Introducción
Las Redes Generativas Adversarias (GANs, por sus siglas en inglés) son una técnica de inteligencia artificial para aprendizaje no supervisado. Enfrentan dos redes neuronales en competencia: un generador que crea datos sintéticos realistas y un discriminador que intenta distinguir entre datos reales y generados.
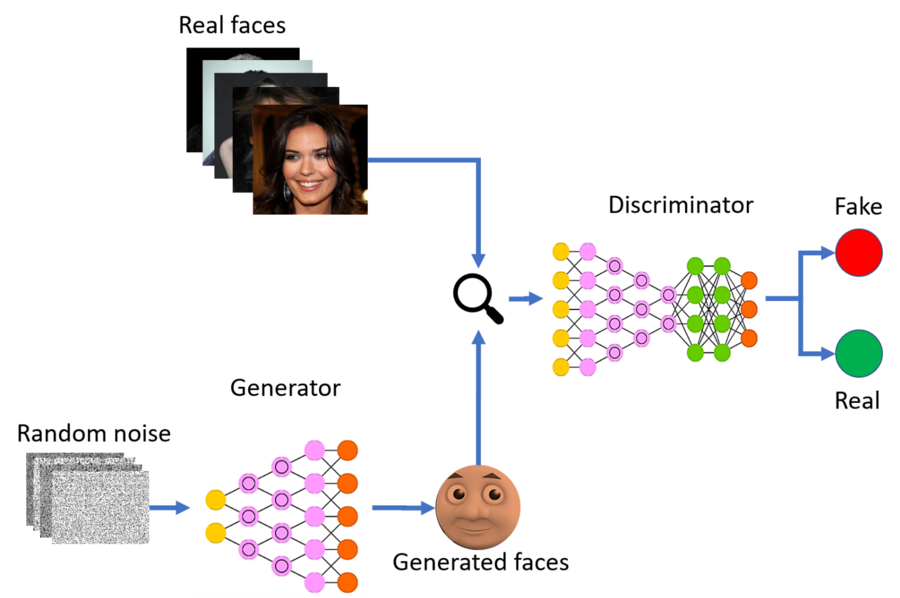
- Generador (G): Transforma vectores aleatorios, tomados de una distribución gaussiana, en muestras que imitan datos reales.
- Discriminador (D): Recibe imágenes reales y generadas, y estima la probabilidad de que una imagen sea auténtica.
- Aprendizaje adversarial: Ambos modelos se entrenan de forma conjunta y adversaria en un juego de suma cero, donde el generador mejora al producir imágenes más realistas, y el discriminador mejora al detectar falsificaciones más sutiles. Este proceso se estabiliza mediante una actualización alterna de los pesos de G y D.
Este paradigma ha permitido avances notables en generación de imágenes realistas, particularmente en rostros humanos, arte, y entornos simulados, y ha sentado las bases para modelos más sofisticados.
Por otro lado, dentro de esta familia de modelos, StyleGAN2-ADA destaca por su capacidad para generar imágenes de alta fidelidad y por incorporar mecanismos que permiten su entrenamiento eficiente incluso con conjuntos de datos limitados. Esta arquitectura, desarrollada por NVIDIA, introduce mejoras tanto en el diseño interno del generador como en la estrategia de entrenamiento del discriminador [1].
Una de sus principales innovaciones es el uso de ADA (Adaptive Discriminator Augmentation), un módulo que regula dinámicamente la cantidad de aumentos geométricos y fotométricos aplicados a las imágenes.
