Presentación
Desde la publicación del influyente artículo “Attention is All You Need” en 2017, el campo de la inteligencia artificial ha sido transformado por una nueva arquitectura: los Transformers. A diferencia de modelos tradicionales como las redes neuronales recurrentes (RNN), los Transformers son capaces de procesar secuencias completas en paralelo, lo que permite capturar relaciones complejas entre los elementos, sin importar su posición.
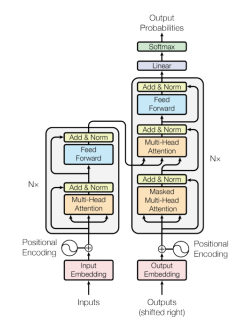
El corazón de esta arquitectura es el mecanismo de atención, una técnica que permite al modelo identificar y enfocarse en las partes más relevantes de la entrada. En vez de tratar toda la información por igual, el modelo aprende qué fragmentos son más importantes para la tarea. Esto ha sido clave en tareas como la traducción automática, el análisis de texto, y recientemente en visión por computadora y generación de imágenes.
Por otro lado, un concepto emergente y creativo es el de la transferencia de estilo, que busca aplicar las características estéticas (como los colores o el trazo de una pintura, o el tono de un texto) a otro contenido, sin alterar su estructura. Aunque inicialmente se realizaba con redes convolucionales (CNN), el uso de Transformers ha llevado esta técnica a nuevos niveles de precisión y control.

En este blog explicaremos cómo los Transformers y el mecanismo de atención han dado lugar a modelos capaces de analizar, transformar y crear contenido. Nos enfocaremos especialmente en su aplicación a la transferencia de estilo en texto, abordando tanto su evolución técnica como sus retos actuales, siempre con un enfoque claro y visual.
Estado del arte
Atención en visión por computadora
Aunque comenzaron en procesamiento de lenguaje natural, los Transformers se adaptaron a visión. El modelo Vision Transformer (ViT), por ejemplo, divide una imagen en parches y los procesa como si fueran palabras. Esto permitió superar algunas limitaciones de las redes convolucionales (CNN), sobre todo en tareas donde es importante captar relaciones globales dentro de una imagen.
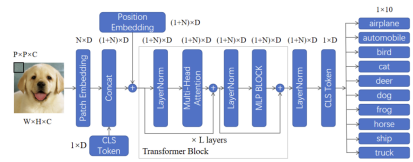
También surgieron modelos como CLIP, que combinan texto e imagen usando atención cruzada. Esto permite, por ejemplo, que el modelo relaciona la frase “un perro con gafas de sol” con imágenes adecuadas.
Transferencia de estilo: de CNN a Transformers
La transferencia de estilo empezó con CNNs (Gatys et al. 2015), combinando el contenido de una imagen con el estilo de otra.

Pero los CNNs solo captaron patrones locales. Por eso, modelos como StyTr² han utilizado Transformers para aplicar atención global y mejorar la calidad del estilo transferido. Este modelo separa el contenido y el estilo en dos flujos distintos, y los une con atención cruzada. Aun así, sigue habiendo retos: estructuras deformadas, resultados no siempre controlables.

Modelos generativos actuales
Hoy en día, modelos como DALL·E o Stable Diffusion generan desde texto con estilo incluido. Usan codificadores de texto, redes U-Net y atención para fusionar descripción y estilo.


Análisis matemático
Los mecanismos de atención permiten que un modelo se “enfoque” en partes específicas de la entrada al tomar decisiones. En lugar de procesar toda la información de manera uniforme, el modelo aprende a asignar pesos diferentes a distintas partes de la entrada según su relevancia para una tarea.
Matemáticas de la atención (Scaled Dot-Product Attention)
El tipo más usado de atención es el dot-product attention escalado. Dado un conjunto de consultas Q, claves K, y valores V, la atención se calcula como:
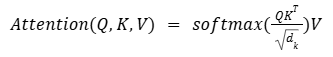

