Introducción
Las redes generativas antagónicas (GANs) son un tipo de arquitectura de inteligencia artificial que ha revolucionado la generación de contenido sintético. Fueron propuestas en 2014 por el investigador Ian Goodfellow y, desde entonces, han sido ampliamente utilizadas para crear imágenes, sonidos y vídeos que imitan datos reales con sorprendente realismo.

El funcionamiento básico de una GAN se basa en dos redes: un generador, que intenta crear datos falsos realistas, y un discriminador, que intenta distinguir entre datos reales y generados. Este enfoque se inspira en una dinámica competitiva que permite a ambas redes mejorar a lo largo del entrenamiento. Tanto el generador como el discriminador utilizan redes convolucionales (CNN) para procesar la información de entrada [1], [2].

No obstante, a pesar de su enorme potencial, entrenar correctamente una GAN es una tarea compleja. En este blog se exploran de forma práctica algunos de los problemas más comunes que surgen durante el entrenamiento de estas redes. Para ello, se han realizado experimentos utilizando el conjunto de datos MNIST y se han inducido tres errores habituales: desbalance en las tasas de aprendizaje, colapso modal y desvanecimiento de gradientes provocado por funciones de activación inapropiadas. El objetivo es comprender cómo estos factores afectan al rendimiento del modelo.
Estado del arte
Desde su introducción, las GANs han sido objeto de numerosas investigaciones debido a su capacidad para generar datos sintéticos de alta calidad. Estas redes han permitido avances importantes en áreas como la edición de imágenes, la creación de rostros humanos artificiales y la generación de contenido en videojuegos y cine [4], [5].
Sin embargo, su entrenamiento es notoriamente difícil, ya que implica mantener un equilibrio entre dos redes que aprenden simultáneamente. Uno de los problemas más comunes es el colapso modal, que ocurre cuando el generador produce una variedad limitada de salidas, ignorando otras posibles representaciones del conjunto de datos. Este fenómeno reduce la diversidad de las muestras generadas y limita la utilidad del modelo [1].
Otro desafío significativo es el desbalance entre el generador y el discriminador. Si uno de los modelos aprende más rápido que el otro, puede dominar el proceso de entrenamiento, impidiendo que ambos mejoren conjuntamente. Este desequilibrio puede llevar a una mala convergencia o incluso a la ausencia total de convergencia [2], [6].
Además, el uso de funciones de activación inadecuadas, como la función sigmoide en capas intermedias, puede provocar el desvanecimiento de gradientes. Este problema ocurre cuando los gradientes se vuelven extremadamente pequeños, dificultando la actualización efectiva de los pesos y, por ende, el aprendizaje del modelo.
Para abordar estos problemas, se han propuesto diversas soluciones. Por ejemplo, las Wasserstein GANs (WGANs) introducen una función de pérdida basada en la distancia de Wasserstein, proporcionando gradientes más estables y mejorando la convergencia. Asimismo, técnicas como la normalización espectral se han utilizado para estabilizar el entrenamiento del discriminador.
A pesar de estos avances, estudios recientes han demostrado que muchas de estas mejoras no generalizan bien y que el rendimiento de las GANs depende en gran medida del conjunto de datos, la arquitectura elegida y la configuración de los hiperparámetros [3]. Por lo tanto, es esencial comprender a fondo los problemas inherentes al entrenamiento de las GANs y desarrollar enfoques más robustos y generalizables.
Desarrollo del problema y discusión de resultados:
Vamos a enfocar el trabajo analizando en un código ejecutable [7] los distintos problemas que pueden surgir al trabajar con GANs (Generative adversarial networks). Hemos utilizado el dataset de MNIST [8] normalizando las imágenes cargadas, del rango [0, 1] al rango [-1, 1] pues después nuestro modelo funcionará mejor si están centradas en el 0:
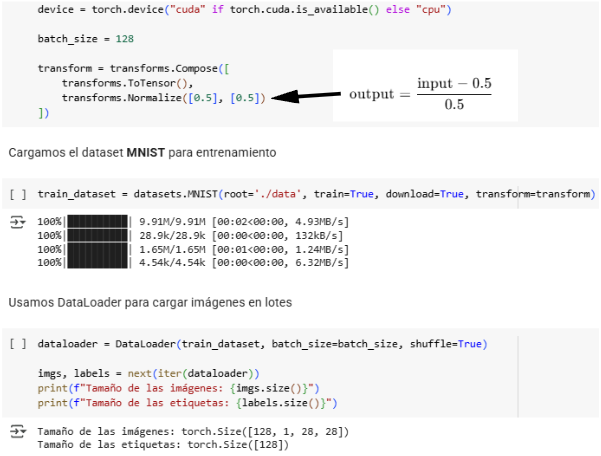
Como se trata de un Dataset sencillo, formado por imágenes de baja resolución (escala de grises) y con baja varianza intraclases; vamos a utilizar Perceptores Multicapa (MLP) tanto para el Generador como para el Discriminador.