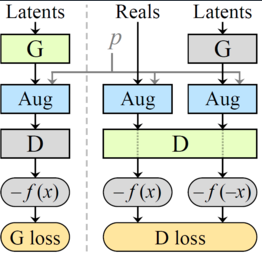
Se presenta el esquema general del entrenamiento en StyleGAN2-ADA [2]:
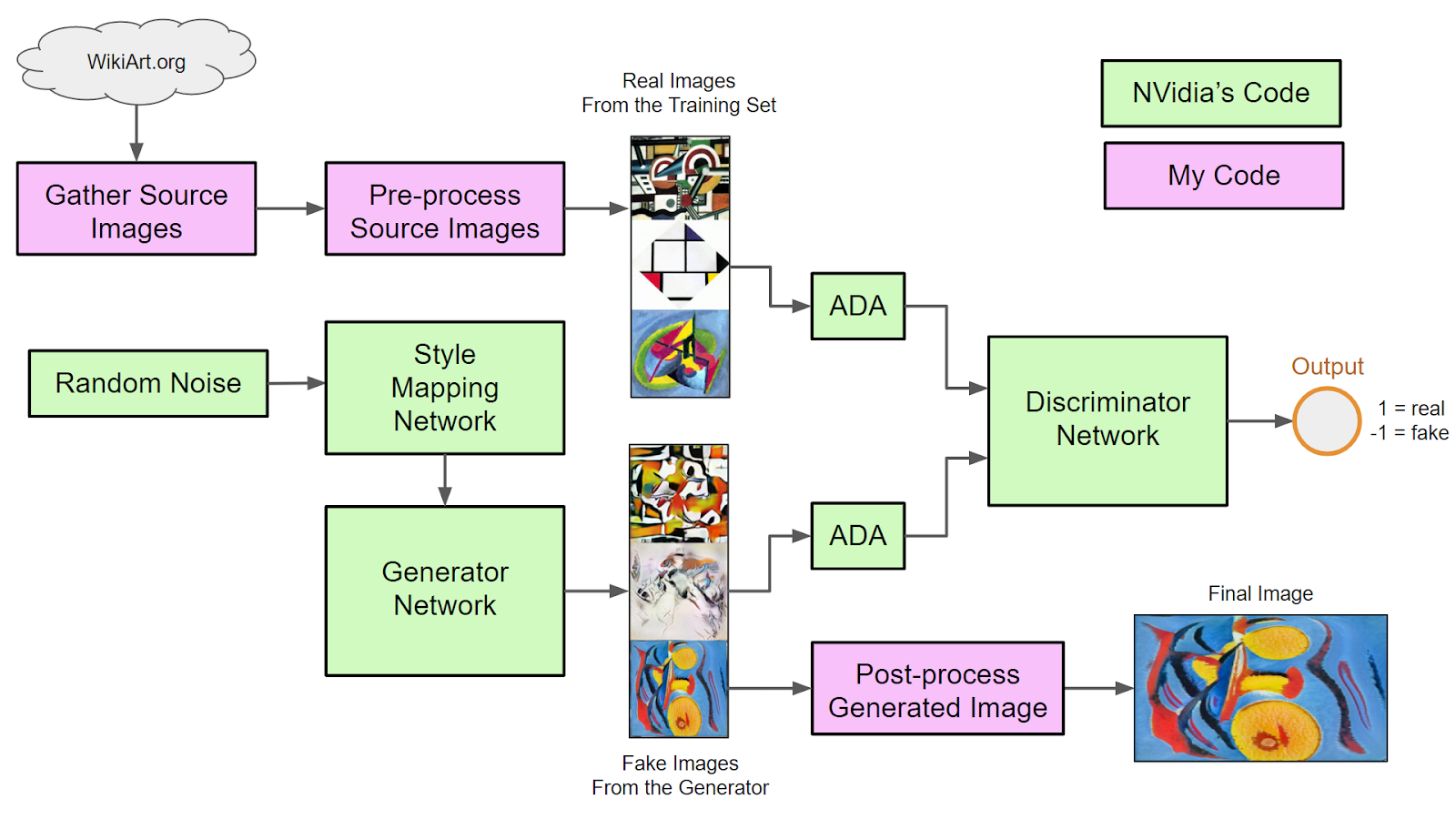
- Latent vector → Generador (G): A partir de un vector aleatorio z, el generador produce una imagen sintética x̂ usando convoluciones moduladas y weight demodulation, generando rostros realistas.
- Aumentaciones dinámicas (ADA): Se aplican transformaciones (traslaciones, flips, blur, jitter, etc.) tanto a imágenes reales como sintéticas. La probabilidad de cada transformación se ajusta dinámicamente: aumenta si el discriminador memoriza y disminuye si se confunde con facilidad.
- Discriminador (D): Recibe imágenes ya transformadas y devuelve un escalar f(x) que representa su “confianza” en que una imagen sea real.
- Funciones de pérdida:
- Para el generador: se busca maximizar f(x̂) (es decir, que el discriminador considere reales las imágenes generadas).
- Para el discriminador: se maximiza la diferencia f(x) – f(x̂), penalizando imágenes falsas y recompensando las reales.
- Actualización alterna: Se actualiza únicamente uno de los dos modelos en cada iteración para preservar la estabilidad del entrenamiento.
La característica clave de StyleGAN2-ADA es que los aumentos afectan únicamente al discriminador y no al generador. Esto obliga al generador a generalizar mejor, produciendo imágenes realistas desde el punto de vista geométrico y textural, sin memorizar ejemplos concretos.
