Introducción
La superresolución de imágenes (SR) es el proceso por el cual una imagen de baja resolución se convierte en una de alta resolución con el mínimo de distorsión o pérdida de información posible. Este problema ha sido muy estudiado en visión por computadora debido a sus numerosas aplicaciones prácticas. Por ejemplo, la superresolución es clave para restaurar material audiovisual antiguo, mejorar la claridad de imágenes médicas, e incluso potenciar la calidad de imágenes de seguridad.
En los últimos años, los métodos basados en aprendizaje profundo han logrado avances significativos en SR. Inicialmente, la mayoría de las redes se entrenaban minimizando el error cuadrático medio (MSE) entre la imagen generada y la original de alta resolución, optimizando así métricas como PSNR (pico de relación señal-ruido). Aunque esto producía imágenes con buen promedio de error, a menudo resultaban borrosas y con falta de detalles de textura, porque el MSE tiende a promediar las posibles soluciones. Este fenómeno motivó la búsqueda de enfoques alternativos centrados en la calidad perceptual. En este contexto surge SRGAN (Super-Resolution Generative Adversarial Network), propuesta por Ledig et al. en 2017, que combina redes generativas adversarias (GAN) con una función de pérdida perceptual para lograr
imágenes foto-realistas en superresolución.
A continuación, se introduce SRGAN y cómo ha marcado un hito en el ámbito de la superresolución de imágenes, enfocándose en sus aportes técnicos y resultados.
Estado del Arte
Antes de SRGAN, los métodos más comunes para la superresolución incluían técnicas de interpolación y enfoques basados en patches. Estos métodos tradicionales son rápidos, pero no son capaces de reconstruir detalles pequeños, produciendo imágenes borrosas o con artefactos. La llegada del deep learning lo cambió todo: las redes neuronales convolucionales (CNN) aprendieron a mapear directamente imágenes de baja resolución (LR) a alta resolución (HR) usando datos de entrenamiento, logrando reconstruir patrones y texturas que no estaban en la entrada. En 2014, Dong et al. presentaron SRCNN, la primera CNN aplicada a superresolución de imagen, con un rendimiento muy superior a métodos previos basados en interpolación tanto en calidad como en eficiencia. SRCNN utilizaba una arquitectura de 3 capas convolucionales para aprender la relación entre patches LR y HR, sirviendo como base para los modelos posteriores.
Más tarde, se profundizó en redes más profundas y eficientes. En 2016, Kim et al. introdujeron VDSR (Very Deep SR), una red de 20 capas parecida a VGG que incorporó aprendizaje residual (skip connections) para facilitar la convergencia. VDSR alcanzó mejoras significativas en precisión respecto a SRCNN, y gracias a la conexión residual podía entrenarse mucho más rápido, hasta 10^4 veces más rápido en convergencia. Otros trabajos notables de esa época incluyen FSRCNN, una variante rápida y compacta de SRCNN, y métodos recursivos profundos como DRCN, que también mejoraron las métricas de calidad.
Todos estos modelos mencionados, priorizaron exactitud numérica sobre fidelidad visual, llevando a que las imágenes superresueltas fueran suaves y no tuvieran un aspecto natural. SRGAN se impuso como un gran cambio: en vez de mejorar el PSNR, generó imágenes más realistas al ojo humano, aunque no coincidan exactamente píxel a píxel con la imagen original. Para ello, SRGAN introdujo la idea de combinar una pérdida adversarial de las GAN con una pérdida perceptual basada en características de alto nivel. En su evaluación, SRGAN obtuvo puntajes de opinión perceptual (MOS) mucho más cercanos a los de las imágenes originales que cualquier método anterior, a pesar de tener valores PSNR algo menores. Este modelo permitió que se desarrollasen nuevos modelos como ESRGAN en 2018 que elimina mejor rtefactos y mejora la función de pérdida.
Desarrollo
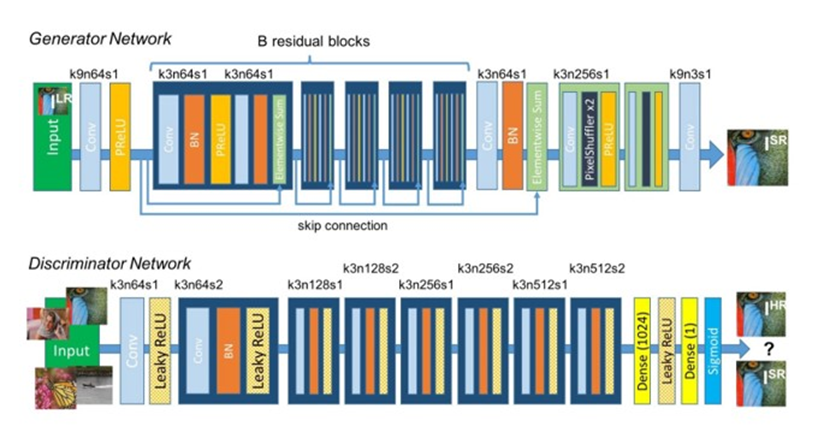
SRGAN está compuesto por dos redes principales que se entrenan de forma adversaria: un generador G y un discriminador D.
El generador toma como entrada una imagen de baja resolución (por ejemplo 32×32 píxeles) y produce una versión de alta resolución (por ejemplo 128×128 siendo el factor de escala es 4x). Para lograr esto, G utiliza una arquitectura de red residual profunda inspirada en ResNet . En concreto, el generador de SRGAN contiene múltiples bloques residuales con capas convolucionales de filtros pequeños (3×3) y activaciones PReLU, junto a normalización por lotes. Estos bloques aprenden las características de alto nivel necesarias para recrear los detalles que faltan.
Además, el generador incluye capas de upsampling aprendidas: en lugar de interpolación fija, utiliza capas de pixel shuffle para aumentar la resolución de forma eficiente y sin artefactos.
Gracias a la combinación de convoluciones profundas + bloques residuales + pixel shuffle, el generador puede mapear la imagen de baja resolución a una de alta resolución llenando bordes, texturas y detalles finos de manera coherente.
Por su parte, el discriminador de SRGAN es una CNN que recibe imágenes (ya sean las generadas por el generador o imágenes de alta resolución reales) y aprende a clasificarlas como reales o falsas. La arquitectura del discriminador típicamente consta de varias capas convolucionales con funciones de activación LeakyReLU, seguidas de capas densas hacia la salida que emite la probabilidad de que la imagen sea real.
Un detalle importante es que el discriminador de SRGAN opera a nivel de patches de imagen, lo que le permite concentrarse en patrones locales de textura para determinar la autenticidad. Durante el entrenamiento, el discriminador va mejorando su capacidad para distinguir, lo cual a su vez obliga al generador a producir imágenes cada vez más realistas.
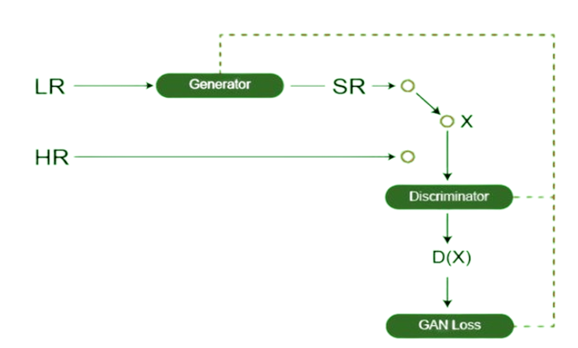
Un aspecto clave de SRGAN es su función de pérdida perceptual, que combina dos términos:
- Pérdida adversarial: Proveniente de la GAN (minimizando la función de ganancia del discriminador). El generador es penalizado si el discriminador logra distinguir sus imágenes de las reales. De este modo, aprende a engañar produciendo imágenes con apariencias estadísticas similares a las fotos reales.
- Pérdida de contenido (perceptual): Calculada en un espacio de características de alto nivel. Concretamente, utiliza una red pre-entrenada (VGG19) para extraer características tanto de la imagen generada como de la imagen original, y calcula el error MSE en esas representaciones profundas.
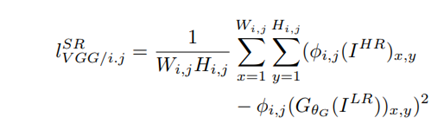
- Pérdida de contenido (MSE):
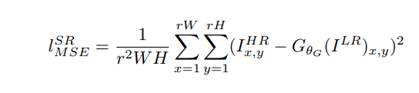
- Pérdida perceptual total:

En resumen, la combinación de la pérdida adversarial y la perceptual ayudan a SRGAN a generar imágenes cada vez más realistas. Durante el entrenamiento, se alterna la optimización del generador (minimizando la pérdida combinada) y el discriminador (maximizando su precisión de clasificación), en un proceso típico de entrenamiento GAN.
Ejemplo cualitativo de SRGAN: Comparativa de una imagen de flores ampliada 4x mediante interpolación bicúbica (arriba izquierda), por una red SRResNet (arriba derecha) optimizada solo con pérdida de contenido (MSE), por SRGAN (abajo izquierda) optimizado con pérdida perceptual adversaria, y la imagen HR original (abajo derecha).

A simple vista, el resultado de SRGAN muestra detalles de textura mucho más realistas (en los pétalos y hojas) que la versión bicúbica, que está más borrosa, acercándose más al aspecto de la imagen original. Esto demuestra cómo la optimización adversarial de SRGAN produce imágenes visualmente más nítidas, incluso cuando las métricas tradicionales como PSNR pueden ser similares a las de métodos bicúbicos. En resumen, SRGAN preserva mejor los bordes y texturas finas que la interpolación estándar, logrando una super-resolución más realista.
Materiales Usados

Este bloque descarga el dataset DIV2K, prepara las rutas, redimensiona las imágenes a baja resolución y las normaliza para alimentar al modelo.


