1. Introducción
Las imágenes obtenidas por satélite constituyen una fuente de información fundamental para diversas aplicaciones, como la planificación urbana, cartografía, agricultura y gestión de desastres naturales. Sin embargo, durante el proceso de adquisición y transmisión es habitual que las imágenes se vean afectadas por diferentes tipos de ruido, lo que puede degradar la calidad visual y dificultar tareas posteriores.
La eliminación de ruido (image denoising) es uno de los problemas clásicos del procesamiento de imágenes. Tradicionalmente se han empleado filtros espaciales y transformaciones en frecuencia, pero estos métodos pueden desembocar en la pérdida de detalles importantes para la imagen. Con la mejora de los modelos de aprendizaje profundo se han desarrollado modelos capaces de reconstruir versiones más limpias de las imágenes preservando gran parte de la información estructural.
En este trabajo se estudia el uso de diferentes arquitecturas basadas en Autoencoders para la eliminación de ruido sintético en imágenes satelitales del conjunto de datos EuroSAT.
2. EuroSAT
Para llevar a cabo los experimentos se ha usado EuroSAT [1], un conjunto de datos basado en imágenes capturadas por los satélites Sentinel-2 [2] [2] del programa europeo Copernicus. Está compuesto por 27.000 imágenes RGB de 64×64 píxeles agrupadas en diez categorías que representan diferentes tipos de cobertura terrestre.
Las clases incluidas son AnnualCrop, PermanentCrop, Forest, HerbaceousVegetation, Highway, Industrial, Pasture, Residential, River y SeaLake. Esta diversidad permite comparar el comportamiento de los modelos frente a imágenes con características visuales muy distintas, como regiones homogéneas de vegetación o agua, y zonas con muchos bordes, texturas y estructuras artificiales.
Aunque EuroSAT tiene como objetivo original la resolución de problemas de clasificación en este trabajo se ha adaptado para una tarea de restauración de imágenes. Para ello, las imágenes originales se consideran como la referencia (ground truth), mientras que las entradas al modelo se obtienen aplicando de forma sintética distintos niveles de ruido. Después se puede evaluar la capacidad de restauración de los modelos comparando la imagen resultante con la original.
AnnualCrop 3000
Forest 3000
HerbaceousVegetation 3000
Residential 3000
SeaLake 3000
Highway 2500
PermanentCrop 2500
Industrial 2500
River 2500
Pasture 2000

3. Modelos empleados
Se han evaluado tres modelos basados en redes neuronales convolucionales con el objetivo de comparar el efecto de la arquitectura en la capacidad de eliminar ruido de las imágenes: un Autoencoder (AE) convencional, un Variational Autoencoder (VAE) y un Variational Autoencoder con arquitectura U-Net (U-Net VAE).
3.1. Autoencoder
Constituye la arquitectura base sobre la que se desarrollan los demás modelos. Está formado por dos bloques principales: Un encoder encargado de comprimir progresivamente la imagen de entrada hasta obtener una representación de baja dimensión denominada espacio latente, y un decoder, que utiliza dicha representación para reconstruir la imagen original.
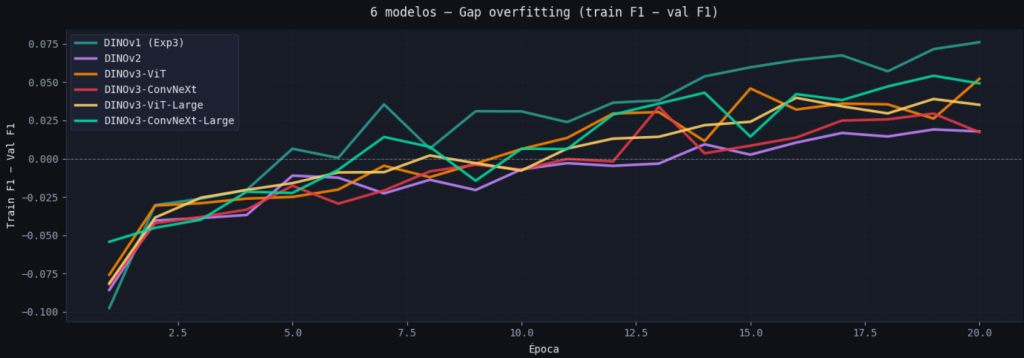
Durante el entrenamiento el modelo aprende a conservar únicamente la información más relevante y descarta las variaciones asociadas al ruido. Por la compresión de la información tiende a producir reconstrucciones suavizadas en las que se pierden detalles y texturas de alta frecuencia.
