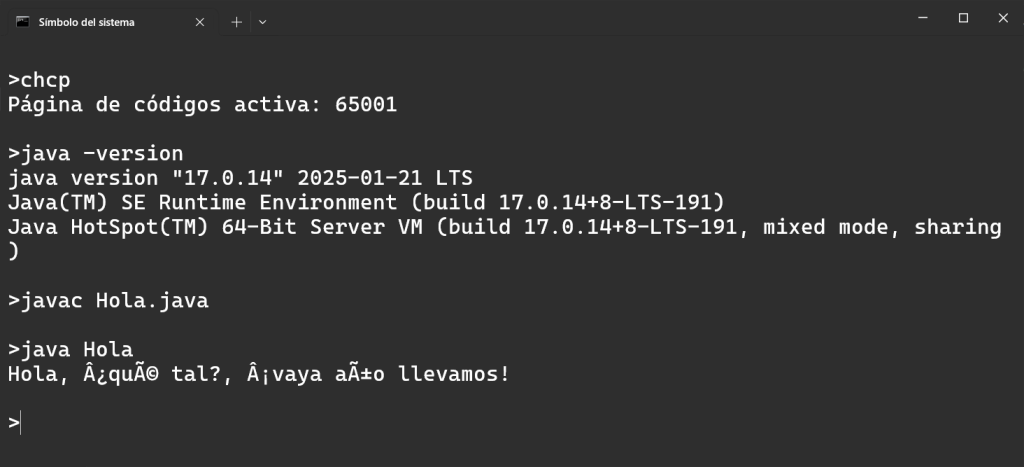
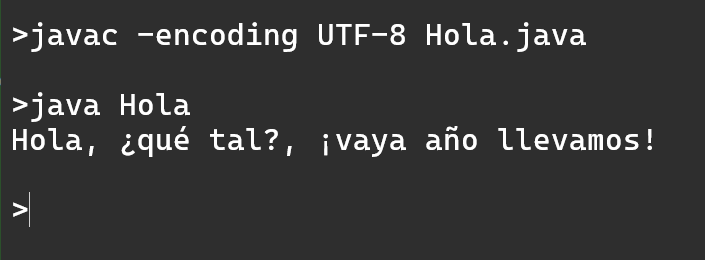
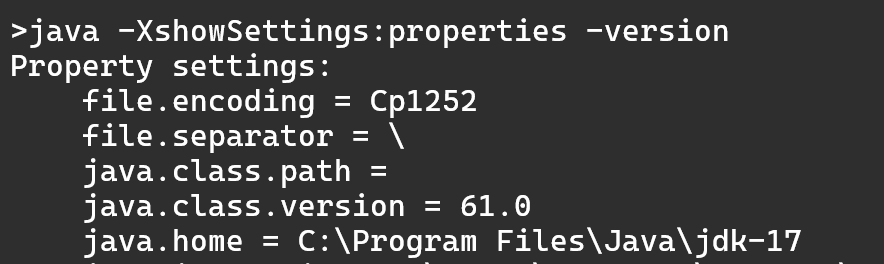
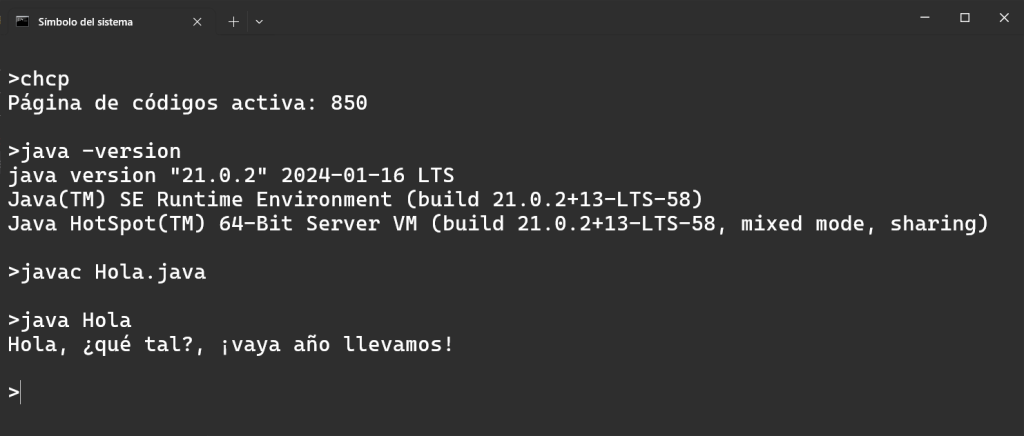
El Locale es la configuración regional que le dice a un programa informático cómo mostrar y formatear datos según un idioma, país y cultura específicos.