Definición del modelo SRGAN con parámetros clave como altura, anchura y bloques residuales. Se instancian los componentes y se prepara el dataloader.

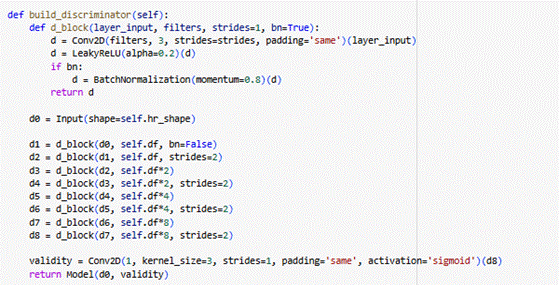
Implementación del generador con bloques residuales y capas de upsampling (pixel shuffle), y del discriminador con convoluciones que distinguen entre imágenes reales y generadas.

Proceso de entrenamiento por épocas: se generan imágenes, se calculan las pérdidas (GAN y perceptual), y se guarda la evolución de las curvas de pérdida.


Esta celda permite visualizar resultados (input LR, salida generada, ground truth HR) y guardar los pesos y arquitectura del modelo entrenado.
Resultados
Para evaluar el desempeño del modelo SRGAN, se ha aplicado el proceso de superresolución a tres imágenes seleccionadas que representan distintos tipos de contenido visual: un castillo (escena con líneas definidas), un arco chino (estructura con detalles finos), y un hombre (rostro humano con textura suave).
En la imagen del castillo, la versión generada por SRGAN logra restaurar las líneas arquitectónicas con gran fidelidad. Las torres, las ventanas y los detalles en las piedras aparecen más definidos en comparación con la imagen de baja resolución. Se reduce el desenfoque, y se observa una gran mejora en el contraste entre las estructuras del castillo y el cielo. Esto muestra que el modelo es efectivo para restaurar bordes y formas rectilíneas.

Esta imagen representa un desafío mayor por la presencia de ornamentos complejos y patrones decorativos. Aún así, SRGAN consigue recuperar muchos de los detalles, como las curvas y estructuras finas que desaparecen en la imagen de baja resolución. Aunque no se restaura con una precisión perfecta, la imagen generada resulta con muchas más información visual.

La imagen del rostro humano es clave para evaluar la capacidad perceptual del modelo, ya que el ojo humano es muy sensible a las distorsiones en rostros. En este caso, SRGAN reconstruye con éxito las facciones faciales, ojos, nariz y boca con gran naturalidad. A diferencia de la imagen LR, donde los rasgos están borrosos, la versión de SRGAN muestra una textura de piel más definida y una iluminación coherente.

Conclusión
SRGAN ha supuesto un avance enorme en superresolución de imágenes al priorizar la calidad visual sobre métricas como el error promedio. Con su arquitectura GAN y el uso de una pérdida perceptual, genera texturas de alta frecuencia y produce imágenes muy realistas. Modelos posteriores, como ESRGAN, han refinado su rendimiento y estabilidad. Sin embargo, su uso plantea desafíos como la generación de artefactos o la fidelidad en contextos críticos. Aun así, SRGAN ha demostrado que es posible mejorar la calidad de imágenes más allá de los límites físicos de sensores, asentando las bases para nuevas aplicaciones avanzadas en visión por computadora.
Bibliografía
- Ledig, C., Theis, L., Huszár, F., Caballero, J., Aitken, A. P., Tejani, A., … & Shi, W. (2017). Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network. arXiv preprint arXiv:1609.04802v5. Recuperado de https://arxiv.org/pdf/1609.04802v5
- PyImageSearch. (s.f.). Super-Resolution Generative Adversarial Networks (SRGAN). Recuperado de https://pyimagesearch.com
- Hui, J. (2018). GAN — Super Resolution GAN (SRGAN). Medium. Recuperado de https://jonathan-hui.medium.com/gan-super-resolution-gan-srgan-69b0b47d6d7c
- Joseph, A. G. (s.f.). Super-Resolution-GAN: Generates a Super Resolution image of your low resolution image [Repositorio GitHub]. Recuperado de https://github.com/AnjanaGJoseph/Super-Resolution-GAN
- Poh, W. (s.f.). SRGAN for Super Resolution and Image Enhancement [Repositorio GitHub]. Recuperado de https://github.com/pohwa065/SRGAN-for-Super-Resolution-and-Image-Enhancement
Trabajo realizado por Mónica Fernández, Juan José López, Alberto Sánchez