3.2. Variational Autoencoder (VAE)
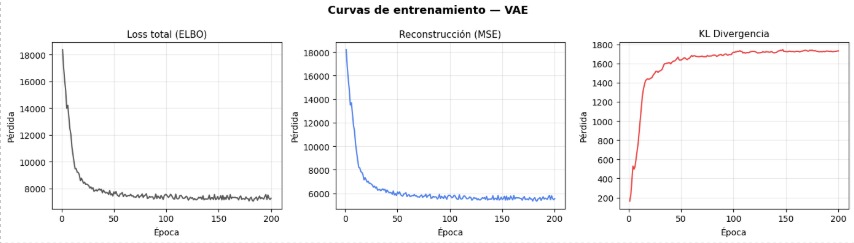
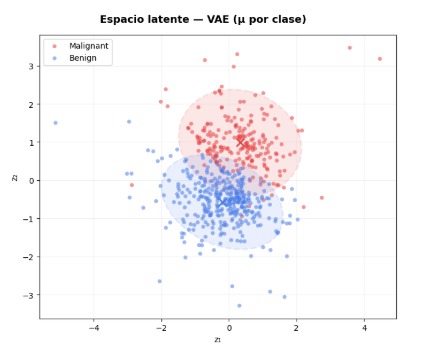
Introduce una modificación fundamental respecto al Autoencoder clásico. En lugar de aprender una única representación latente estima una distribución de probabilidad con media μ y varianza σ2.
Además de la pérdida de reconstrucción, el entrenamiento incorpora una penalización basada en la divergencia de Kullback-Leiber (KL), cuyo objetivo es evitar que las representaciones latentes se distribuyan de forma arbitraria.
Puede favorecer una mejor capacidad de generalización, pero también puede dificultar la reconstrucción de detalles muy finos si la restricción sobre el espacio latente es muy elevada, por lo que el peso de la pérdida KL se debe ajustar cuidadosamente.
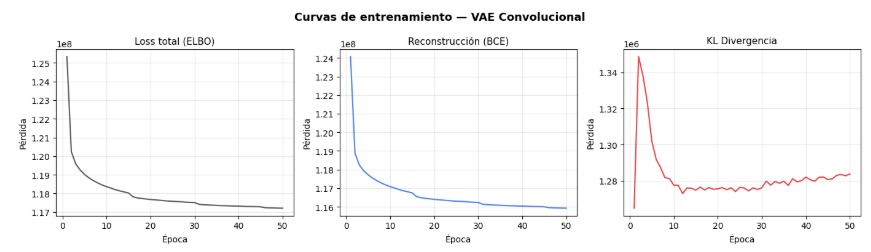
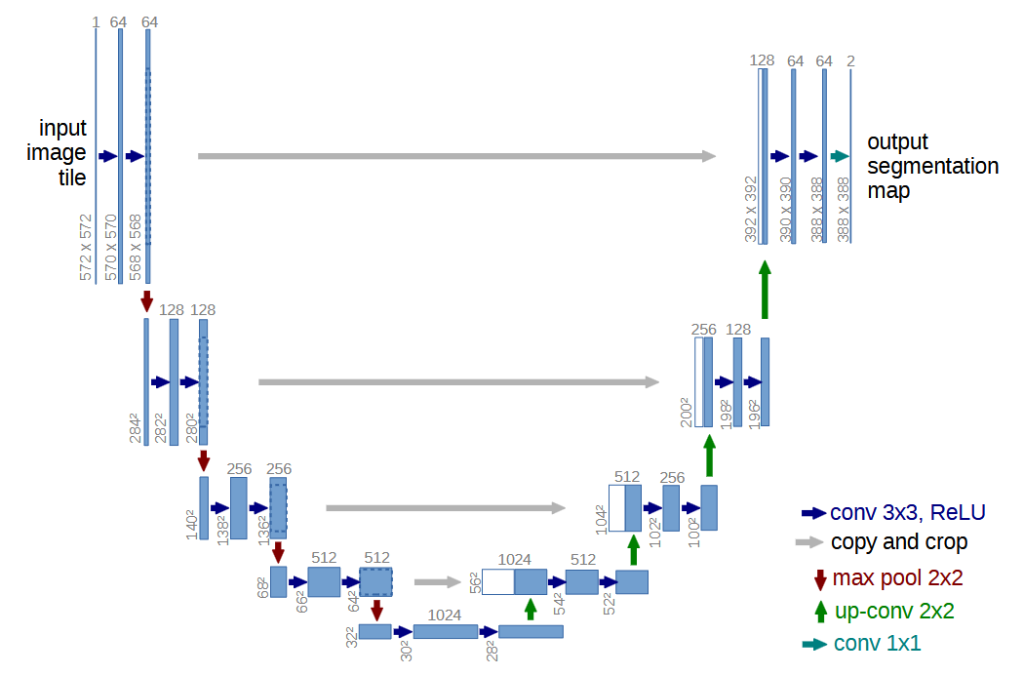
3.3. Variational Autoencoder con arquitectura U-Net
Arquitectura originalmente propuesta para segmentación biomédica [3] [4] que incorpora conexiones de salto (skip connections) entre las capas del encoder y las correspondientes del decoder. Permite enviar directamente información de alta resolución al proceso de reconstrucción sin necesidad de comprimirla completamente.
De esta forma el decoder dispone tanto de la representación latente aprendida por el encoder como de las características recibidas a través de las skip connections en distintas escalas durante la fase de compresión.