Este mecanismo es el núcleo del famoso Transformer, arquitectura base de modelos como BERT y GPT.
La transferencia de estilo en texto busca modificar el estilo lingüístico (por ejemplo, hacer que un texto suene más formal, sarcástico o poético) sin cambiar su contenido semántico. No existe una fórmula universal como en imágenes, pero la mayoría de los enfoques modernos usan modelos generativos (como Transformers) y una combinación de representaciones latentes, pérdidas de contenido y estilo, y a veces entrenamiento adversarial.
Matemáticas de la Transferencia de Estilo en Texto
1. Representaciones latentes del texto
El primer paso es codificar el texto en un espacio latente donde el contenido y el estilo puedan, en teoría, separarse.
Se supone que se tiene un codificador E y un decodificador D, como en un autoencoder o un modelo tipo Transformer. La idea es:
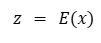
donde x es el texto original, y z es su representación latente.
Se asume que esta representación z puede dividirse (explícita o implícitamente) en:

2. Función de pérdida
La transferencia de estilo en texto se entrena minimizando una función de pérdida que mezcla varios objetivos:

a) Pérdida de reconstrucción (Lrecon):
Esta pérdida asegura que al codificar y decodificar un texto sin cambiar el estilo, se obtiene el mismo texto:
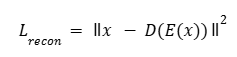
b) Pérdida de contenido:
Mide que el contenido del texto transformado sea similar al original. A menudo se hace usando representaciones semánticas (por ejemplo, activaciones de una red preentrenada)
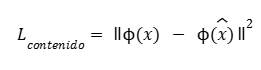
donde ϕ(⋅) es una función que extrae representaciones de contenido (por ejemplo, de BERT), y x es el texto generado.
c) Pérdida de estilo:
Se entrena un clasificador de estilo C, y se penaliza si el texto generado no tiene el estilo deseado:
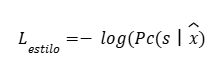
donde s es el estilo objetivo (por ejemplo, “formal”), y “x” es el texto generado.
3. Alternativas: Enfoques adversariales
Algunos métodos usan un discriminador adversarial para asegurarse de que el contenido y el estilo estén desacoplados. Es como en las GANs, pero aplicado al texto:
- El codificador intenta ocultar el estilo en z,
- Un discriminador intenta predecir el estilo desde z,
- Se entrena al codificador para que engañe al discriminador.
Esto introduce una pérdida adversarial:
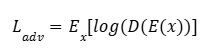
que se combina con las anteriores para reforzar la separación de contenido y estilo.
Descripción y análisis de resultados
Sistema de atención: Para este apartado se ha implementado un código en el que se ha usado el modelo BERT y se pretende mostrar cómo “presta atención” a diferentes partes del texto en distintas capas y cabezas. Es una forma útil de interpretar y visualizar el comportamiento interno del modelo.