El Locale afecta a la forma de mostrar diversos elementos:
- Números: separador decimal, miles
- Fechas: DD/MM/YYYY vs MM/DD/YYYY
- Moneda: €1.234,56 vs $1,234.56
- Mayúsculas/minúsculas: Ñ → ñ (turco: i → İ)
- Ordenación: ñ después de n en español
Por ejemplo, según el Locale seleccionado, estas serían distintas formas de mostrar el mismo número 1234.56:
🇺🇸 USA (en_US): 1,234.56
🇪🇸 España (es_ES): 1.234,56
🇩🇪 Alemania (de_DE): 1.234,56
🇫🇷 Francia (fr_FR): 1 234,56
🇯🇵 Japón (ja_JP): 1,234.56
El Locale consta de un idioma, un país y, opcionalmente, una variante. Por ejemplo:
Locale = Idioma + País [+ Variante]
ej: es_ES → español (España)
en_US → inglés (Estados Unidos)
pt_BR → portugués (Brasil)Al arrancar el sistema operativo (Windows, Linux, Mac,…) se carga un Locale por defecto que es el que usarán nuestros programas Java, salvo que indiquemos otra cosa.
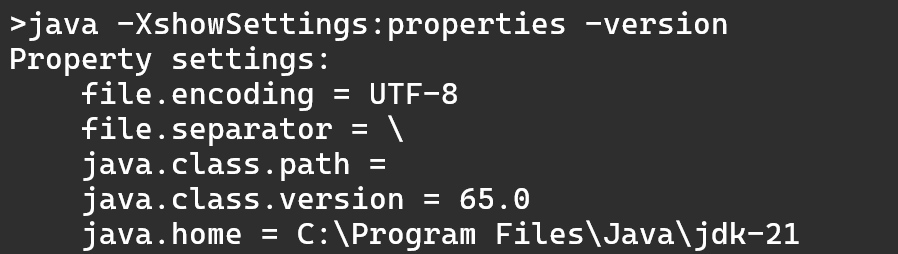
Puedes comprobar el Locale que tienes cargado en el ordenador mediante la siguiente instrucción:
System.out.println(Locale.getDefault());En mi caso, la salida ha sido:
es_ESque corresponde al idioma español de España.
El Locale afecta a la forma de leer o escribir números double, ya sea en el terminal o en ficheros de texto.
Dentro de nuestros programas, podemos establecer el Locale de la siguiente forma:
Locale.setDefault(Locale.UK); // Locale del Reino Unido
Locale.setDefault(Locale.US); // Locale de Estados Unidos
Locale.setDefault(new Locale("es", "ES"));Imprimir números double
Si se utilizan los métodos print() o println(), los números double se imprimen utilizando el punto como separador de decimales, independientemente del Locale activo en el ordenador:
System.out.println(1234.56); // Imprime 1234.56El comportamiento es diferente cuando se usan métodos printf(). Con la configuración en español, cuando imprimimos un número double utilizando la instrucción printf(), el separador de decimales será la coma, no el punto:
System.out.printf("%.2f%n", 1234.56); // Imprime 1234,56Si queremos que, además del separador de decimales, se imprima el separador de miles, hay que añadir al especificador de formato una coma antes del punto decimal:
System.out.printf("%,.2f%n", 1234.56); // Imprime 1.234,56Si queremos forzar el uso del punto como separador de decimales podemos hacer:
Locale.setDefault(Locale.UK); // Locale del Reino Unido
System.out.printf("%.2f%n", 1234.56); // Imprime 1234.56
System.out.printf("%,.2f%n", 1234.56); // Imprime 1,234.56Este comportamiento al escribir es el mismo cuando se escribe en el terminal o cuando se escribe en ficheros de texto.