Esta arquitectura aumenta la complejidad del modelo, y aunque esto teóricamente se traduce en reconstrucciones más nítidas existe el riesgo de que parte del ruido presente en la imagen de entrada se propague a la imagen resultante si la arquitectura no identifica correctamente qué características deben conservarse y cuáles deben descartarse.
4. Entrenamiento
Se divide cada una de las clases del dataset para poder dedicar el 80% de las imágenes de cada clase para train y el 20% para test. De esta forma después se pueden evaluar los resultados de los distintos modelos para cada una de las clases, ya que es de esperar que aquellas clases como SeaLake y AnnualCrop obtengan mejores resultados que Residential o Highway porque son mucho más homogéneas.
En un principio había planteado usar las imágenes Synthetic Aperture Radar (SAR) del Sentinel-1 como imágenes ruidosas, ya que están tomadas sobre las mismas regiones y se ven afectadas por speckle [5]. Este ruido no sería sintético, y mediante el uso de un dataset con parejas de imágenes Sentinel-1 Sentinel-2 como puede ser [6] o [7] ya estaría prácticamente listo para el entrenamiento de modelos. El problema es que por lo distintas que son las formas en las que se toman las imágenes en los dos casos no he sido capaz de obtener resultados reales y los modelos simplemente tienden a rellenar prácticamente todos los píxeles con el valor medio de todos los píxeles de la imagen ruidosa. Por tanto, he decidido generar imágenes ruidosas sintéticamente aplicando ruido gaussiano de intensidad variable.
