './images/'
text_input = ["A photo of Cristiano Ronaldo", "A photo of Leo Messi", "A photo of Rauw Alejandro", \
"A photo of C. Tangana", "A photo of a dog", "A photo of a golden retreiver running", \
"A golder retriever standing", "A dog", "A dog in the beach",
"A photo of a diagram", "A photo of a chair", "A photo of a table", "A photo of a banana"\
]
text = clip.tokenize(text_input).to(device)
for img in os.listdir(dir_path):
original_image = Image.open(dir_path+img)
image = preprocess(Image.open(dir_path+img)).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
indices = np.argsort(probs[0])[-5:]
values = probs[0][indices]
# Print the result
print("Image:", img)
plt.imshow(original_image)
plt.axis('off')
plt.show()
print("\nTop predictions:")
for value, index in zip(values, indices):
print(f"\t{text_input[index]:}: {100 * value.item():.2f}%")
print("\n",'-'*15, "\n")



We also show the results on some other different tasks like recognizing a banana, a chair or something more abstract like a diagram, completing it without any difficulty.

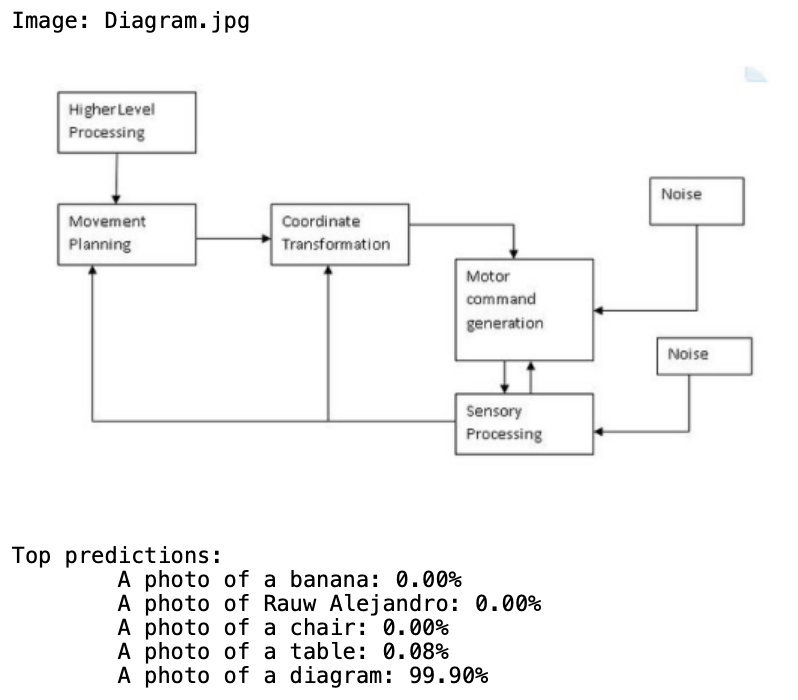

Moreover, we have tested by ourselves the limitations mentioned (celebrity-recognition, hand-written digits, facial emotions and counting objects) [6] and they all struggle to complete the task correctly.

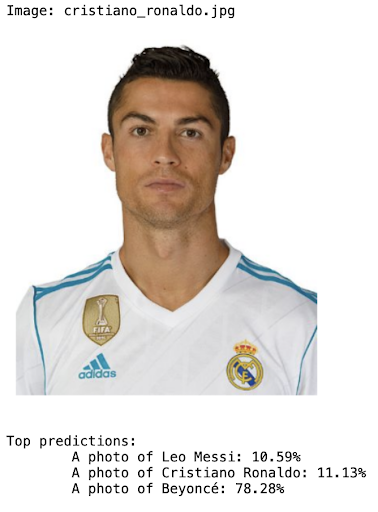


5. Discussion
As we have seen in the previous examples, CLIP model is a powerful tool for understanding and connecting text and images, with the ability to comprehend context and perform tasks such as automatic image labelling and text-image pairing. However, it may have limitations and poorer performance in tasks that involve a deeper level of understanding, such as sentiment detection, getting the exact number of objects that are in an image, or generating images from text instead of text from images. It is important to consider these strengths and limitations when applying CLIP in different scenarios and tasks.
Bibliography
[1] R. Taori, A. Dave, V. Shankar, N. Carlini, B. Recht, and L. Schmidt, “Measuring robustness to natural distribution shifts in image classification,” arXiv [cs.LG], 2020.
[2] Clip: Connecting text and images (2021) CLIP: Connecting text and images. Available at: https://openai.com/research/clip (Accessed: 10 June 2023).
[3] A. Li, A. Jabri, A. Joulin, and L. van der Maaten, “Learning visual N-grams from web data,” arXiv [cs.CV], 2016.
[4] N. Kafritsas, “CLIP: The Most Influential AI Model From OpenAI — And How To Use It,” Towards Data Science, 26-Sep-2022. [Online]. Available: https://towardsdatascience.com/clip-the-most-influential-ai-model-from-openai-and-how-to-use-it-f8ee408958b1. [Accessed: 10-Jun-2023].
[5] Underwood, T., Exploring CLIP. Available at: https://colab.research.google.com/github/tedunderwood/is417/blob/main/labs/8ImagesOct19/Exploring%20CLIP.ipynb#scrollTo=iQqUfB6-_R5u (Accessed: 10 June 2023).
[6] A. Radford et al., “Learning transferable visual models from natural language supervision,” arXiv [cs.CV], 2021.
[7] A. Dosovitskiy et al., “An image is worth 16×16 words: Transformers for image recognition at scale,” arXiv [cs.CV], 2020.
[8] A. Radford, J. Wu, R. Child, D. Luan, D. Amodei, and I. Sutskever, “Language Models are Unsupervised Multitask Learners,” Cloudfront.net. [Online]. Available: https://d4mucfpksywv.cloudfront.net/better-language-models/language-models.pdf. [Accessed: 10-Jun-2023].