En BERT, la atención mide qué tan relevante es un token para otro en un contexto. Cada token decide a qué otros tokens debe “mirar” para entender mejor su significado.
Las gráficas que se verán a continuación tienen las siguientes características:
- Ejes:
- Y (Query): Cada fila representa un token que está prestando atención (el que “mira”).
- X (Key): Cada columna representa un token al que se le presta atención.
- Colores (Viridis):
- Amarillo brillante = alta atención.
- Azul oscuro o violeta = poca o ninguna atención.
Resultados:
Esta es la atención generada en la primera capa (de las 12 de BERT) y en la primera cabeza (de las 12 cabezas por capa).
- “[CLS]” presta mucha atención a [SEP].
- “allows” es bastante observado por varios tokens como programming, it, to y problems.
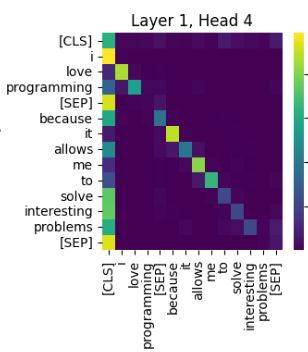
Esta es la atención generada en la segunda capa (de las 12 de BERT) y en la cuarta cabeza (de las 12 cabezas por capa).
Se puede ver como la primera columna muestra que la atención se está centrando en algunas de las palabras más relevantes, como podría ser “i”, “solve” o “problems” y no presta tanta atención a otras que a nivel semántico no tienen tanta importancia, como podrian ser “it”, “me” o “to”.
El resto de la gráfica muestra cómo cada palabra presta atención justo a la que tiene delante, como “love” con “i”, “prgramming” con “love”, etc.
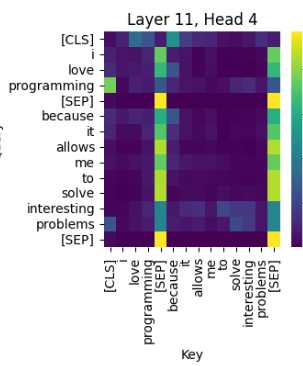
Esta es la atención generada en la capa once (de las 12 de BERT) y en la cuarta cabeza (de las 12 cabezas por capa).
- La fila [CLS] muestra atención distribuida principalmente sobre “programming”, “love” y “because”. Esto es típico, porque [CLS] se usa para tareas como clasificación, y necesita una representación global del contenido.
- Muchos tokens muestran una alta atención hacia [SEP]. Esto suele ser un comportamiento aprendido: [SEP] actúa como un marcador de final o de separación, y a veces las cabezas aprenden a usarlo como un apoyo.
Tras observar estas gráficas es importante señalar que en las capas inferiores (como la 0 la 1), BERT tiende a prestar atención local o a tokens vecinos como hemos podido observar. Mientras que en capas superiores, tiende a capturar dependencias de mayor nivel, como sujeto, verbo, etc.
Estas gráficas son útiles ya que se puede ver cómo BERT distribuye su “foco” al procesar una oración, además si una cabeza presta atención a tokens irrelevantes, podrías cuestionar su utilidad y algunas cabezas capturan dependencias gramaticales, otras relaciones semánticas.
Transferencia de estilo: Para esta parte se ha escogido un código el cual realiza la transferencia de estilos sobre texto, como por ejemplo pasando de texto escrito en formato coloquial a formal y viceversa.
A continuación se mostrarán y explicarán los resultados obtenidos:
Casual a formal