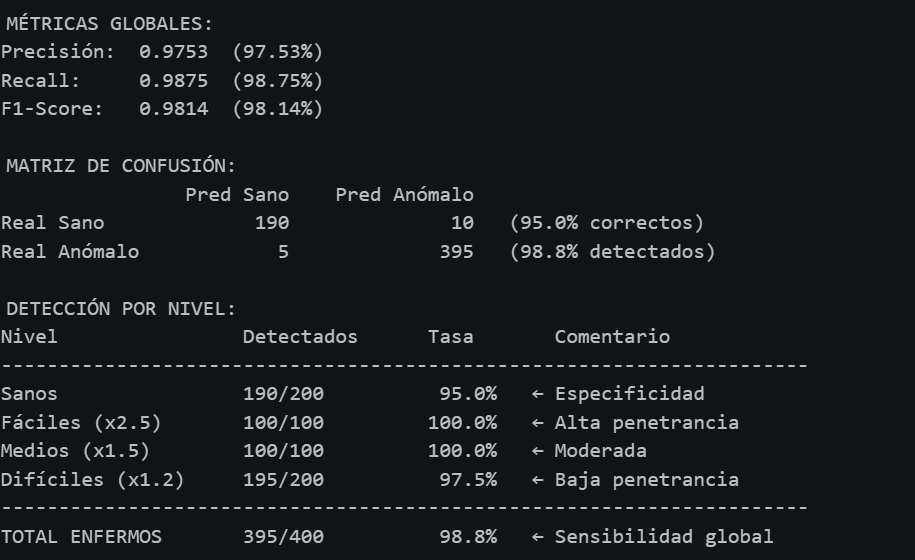
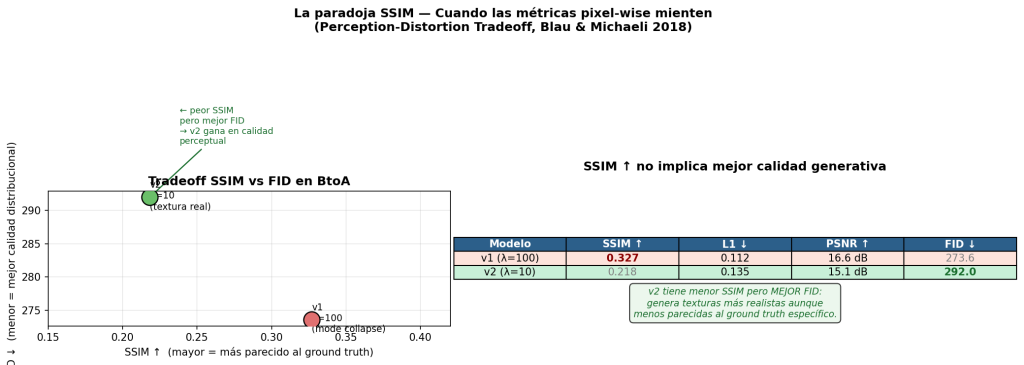
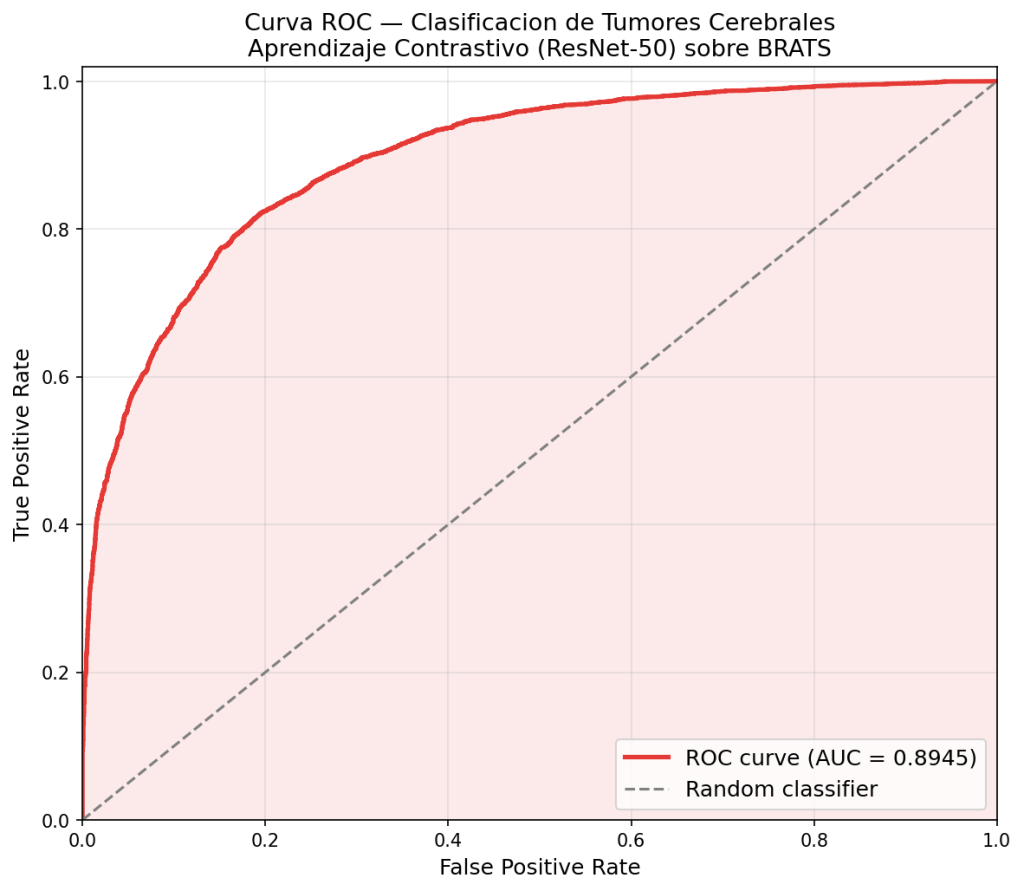
5. Resultados
5.1. Visualización previa
Antes de analizar las métricas obtenidas es interesante visualizar el comportamiento de los distintos modelos para una misma imagen. Estos son cuatro ejemplos de las clases AnnualCrop, Residential, River e Industrial afectados por ruido gaussiano con una intensidad de 0.05. Para cada imagen se presenta la siguiente secuencia:
Imagen original → Imagen con ruido → Autoencoder → Variational Autoencoder → U-Net VAE

Las imágenes de la clase AnnualCrop están compuestas por formas bastante sencillas y colores simples, pero tanto en el Autoencoder como en el Variational Autoencoder la imagen resultante es muy borrosa y solamente se pueden distinguir algunas zonas verdes. En esta imagen en concreto se reconoce la forma del lado izquierdo verde oscuro, así como la del lado derecho del mismo color, pero las zonas más claras prácticamente son eliminadas.
Por otro lado, la imagen devuelta por el VAE con U-Net es mucho más nítida, se mantienen las formas y los bordes, pero tampoco elimina completamente el ruido introducido.

En la clase Residential los resultados deberían ser generalmente peores, principalmente por los cambios de color repentinos en un área pequeña. Una vez más tanto el Autoencoder como el VAE devuelven imágenes muy borrosas en las que no se podría distinguir con claridad que se trata de una zona urbana, mientras que el VAE con U-Net proporciona un resultado notablemente más nítido con bordes marcados, aunque todavía borroso.