A la hora de desarrollar el Generador, programamos una red neuronal (MLP) que toma un vector aleatorio (ruido) y genera una imagen de tamaño (1, 28, 28). Usa capas Linear (combinaciones lineales para conectar neuronas) y LeakyReLU (función de activación donde se ajustan los pesos) con normalización por lotes (BatchNorm1d) para mejorar el entrenamiento. La última capa usa Tanh para producir valores en [-1, 1] (acorde a la normalización de las imágenes MNIST).
En cuanto al discriminador, deberemos ahora programar una red discriminadora la cual a través de las imágenes falsas generadas por el Generador, deberá distinguirlas entre reales o falsas. Volvemos a emplear capas lineales y funciones de activación RELU pero en este caso la última capa usa una función de activación Sigmoide, ideal para la clasificación 1 imagen verdadera 0 imagen falsa.
Ambas redes son heredadas de las redes Generator y Discriminator del módulo nn de Pytorch [10] solo que cambiando sus estructuras básica y los métodos forward

Una vez tenemos ambas redes, inicializamos la red general. Es decir, la GAN con una función de pérdida Binaria (BCELoss del módulo nn).
Posteriormente, tenemos que entrenar la red para poder trabajar con ella y ver los inconvenientes que pueden surgir si lo hacemos incorrectamente. En un periodo de 50 épocas, entrenamos con todas las imágenes del dataset, por un lado el discriminador y por otro lado el generador, además analizamos su rendimiento época a época. Calculamos las funciones de pérdida:
- Discriminador: del dataset antes cargado, sacamos una etiqueta verdadera y una falsa (1, 0). Seguidamente, del dataset sacamos una imagen verdadera y vemos como la discrimina el discriminador frente a la etiqueta verdadera (función de pérdida de la verdadera). Luego, mediante ruido gaussiano, generamos una imagen falsa (uso del Generador) y calculamos su función de pérdida comparándola con la etiqueta falsa. Finalmente computamos la función de pérdida definitiva como el promedio de ambas.
- Generador: Calculamos la función de pérdida del generador simplemente comparando la imagen generada a partir del ruido, con la verdadera del dataset.
Importante mencionar que es tras el cálculo de cada función de pérdida (tanto en la red generadora como discriminadora), cuando realizamos el entrenamiento. Actualizamos los pesos mediante el Descenso del Gradiente. Obtenemos el siguiente gráfico evolución de la pérdida del Discriminador y Generador por época.

Viendo la pérdida del discriminador se mantiene estable, en torno a 0.6 y 0.7, y viendo la pérdida del generador, tiene más oscilaciones, pero también tiende a estabilizarse en el rango [0.7, 1.1], lo que es típico mientras aprende a producir imágenes más realistas. Esta evolución sugiere que el entrenamiento es razonablemente estable y ambos modelos están compitiendo de forma equilibrada.
Hemos podido observar el correcto funcionamiento de una GAN con un dataset MNIST. Pero nos gustaría profundizar en los inconvenientes que pueden tener las GAN’s en algunas situaciones concretas o con algunas configuraciones previas erróneas. Uno de los problemas principales de estas redes neuronales es el tiempo, y esto lo hemos podido comprobar en la ejecución anterior, que para completar el entrenamiento entero han pasado 12 minutos, bastante tiempo a pesar de emplear muchos recursos en ello (GPU de Google Colab + CPU del dispositivo Torch).
Para mostrar otros 3 inconvenientes hemos generado 3 experimentos y hemos ejecutado el código anterior con cada actualización errónea (15 épocas en vez de 50 para demostración).
- Desbalance en tasas de aprendizaje: hacemos que el discriminador aprenda demasiado rápido subiendo su tasa de aprendizaje y provocando que el generador nunca aprenda (no genere imágenes parecidas a las reales).
- Colapso modal (ruido fijo): Simulamos el colapso inicializando siempre con la misma entrada de ruido, el generador se estanca y siempre produce imágenes reales.
- Gradientes desvanecidos por funciones de activación pobres: Funciones de activación como la Sigmoid en capas intermedias hace que los gradientes se vuelvan muy pequeños y por ende la red deja de aprender (no se actualizan los pesos). Para ello crearemos un nuevo generador que sustituya las capas LeakyReLU por Sigmoides.
Por último compararemos las funciones de pérdida y las imágenes cada 5 épocas por cada experimento para ver visualmente la evolución del generador ante estos inconvenientes.
Experimento desbalance de entrenamiento de la red generadora

Se pueden ver imágenes muy ruidosas o completamente aleatorias. El generador no logra aprender una representación coherente del espacio de datos y el discriminador se estanca debido a su alto aprendizaje, por ello la función de pérdida se satura y está siempre en 50. La cuadrícula de imágenes muestra patrones que parecen ruido blanco.
Experimento colapso modal:

Se ven imágenes repetitivas o muy similares, a menudo centradas en una sola clase (por ejemplo, el número “3”). Mejora de calidad en términos visuales, pero baja diversidad. El modelo parece generar dígitos legibles, pero siempre los mismos o con pequeñas variaciones. Las funciones de pérdida oscilan entre valores muy cercanos (0.6 — 0.7 (D) y 0.7 – 0.8 (G)).
Experimento activación pobre o gradientes desvanecidos:
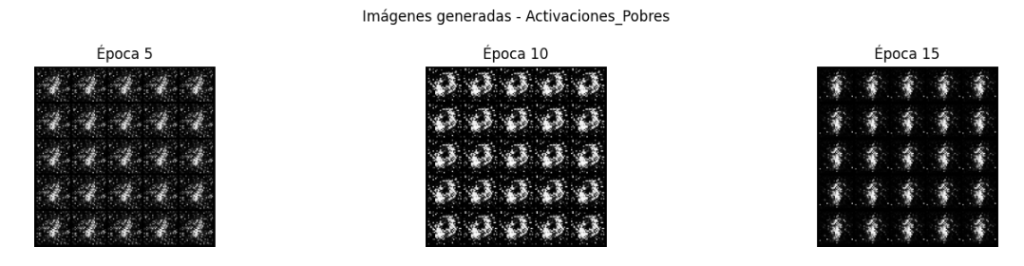
Se observan imágenes con un patrón muy tenue, borroso o con puntos repetitivos. Falta de contraste, estructura o forma reconocible. La función de pérdida del discriminador evoluciona de manera razonable en cambio la del generador sube sin control (el generador no aprende debido a los gradientes pobres).
Conclusión:
A lo largo del artículo hemos podido observar cómo las redes generativas antagónicas (GANs) pueden sufrir problemas significativos que comprometen su rendimiento comparándola con una red bien balanceada. A través de los tres experimentos realizados: desbalance entre generador y discriminador, colapso modal y gradientes desvanecidos; hemos simulado errores frecuentes que degradan la calidad de las imágenes generadas y los resultados esperados.
Aunque en estos experimentos los errores han sido forzados de manera intencionada y controlada para ilustrar sus efectos, es importante destacar que todos ellos pueden surgir de forma natural en escenarios reales si no se presta atención a ciertos detalles clave o por la propia naturaleza de estas redes. Por ejemplo, el colapso modal puede surgir incluso con entradas de ruido aleatorias si el generador no lo aprovecha correctamente (se queda estancado en una imagen que engaña), o si el discriminador no tiene mecanismos para identificar la falta de diversidad.
Otra desventaja de estas redes que ha estado presente transversalmente durante el trabajo es el tiempo de entrenamiento el cual aumenta exponencialmente cuando aumentamos la complejidad de los datos y la densidad del modelo.
En definitiva, estos problemas son comportamientos propios del diseño de las GANs y sus variedades y hemos de conocerlos y tenerlos en cuenta para evitar caer en soluciones engañosas.
Referencias
[1] MathWorks, “Redes Generativas Antagónicas (GAN),”. Disponible en: https://la.mathworks.com/discovery/generative-adversarial-networks.html
[2] IEBSchool, “¿Qué son las GAN? Las redes generativas que crean contenido realista,” Disponible en: https://www.iebschool.com/hub/redes-generativas-antagonicas-tecnologia/
[3] Imagenes apartado de introducción: https://drive.google.com/file/d/1hG5iBGN-eoPrnZYo-BDefeuKs947fBq_/view?usp=drive_link
[4] TechAffinity, “Redes Generativas Antagónicas: ¿Qué son y cómo funcionan?,” 2021. Disponible en: https://techaffinity.com/blog/redes-adversarias-generativas/
[5] Wikipedia, “Red generativa adversativa,”. Disponible en: https://es.wikipedia.org/wiki/Red_generativa_adversativa
[6] Keep Coding, “Redes Generativas Antagónicas (GAN): Guía 2025,”. Disponible en: https://keepcoding.io/blog/que-son-redes-generativas-antagonicas/
[7] Notebook, “Código GANs” . Disponible (con ejemplo extendido) en https://colab.research.google.com/drive/1PVajOyfbCdDjSPVI-ysbeibpDzduM80O?usp=sharing
[8] MNIST Dataset. Kaggle. Disponible en https://www.kaggle.com/datasets/hojjatk/mnist-dataset
[9] Kishore, N. G. Multi Layer Perceptron. LinkedIn. Recuperado de https://www.linkedin.com/pulse/multi-layer-perceptron-kishore-ng-wvrcc/
[10] PyTorch. torch.nn — PyTorch 2.0 documentation. Disponible en https://docs.pytorch.org/docs/stable/nn.html
Créditos:
– Sergi Jabega Bolívar: Introducción y Estado del Arte.
– Nacho Moyano Fernández: Desarrollo del problema y discusión de resultados.
– Sergio González Gironés: Extrapolación de los experimentos al dataset CIFAR-10 (en el nootebook) y Conclusiones.
– Juan Pérez Picciolato: Desarrollo del problema y discusión de resultados y Conclusiones.