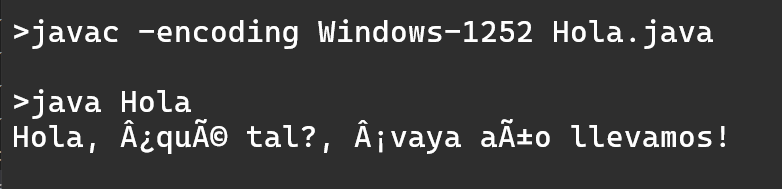
¿Y por qué los métodos print() y println() utilizan siempre el punto como separador de decimales, independientemente del Locale que haya activo? La razón es que, internamente, estos métodos convierten los números double a cadena de texto utilizando el método toString() de la clase Double y dicho método no utiliza ningún formato regional, siempre utiliza el punto decimal en la conversión.
Hay que tener claras dos cosas:
- Internamente, los números double no se ven afectados de ninguna manera por el Locale del ordenador. La representación interna del número utiliza otro tipo de evaluación, el Locale solo afecta a la representación textual del número al hacer entradas o salidas desde el terminal o desde ficheros de texto.
- Al codificar, al escribir los programas, tenemos que utilizar siempre el punto como separador de decimales.
Leer números double
Con el ordenador usando el Locale español, si leemos un número double desde el terminal utilizando el método nextDouble() de la clase Scanner, deberá estar escrito con la coma como separador de decimales. Si el número está escrito con el punto, el programa lanzará una excepción y se interrumpirá abruptamente.
Prueba el siguiente programa:
package principal;
import java.util.Locale;
import java.util.Scanner;
public class Main {
public static void main(String[] args) {
System.out.println(Locale.getDefault());
Scanner sc = new Scanner(System.in);
System.out.print("Teclee un número con decimales: ");
double x = sc.nextDouble();
sc.close();
}
}He ejecutado el código en mi ordenador, configurado con Locale español y he tecleado el número utilizando el punto como separador de decimales. El resultado ha sido el siguiente:
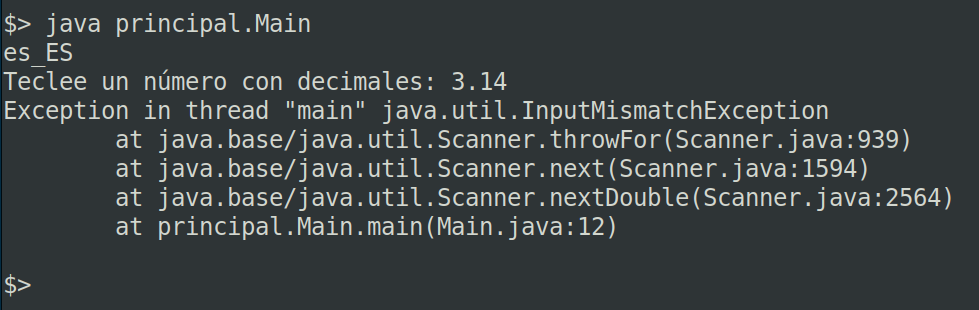
Observa que el programa lanza una excepción del tipo InputMismatchException y se interrumpe.
He repetido la ejecución pero, en esta ocasión, he tecleado el número utilizando la coma como separador de decimales:

Observa que ahora el programa ha funcionado correctamente.
La clase Scanner ofrece el método setLocale(), que permite elegir un determinado Locale en las lecturas que haga. Por ejemplo, en el código siguiente, el primer double se lee utilizando el Locale del Reino Unido y, el segundo, utilizando el Locale español:
Scanner sc = new Scanner(System.in);
sc.useLocale(Locale.UK);
double x = sc.nextDouble(); // Espera leer 3.14
sc.useLocale(new Locale("es", "ES"));
double y = sc.nextDouble(); // Espera leer 3,14Leer cadenas de texto y convertirlas en double
Otra técnica que puede ser útil al leer números con Scanner es leer una línea de texto con nextLine() y luego convertir la cadena leída a double utilizando el método estático parseDouble() de la clase Double.
