Al compilar ficheros .java, el compilador javac asume que los ficheros tienen una codificación por defecto. En los sistemas Linux o Mac, javac asume que los ficheros están codificados en UTF-8. En Windows, las versiones posteriores a Java 17 también asumen que los ficheros fuente están codificados en UTF-8, pero hasta la versión Java 17 inclusive, javac supone que los ficheros utilizan la codificación de Windows. En España, la codificación que utiliza Windows suele ser Windows-1252.
Esto es así, independientemente de la página de códigos que tengamos activa en el terminal.
Podemos indicar al compilador que utilice una codificación específica para los ficheros fuente .java, utilizando el parámetro -encoding:
javac -encoding UTF-8 *.javaVamos a ver un ejemplo completo utilizando una variante de programa Hola Mundo, que utiliza caracteres especiales del español y servirá para entender el problema.
Vamos a compilar y ejecutar la siguiente clase Java:
public class Hola {
public static void main(String[] args) {
System.out.println("¡Hola, ¿qué tal?, ¡Vaya año llevamos!");
}
}Vamos a utilizar, en primer lugar, la siguiente configuración: Windows 10, Windows Terminal con la página de códigos activa en UTF-8, compilación y ejecución con Java 17 y ficheros .java codificados en UTF-8. La salida obtenida es la de la siguiente figura:
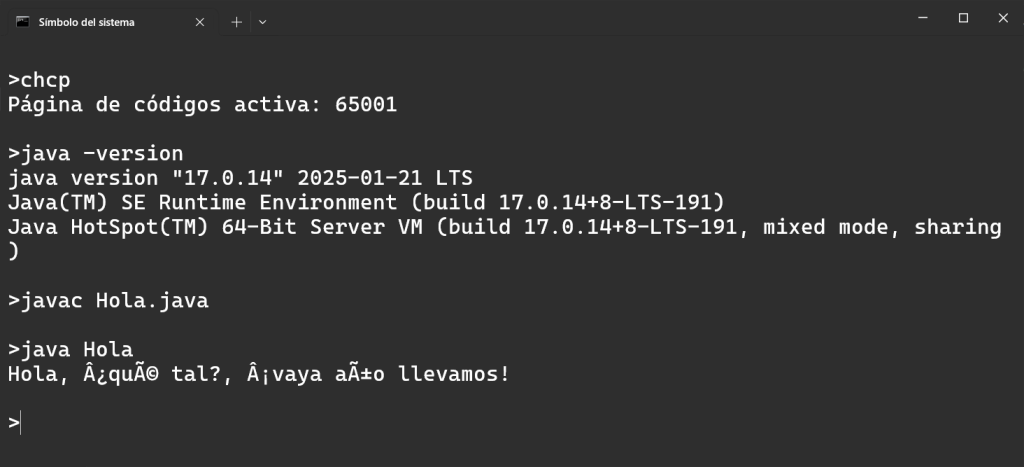
Se puede ver que no se reconocen los caracteres especiales del español. Lo que está pasando es que javac 17 asume que los ficheros fuente están codificados en Windows-1252. Y este comportamiento es independiente de la codificación que tengamos activa en el terminal.