Estado del arte
Desde su aparición en 2014, las Redes Generativas Adversarias (GANs) han revolucionado la generación de contenido sintético, en especial de imágenes faciales. Su evolución ha dado lugar a modelos más precisos y controlables, destacando StyleGAN (NVIDIA, 2018) y sus sucesores StyleGAN2 y StyleGAN3, que introducen innovaciones como la manipulación jerárquica del espacio latente y una mayor estabilidad en el entrenamiento [3]. Estas mejoras han permitido crear rostros sintéticos de alta resolución, como demuestra el sitio This Person Does Not Exist [4].
Con estos avances, surgió la necesidad de métricas adecuadas para evaluar la calidad de las imágenes generadas. En entornos no supervisados, métricas como el Inception Score (IS) y la Fréchet Inception Distance (FID) se utilizan ampliamente para medir fidelidad y diversidad respecto a los datos reales.
Más recientemente, se han adoptado métricas como la Intersección sobre la Unión (IoU), originalmente usada en segmentación, para evaluar detalles internos como la forma del iris o la geometría facial. Estas herramientas permiten detectar anomalías sutiles que podrían pasar desapercibidas visualmente.
Fundamentos matemáticos de las GANs
Las Generative Adversarial Networks (GANs) operan mediante un juego de minimax entre dos redes neuronales: un generador, que crea datos sintéticos, y un discriminador, que los distingue de los reales [5]. La función de costo que guía este proceso es:
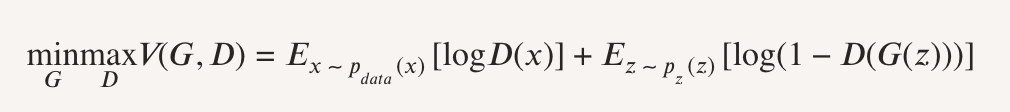
El discriminador maximiza la función de pérdida para mejorar su clasificación, mientras que el generador la minimiza para engañarlo. Este proceso iterativo busca un equilibrio de Nash, donde los datos sintéticos se vuelven casi indistinguibles de los reales, clave en tareas como generación de imágenes y mejora visual.
StyleGAN, una variante avanzada desarrollada por NVIDIA, introduce un mapeo del espacio latente y un control del estilo en distintos niveles. En lugar de pasar el ruido directamente al generador, se transforma en un espacio latente intermedio ww:

Para ajustar el estilo de las imágenes, StyleGAN emplea Adaptive Instance Normalization (AdaIN):
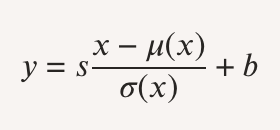
Donde ss y bb son parámetros generados por ww para controlar el estilo. Además, el discriminador utiliza un aprendizaje progresivo que mejora la resolución gradualmente. Este enfoque permite a StyleGAN generar imágenes hiperrealistas con un control detallado de su apariencia.[6]
Desarrollo: Pipeline de Detección y Segmentación del Iris en Imágenes Sintéticas
Aproximación Inicial: DC-GAN
Al iniciar el proyecto optamos por usar una GAN sencilla basada en la arquitectura DC-GAN tradicional del notebook de Kaggle/Colab «Generating Fake Faces Using GAN», enlace: https://colab.research.google.com/drive/1EoAaNGRp6O4ZGZZVIZWXJaXh2ndGzlUo). Se buscó generar retratos con recursos mínimos para el pipeline ocular, usando imágenes de 128 × 128 px, resolución baja pero suficiente para identificar el iris, y un vector latente de 100 dimensiones con distribución normal 𝒩(0, 1), estándar en estudios previos.
El generador se construyó como una secuencia de capas Dense hasta un tensor 128 × 128 × 3, seguido de varios bloques alternos de Conv2D / Conv2D-Transpose, normalización por lotes y activaciones LeakyReLU.


Este patrón, heredado de la DC-GAN clásica, resulta fácil de depurar y de entrenar sin técnicas de estabilización costosas.
En el discriminador se repitió la simetría inversa: convoluciones con stride 2 para reducir la resolución, normalización, Leaky ReLU y una capa densa sigmoide final.


Aunque la propuesta inicial parecía viable, los resultados tras 5 y 15 épocas fueron insatisfactorios: las imágenes eran solo ruido coloreado. Las pruebas revelaron tres problemas clave:
- Resolución insuficiente: A 128 px, el iris apenas ocupaba unos pocos píxeles, dificultando su definición.
- Falta de regularización: Sin técnicas como normalización espectral o gradient penalty, el discriminador aprendía demasiado rápido, causando mode collapse.
- Limitaciones de tiempo: Se estimaba que se requerían al menos 50 épocas (~12 horas de GPU) para obtener resultados aceptables, algo inviable en el entorno disponible.