La clase River posee características más cercanas a la clase AnnualCrop, con formas más sencillas y colores más simples. Esto sugiere que los resultados esperados deberían ser mejores, y esta idea coincide con los resultados observados en esta imagen. Tanto el Autoencoder como el Variational Autoencoder devuelven imágenes borrosas en las que se sigue pudiendo identificar la forma general, mientras que el resultado del VAE con U-Net sigue siendo más nítido pero se mantienen restos del ruido.

La clase Industrial es relativamente similar a la clase Residential pero se puede extraer de forma relativamente más sencilla el esquema urbanístico, por lo que se podrían obtener resultados mejores con el modelo del Autoencoder y el VAE que en la imagen de la clase Residential. En este caso devuelven una forma que parece una alucinación del modelo. Por otro lado en el caso del VAE con U-Net se aprecia una imagen más nítida muy parecida a la original con parte del ruido de la imagen ruidosa.
5.2. Métricas empleadas
- Peak Signal-to-Noise Ratio (PSNR)
Expresa la calidad de la reconstrucción en decibelios (dB) a partir del error cuadrático medio. MAX representa el valor máximo que puede tomar un píxel, que en este caso es 1 porque las imágenes han sido normalizadas. Como depende del error cuadrático medio se puede dar el caso de que dos imágenes con PSNR similares sean de una calidad visual distinta, ya que solamente considera el valor de píxeles individuales.