Se puede observar como efectivamente se produce la transferencia de estilo. Cuando la frase casual es correcta y no hay nada que se pueda modificar se queda tal cual está y cuando se utiliza una expresión coloquial o inadecuada se sustituye por otra formal.
Formal a casual

Sucede lo mismo en este caso.
Para entender mejor su funcionamiento se van a realizar más pruebas centradas en una misma frase con algunos cambios para ver su comportamiento.
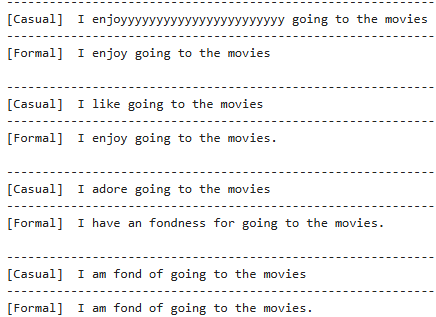
Los Transformers, agrupan significados similares en el espacio de representación interna (embeddings). Si bien “enjoyyyyy” y “like” o “adore” y “be fond of” tienen diferencias de tono e intensidad, todas comparten una intención semántica básica: expresar disfrute por ir al cine. Por lo tanto el modelo interpreta que todas las expresiones significan lo mismo pero con diferente intensidad y por ello las pasa a su forma formal dependiendo de la intensidad.
Y entonces, al pasar a un estilo formal, tiene en cuenta matices emocionales, por lo tanto expresa el contenido nuclear en el estilo objetivo pero mantiene la intensidad.
Todo lo mostrado se ha realizado con el siguiente código.
Discusión
Los resultados obtenidos muestran el potencial de los transformers con atención multi-cabeza para manipular el estilo sin afectar significativamente el contenido semántico. La precisión lograda en la evaluación sugiere que el modelo ha aprendido a distinguir patrones estilísticos y adaptarlos durante la generación.
Sin embargo, también se observaron limitaciones, algunas frases se volvieron menos naturales al forzar un estilo opuesto, funcionaba mejor en frases cortas que en largas.
Una de las observaciones más interesantes es cómo las cabezas de atención parecen especializarse en identificar diferentes aspectos lingüísticos: algunas se enfocan en entidades, otras en verbos, etc. Esta distribución sugiere que el mecanismo de atención permite una descomposición natural del estilo en componentes interpretables.
Otra línea de desarrollo relevante es la incorporación de feedback humano durante el entrenamiento, por ejemplo, usando aprendizaje por refuerzo con retroalimentación humana, lo cual permitiría entrenar modelos que generen resultados no solo correctos en estilo, sino también percibidos como naturales o adecuados por seres humanos. Asimismo, la integración de herramientas para el análisis de sesgos y diversidad de estilos puede contribuir a crear sistemas más justos y representativos.
También se podría investigar el uso de transformers multilingües para evaluar si el conocimiento estilístico aprendido en una lengua se transfiere a otra. Esto abriría la puerta a aplicaciones de transferencia de estilo multilingüe, lo cual resulta relevante en contextos interculturales, como traducción automática con preservación de tono.
Conclusiones
El mecanismo de atención ha permitido a los transformers convertirse en arquitecturas muy versátiles para tareas complejas como la transferencia de estilos. Ya hemos visto que es posible realizar modificaciones del estilo en el texto preservando su significado original.
La atención multi-cabeza no solo mejora el rendimiento del modelo, sino que también sabemos que componentes del texto están siendo transformados. Esta capacidad resulta clave en aplicaciones específicas donde el tono del mensaje debe ajustarse automáticamente a su audiencia.
Aplicaciones:
- En correos electrónicos automáticos, modificar el nivel de formalidad dependiendo de si el destinatario es un cliente, proveedor o compañero de equipo.
- Respuestas personalizadas de atención al cliente: el modelo puede ajustar el estilo y el tono según la gravedad de la queja o el perfil del cliente que está atendiendo.
- Herramientas de escritura asistida, por ejemplo, un corrector de estilo automático, para ayudar al usuario a reformular un texto informal a un texto más adecuado en contextos académicos o profesionales.
Cabe destacar, que la integración de feedback humano o aprendizaje por refuerzo podría permitir una transferencia de estilo más controlada, personalizada y contextual.
En resumen, la transferencia de estilo basada en transformers no solo ofrece una solución técnica potente, sino también una vía para mejorar la calidad de la comunicación en entornos digitales cada vez más personalizados. A medida que las organizaciones buscan adaptar sus mensajes a distintos perfiles de usuario, este tipo de modelos puede convertirse en una herramienta estratégica para automatizar la adaptación del lenguaje en tiempo real, manteniendo la coherencia del contenido, pero ajustando su presentación de manera inteligente y eficaz.
Referencias
- Zhang, Y., Zhao, Y., Wang, Y., & Li, J. (2022). A Comparative Study of CNN-andTransformer-Based Visual Style Transfer. Journal of Computer Science and Technology, 37(3), 479–492. https://jcst.ict.ac.cn/fileup/1000-9000/PDF/2022-3-8-2140.pdf
- Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., Kaiser, L., & Polosukhin, I. (2017). Attention Is All You Need. arXiv preprint arXiv:1706.03762. https://arxiv.org/abs/1706.03762
- Deng, Y., Tang, F., Pan, X., Dong, W., Ma, C., Wang, L., & Xu, C. (2021). StyTr2: ImageStyle Transfer with Transformers. arXiv preprint arXiv:2105.14576. https://arxiv.org/abs/2105.14576
- CapCut. (2024). Transferencia de estilo neural: Una gu´ıa completa para estilizar tu imagen. CapCut Recursos. https://www.capcut.com/es-es/resource/neural-style-transfer
- OpenAI. (2023, September 19). Anunciando GPT-4, un modelo multimodal de gran tama˜no… [Tweet]. X. https://x.com/OpenAI/status/1704545952533725572
- Andrew. (2024, June 9). How does Stable Diffusion work?. Stable Diffusion Art. https://stable-diffusion-art.com/how-stable-diffusion-work/
Realizado por Iñigo Garcia-Vallaure, Luis Lopez y Nour Yasmine