Imágenes generadas por DC-GAN tras 5 épocas

Imágenes generadas por DC-GAN tras 15 épocas
Con estos obstáculos concluimos que el modelo del notebook, aunque proporcionó una plataforma rápida de arranque, la falta de recursos computacionales y la resolución limitada, no era viable como fuente de datos y decidimos migrar a una solución preentrenada de alta fidelidad: StyleGAN2-ADA, descrita en la siguiente sección.
Migración a siguiente solución: StyleGAN2-ADA
La elección natural fue StyleGAN2-ADA, la variante de NVIDIA que combina la potencia de StyleGAN2 con el módulo Adaptive Discriminator Augmentation (ADA). Este sistema ya estaba disponible con pesos preentrenados sobre FFHQ a 1 024 px, de modo que podíamos generar imágenes realistas sin ningún entrenamiento adicional.
Ciclo de entrenamiento StyleGAN2-ADA
Para ello, hemos desarrollado el siguiente código:
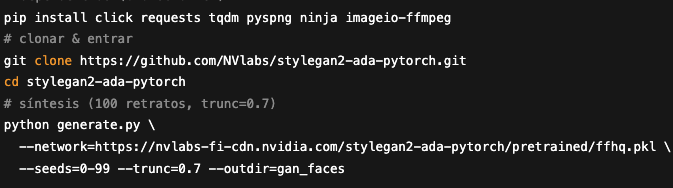
Este bloque de comandos prepara el entorno y produce las imágenes sintéticas: instala dependencias ligeras que exige StyleGAN2-ADA (gestión de CLI, descargas, decodificador PNG, compilador ninja y soporte de vídeo), clona la implementación oficial en PyTorch desde GitHub, entra en ese directorio y ejecuta generate.py con el modelo FFHQ preentrenado. El script recorre las semillas 0-99, aplica una truncación de 0,7 (compromiso entre variedad y nitidez) y guarda los 100 retratos resultantes en la carpeta gan_faces/.

Imágenes generadas por StyleGAN2-ADA
Proceso de selección de imágenes generadas por StyleGAN2-ADA