El método Double.parseDouble(), al igual que sucede con el método toString(), siempre trabaja con el punto como separador de decimales. El siguiente ejemplo, leería un número double que debería estar escrito con punto decimal:
double z = Double.parseDouble(sc.nextLine());Imponer un Locale para todo el programa
En programas profesionales, si no tomamos precauciones, puede resultar que la ejecución sea diferente según el Locale del ordenador en el que se esté ejecutando el programa. Por tanto, es necesario tomar medidas de forma que la ejecución siempre sea la misma, independientemente del Locale que esté configurado en el ordenador en el que se ejecute el programa.
Podemos imponer al principio del programa que se utilice un Locale determinado. Esta solución afectará tanto a las entradas que hagamos a través de objetos Scanner como a las salidas que hagamos con métodos printf(). Por ejemplo, podríamos imponer el Locale del Reino Unido o el de Estados Unidos y forzar a que las entradas y salidas de números decimales haya que hacerlas usando el punto como separador de decimales. La instrucción sería una de las dos siguientes:
Locale.setDefault(Locale.UK);
Locale.setDefault(Locale.US);Otra opción sería imponer el Locale español de España. Para seleccionar el Locale de España no disponemos de una constante predefinida como en los casos anteriores y la instrucción que habría que poner al principio del programa sería:
Locale.setDefault(new Locale("es", "ES"));También es posible imponer el Locale pasando un parámetro a la Máquina Virtual de Java al ejecutar el programa. Si ejecutamos desde el terminal y queremos imponer el Locale de Estados Unidos, habría que hacer:
java -Duser.language=en -Duser.country=US principal.MainEn Eclipse, podemos configurar la ejecución del programa y pasarle los argumentos a la JVM, como se muestra en la figura:
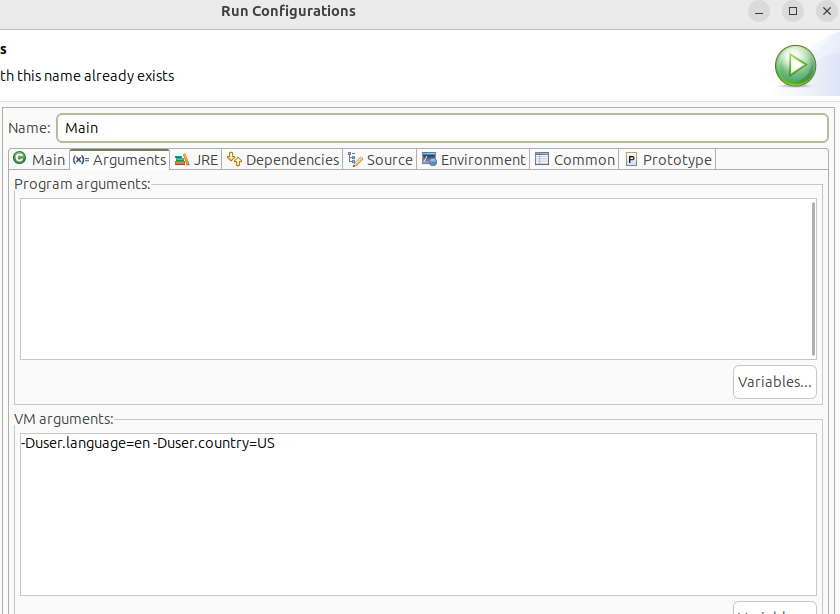
Cualquiera que sea la opción que uses, en programas profesionales en los que se realicen cálculos científicos con números decimales, es necesario tomar las precauciones necesarias para que el programa se ejecute de manera correcta en cualquier entorno de ejecución.
Santiago Higuera, 5 de marzo de 2026