- PSNR < 20: Reconstrucción deficiente
- PSNR > 40: Prácticamente indistinguible del original
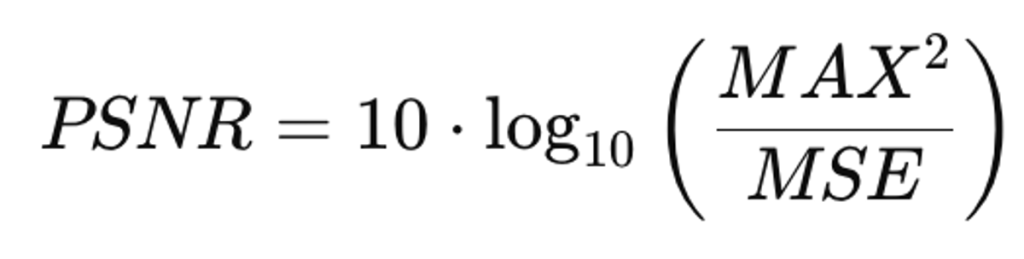
- Structural Similarity Index Measure (SSIM)
Trata de aproximar mejor la percepción humana sobre la calidad de una imagen. En lugar de comparar únicamente el valor de los píxeles trata de considerar la luminancia, el contraste y la estructura de la imagen. Usa la media, varianza, covarianza de las imágenes y dos constantes numéricas para evitar inestabilidades. Toma valores entre 0 y 1, indicando 1 que se trata de dos imágenes idénticas.
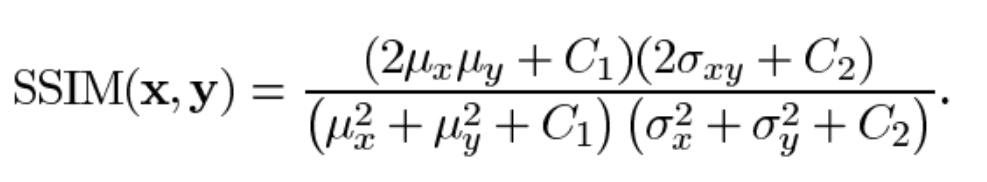
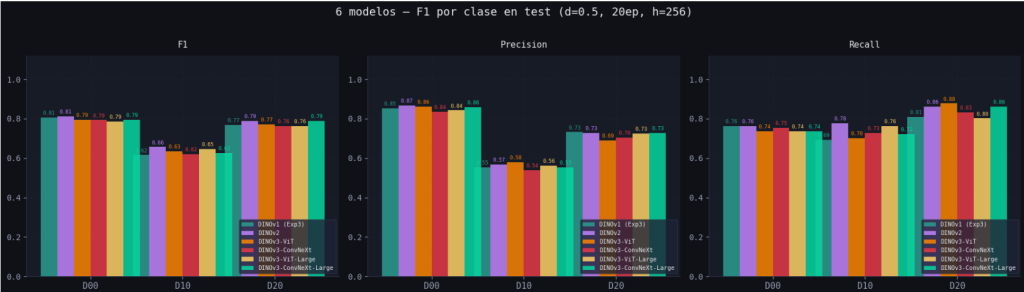
5.3. Análisis de métricas

En primer lugar un vistazo al MSE confirma que las clases más homogéneas como son SeaLake, Forest y Pasture son las más fáciles de aproximar para los modelos, mientras que las clases con más variación como Industrial y Residential provocan más error. Cabe destacar un error cuadrático medio extrañamente elevado en el caso de Industrial para los modelos del Autoencoder y el Variational Autoencoder, que se podría relacionar con las alucinaciones identificadas anteriormente.


Los resultados del PSNR y el SSIM reafirman lo ya mencionado, que el VAE con U-Net devuelve resultados más cercanos a la imagen original, y el hecho de que no todo el ruido sea eliminado no tiene un impacto lo suficientemente grande como para que sus métricas sean superadas por el Autoencoder o el VAE. Es importante notar que los dos únicos casos en los que el VAE con U-Net se ve superado por los otros dos modelos son para las clases de SeaLake y Forest: las dos clases más homogéneas y en las que dejar prácticamente toda la imagen de un mismo color sería una muy buena aproximación a la imagen original.