Tras generar los rostros, se realiza una filtración manual en la carpeta gan_faces/ para conservar solo las imágenes de calidad, descartando aquellas que no sean frontales, tengan baja resolución o estén borrosas, presenten errores de renderizado o distorsiones, o contengan artefactos visuales producidos por la GAN.
A continuación, se muestran ejemplos de imágenes descartadas por no cumplir estos criterios:

Evaluación de fidelidad en iris
Para evaluar la fidelidad del iris en imágenes generadas por GAN, usamos un código de GitHub especializado en detección y segmentación del iris y reflejos (https://github.com/discovershu/gan_detect_iris) , útil en análisis forense. El proceso comienza con la detección automática de ojos, seguida de la segmentación de la córnea e iris, identificando también reflejos. Se calcula la métrica IoU para medir la precisión comparando con máscaras reales. La imagen final muestra la segmentación aplicada, y la función main automatiza todo el procedimiento usando las imágenes en la carpeta /data.
(Explicamos su funcionamiento más en detalle en el siguiente enlace: https://docs.google.com/document/d/19txjgz4XA9FPudsFvBX-HquBL2o_8WmhtIA_-UXGuCk/edit?tab=t.0.)
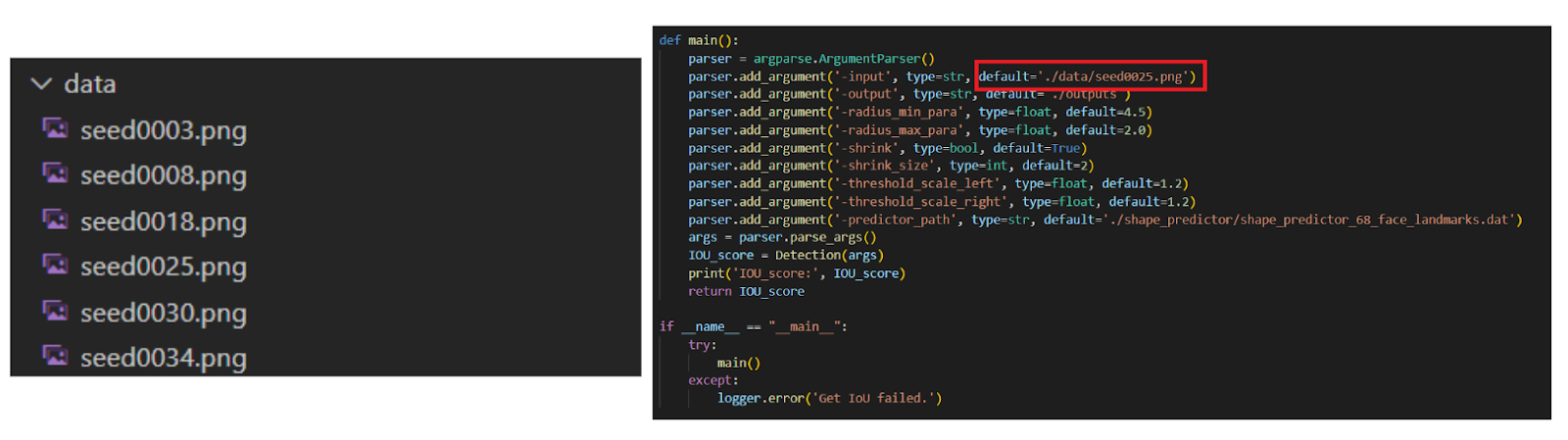
Resultados y conclusiones
Se procesaron seis retratos generados por StyleGAN2‑ADA. Todos se escalaron a 1 024 × 1 024 px y pasaron sin modificaciones por el pipeline del repositorio, obteniendo los siguientes resultados:
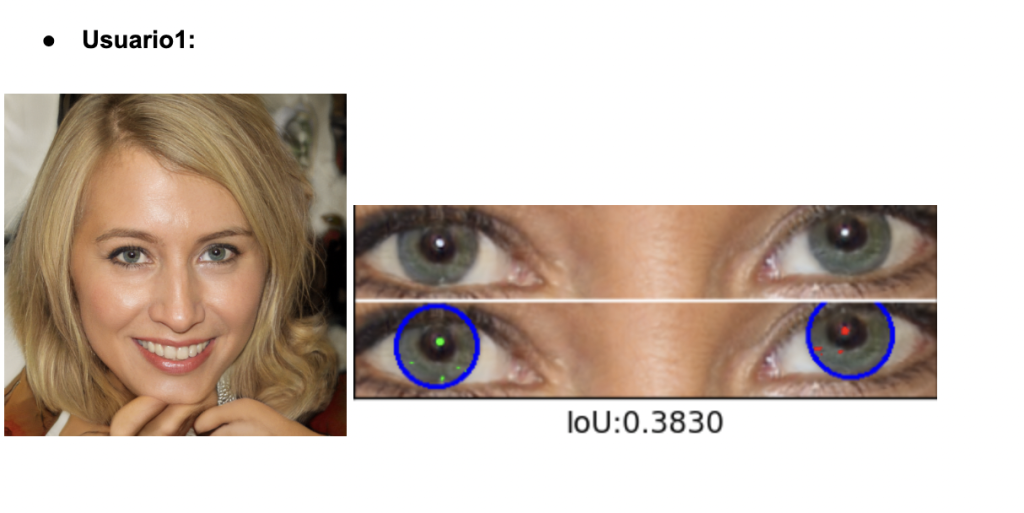
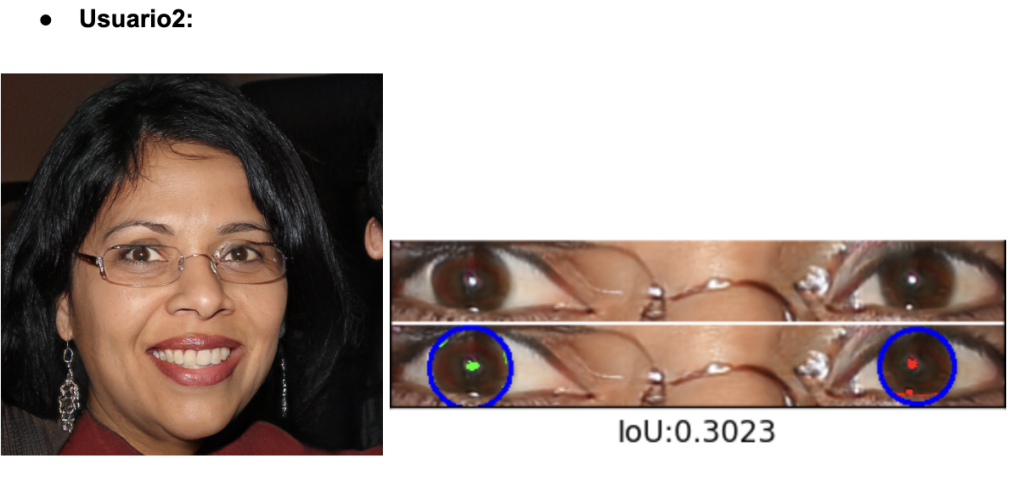
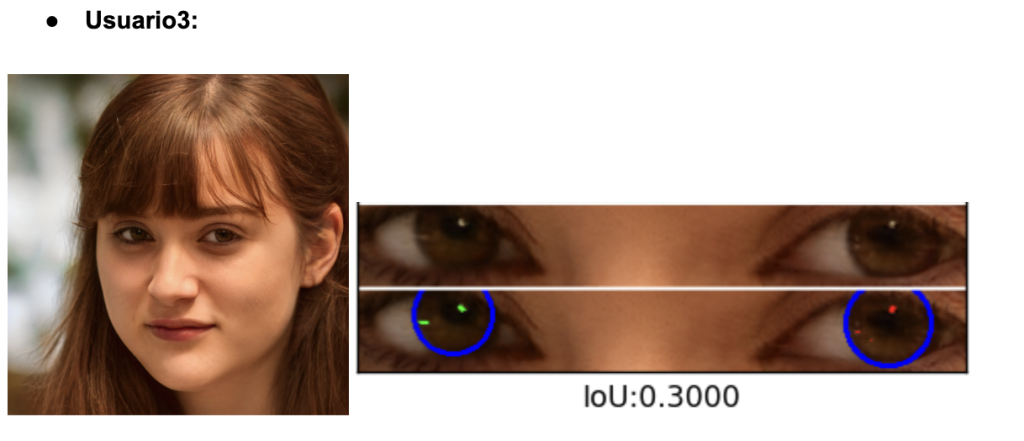
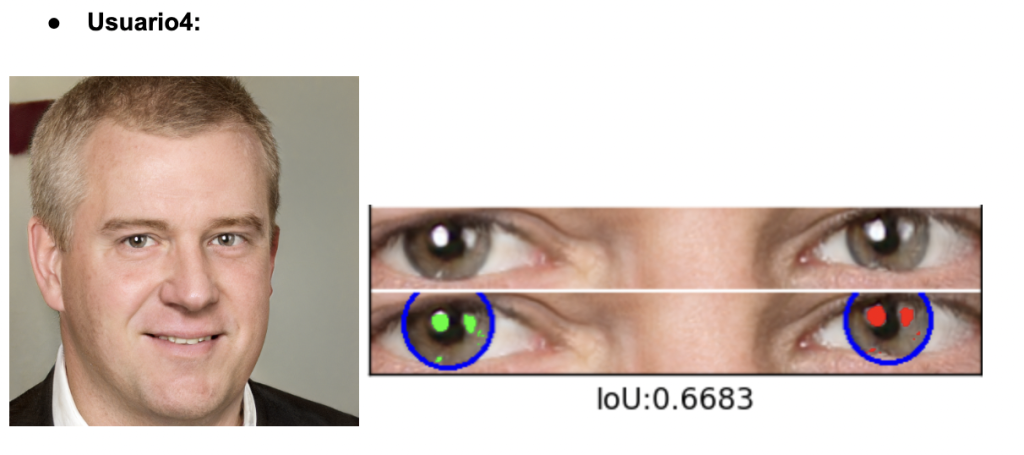
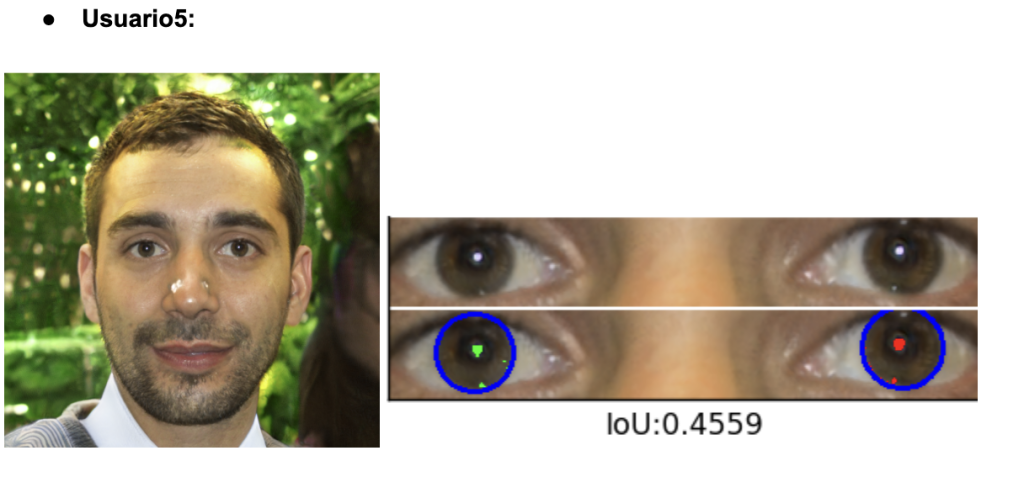
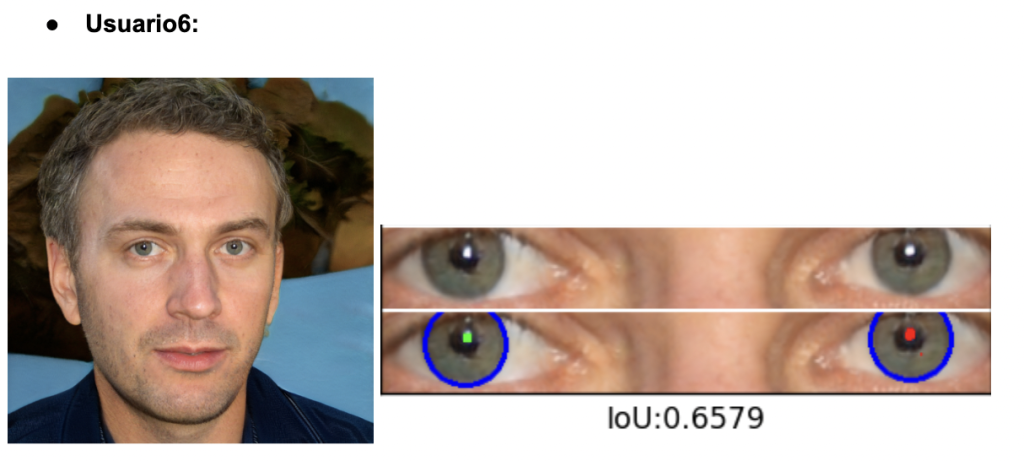
El análisis de los valores de IoU revela una variabilidad significativa en la calidad de segmentación del iris en imágenes generadas por StyleGAN2-ADA. Usuarios 1, 2 y 3 presentan puntuaciones bajas (alrededor de 0.30), lo que indica que las máscaras segmentadas no coinciden bien con la geometría ocular real. Esto sugiere errores en la generación, como contornos irregulares, artefactos visuales o reflejos mal colocados que dificultan la segmentación automática. En cambio, los usuarios 4 y 6 superan el umbral biométrico de 0.50, reflejando una segmentación más precisa y una estructura del iris más realista. El Usuario 5 se sitúa en un punto intermedio, lo que indica una calidad aceptable pero aún con margen de mejora.
Conclusiones finales
Las GANs, especialmente StyleGAN2-ADA, han supuesto un avance significativo en la generación de imágenes faciales realistas, integrando mecanismos que mejoran la estabilidad y calidad del entrenamiento con conjuntos de datos limitados. Sin embargo, persisten desafíos importantes en la reproducción fiel de detalles específicos, como la estructura del iris, lo que limita su aplicabilidad en ámbitos biométricos y forenses. Los resultados muestran que, aunque las imágenes sintéticas alcanzan un alto nivel visual, la precisión en elementos finos aún requiere optimización. Por tanto, es fundamental continuar mejorando las arquitecturas y desarrollar métricas especializadas que evalúen estos detalles para garantizar un uso confiable y seguro de estas tecnologías.