6. Conclusiones
Los resultados obtenidos muestran que la incorporación de conexiones de salto propias de U-Net supone una mejora significativa en la calidad de las reconstrucciones, permitiendo conservar mejor los detalles espaciales y reduciendo el efecto de suavizado característico de los autoencoders tradicionales.
El análisis por clases indica que la dificultad del problema proviene en gran medida de la enorme variabilidad de las imágenes. Las clases más homogéneas presentan sistemáticamente menores errores de reconstrucción, mientras que las clases de mayor complejidad estructural resultan considerablemente más difíciles de restaurar.
Las métricas confirman las observaciones, ya que mientras que el Autoencoder y el Variational Autoencoder convencional obtienen muy buenos resultados para las clases con imágenes más uniformes, el VAE con U-Net consigue, de forma general, mejores valores tanto de PSNR y SSIM, lo cual indica que se trata de un resultado más fiel a la imagen original tanto desde un punto de vista numérico como perceptual. La capacidad de U-Net para preservar información de alta resolución permite obtener reconstrucciones de mayor calidad.
7. Líneas futuras
Una de las principales líneas futuras consiste en trasladar esta metodología a imágenes SAR procedentes de Sentinel-1, donde el ruido predominante no es gaussiano sino el speckle. En este caso el problema es de mayor complejidad ante la ausencia de imágenes completamente libres de ruido. Para obtener aproximaciones de imágenes sin ruido se puede usar la media de varias imágenes en distintos momentos de un mismo sitio, Noise2Noise en caso de poseer al menos dos imágenes y Noise2Void en caso de solo tener acceso a una.
Otra posible ampliación consiste en entrenar los modelos con una mayor variedad de degradaciones, ya sea combinando distintos tipos de ruido o aplicándolos simultáneamente. De esta forma se obtendría un modelo más robusto capaz de restaurar imágenes afectadas por más de un solo tipo de ruido.
Por último sería interesante emplear estrategias de entrenamiento más dirigidas a la generalización. En lugar de entrenar y validar el modelo sobre imágenes de todas las clases se podría considerar una validación Leave-One-Class-Out, que en este caso consistiría en entrenar el modelo sobre nueve de las diez clases del dataset EuroSAT y evaluarlo sobre la décima completamente desconocida. Con este planteamiento se puede evaluar hasta qué punto el modelo es capaz de identificar de forma general el ruido y eliminarlo frente a depender de las características de las escenas observadas.
8. Referencias
[1] Gotam Dahiya, ArjunDebnath. (2020). EuroSAT Dataset. https://www.kaggle.com/datasets/apollo2506/eurosat-dataset
[2] Más información sobre Sentinel-1 y Sentinel-2. https://documentation.dataspace.copernicus.eu/Data/SentinelMissions/Sentinel1.html , https://documentation.dataspace.copernicus.eu/Data/SentinelMissions/Sentinel2.html
[3] Ronneberger, O., Fischer, P., and Brox, T. (2015). U-Net: Convolutional Networks for Biomedical Image Segmentation. https://arxiv.org/abs/1505.04597
[4] Myronenko, A. (2019). 3D MRI Brain Tumor Segmentation Using Autoencoder Regularization. MICCAI BrainLes Challenge. https://arxiv.org/abs/1810.11654
[5] Schmitt, M., Hughes, L. H., Qiu, C., and Zhu, X. X.: SEN12MS – A CURATED DATASET OF GEOREFERENCED MULTI-SPECTRAL SENTINEL-1/2 IMAGERY FOR DEEP LEARNING AND DATA FUSION, ISPRS Ann. Photogramm. Remote Sens. Spatial Inf. Sci., IV-2/W7, 153–160, https://doi.org/10.5194/isprs-annals-IV-2-W7-153-2019, 2019.
[6] Dabhi, S. et al. (2020). Virtual SAR: A Synthetic Dataset for Deep Learning based Speckle Noise Reduction Algorithms. https://arxiv.org/abs/2004.11021 (Dataset no publicado a junio de 2026)
[7] Paritosh Tiwari. (2021). Sentinel-1&2 Image Pairs (SAR & Optical). https://www.kaggle.com/datasets/requiemonk/sentinel12-image-pairs-segregated-by-terrain/data