Consideraciones éticas de la tecnología deepfake
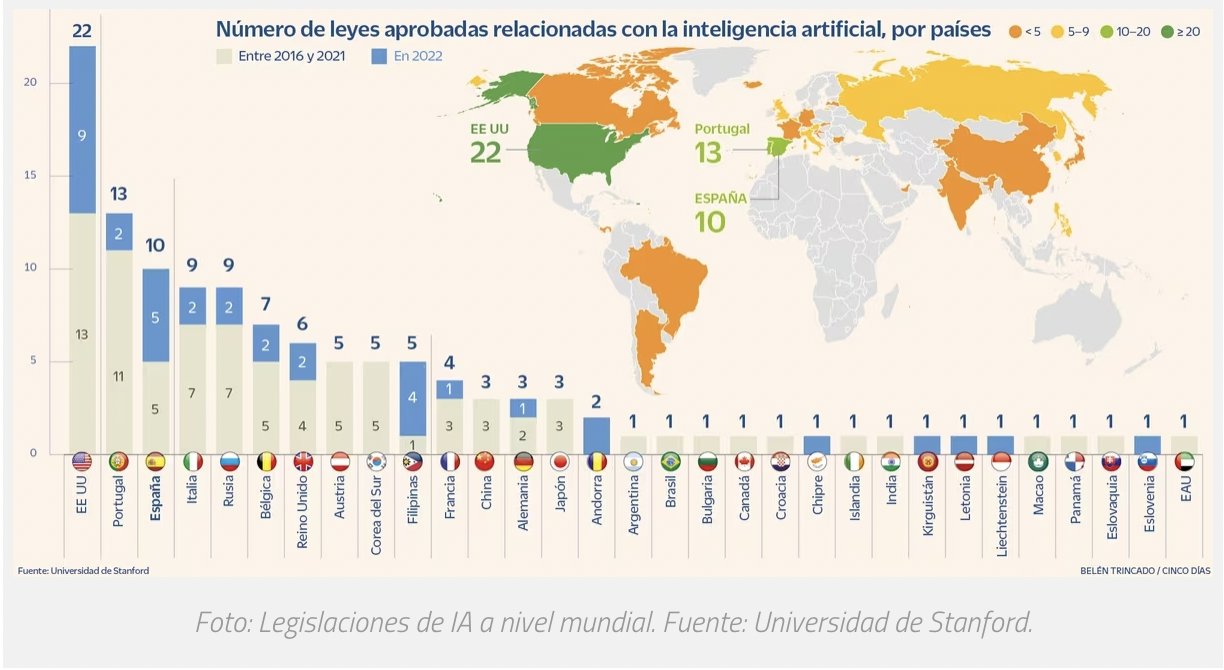
Las tecnologías deepfake presentan desafíos éticos relacionados con la privacidad, la manipulación y la regulación. Por un lado, permiten la suplantación de identidad, afectando la autonomía individual y exponiendo a las personas al robo de identidad digital mediante datos biométricos. También generan desinformación masiva, alterando debates públicos y dañando reputaciones, lo que debilita la confianza en instituciones y medios de comunicación [7] .Aunque tienen aplicaciones en cine y educación, la recreación de personas fallecidas sin consentimiento plantea dilemas éticos. Para mitigar riesgos, se necesitan leyes específicas que regulen su uso, distinguiendo entre aplicaciones legítimas y maliciosas, además de promover la alfabetización digital para que los ciudadanos puedan identificar contenido manipulado [7]. La creciente cantidad de leyes aprobadas sobre IA en distintos países demuestra la urgencia de una regulación que proteja derechos sin frenar la innovación.
BIBLIOGRAFÍA
[1] Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2019). A Style-Based Generator Architecture for Generative Adversarial Networks. arXiv. https://arxiv.org/abs/1812.04948
[2] Karras, T., Laine, S., Aittala, M., Hellsten, J., Lehtinen, J., & Aila, T. (2020). Analyzing and improving the image quality of StyleGAN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) (pp. 8110–8119). https://doi.org/10.1109/CVPR42600.2020.00813
[3] Salimans, T., Goodfellow, I., Zaremba, W., Cheung, V., Radford, A., & Chen, X. (2016). Improved Techniques for Training GANs. arXiv. https://arxiv.org/abs/1606.03498
[4] This Person Does Not Exist. https://thispersondoesnotexist.com/
[5] Wikipedia. (2024). StyleGAN. https://en.wikipedia.org/wiki/StyleGAN
[6] Moralo García, J. (s. f.). Generative Adversarial Networks (GAN): Una introducción. LinkedIn. https://www.linkedin.com/pulse/generative-adversarial-networks-gan-una-introducci%C3%B3n-moralo-garc%C3%ADa/
[7] E. Gutiérrez Rojas, “Deepfakes y sus implicaciones éticas. Reflexiones desde la filosofía de la tecnología,” Rev. Iberoam. Cienc. Tecnol. Soc., vol. 19, no. 2, pp. 359–377, 2024. [En línea]. Disponible en: https://www.scielo.org.mx/scielo.php?script=sci_arttext&pid=S2448-51362024000200359
MATERIALES
Generación de caras falsas con GAN – 5 epochs [Notebook de Google Colab]. Disponible en: https://colab.research.google.com/drive/1yEOGNy69QNel4DK4IeMvE0a09cB0swt2
Generación de caras falsas con GAN – 15 epochs [Notebook de Google Colab]. Disponible en: https://colab.research.google.com/drive/1EoAaNGRp6O4ZGZZVIZWXJaXh2ndGzlUo
theblackmamba31. (s.f.). Generating Fake Faces Using GAN [Kaggle Notebook]. Disponible en: https://www.kaggle.com/code/theblackmamba31/generating-fake-faces-using-gan
PASD – BLOG: Generación de datos sintéticos con StyleGAN2-ADA [Notebook de Google Colab]. Disponible en: https://colab.research.google.com/drive/1tsblpAyWbwHpw6Yd7kVFpug0XuHzM9Ec
Shu, Y. (2021). gan_detect_iris [GitHub repository]. Disponible en: https://github.com/discovershu/gan_detect_iris