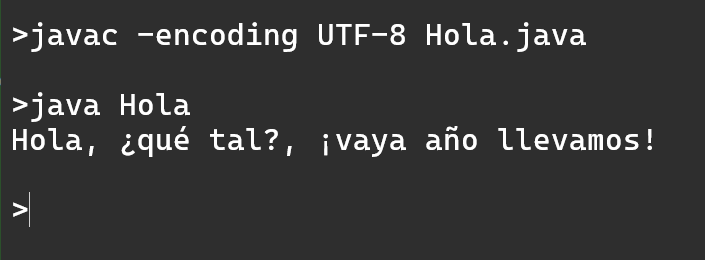
Si compilamos con javac 17, utilizando el parámetro -encoding UTF-8, el fichero fuente se interpreta de manera adecuada:
Java proporciona un comando para poder ver el valor de las diferentes variables que usa:
java -XshowSettings:properties -versionLa salida del comando anterior, en la configuración indicada, fue la siguiente:
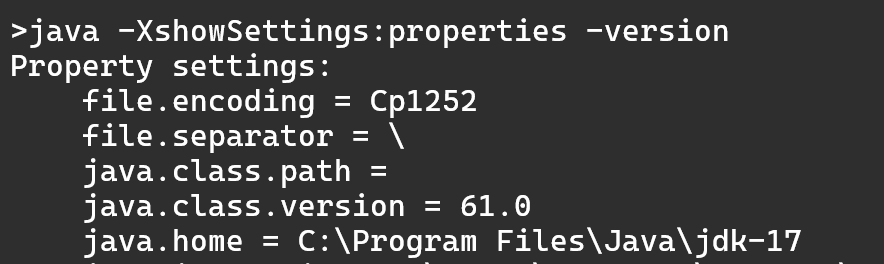
Se puede observar que Java asume que los ficheros están codificados en Windows-1252.
Ahora vamos a utilizar la versión 21 de Java. En el terminal de Windows, vamos a dejar activa la página de código 850 y compilar y ejecutar el mismo programa. La salida es la siguiente:
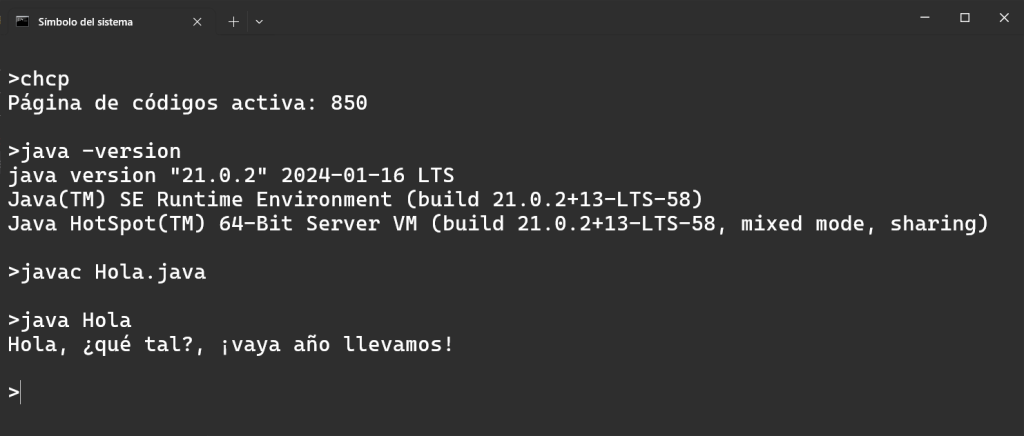
Observa que ahora la interpretación de los caracteres especiales del español es correcta. Una vez más, independientemente de la codificación activa del terminal, que en este caso no era UTF-8.
Si consultamos las opciones que está utilizando Java 21:
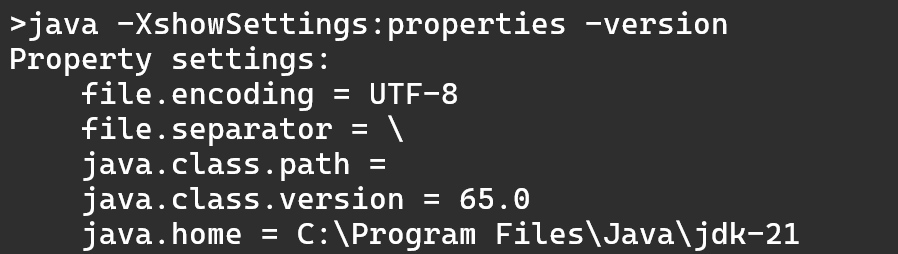
Vemos que ahora Java 21 asume que los ficheros fuente están codificados en UTF-8.
Podemos hacer una última prueba: compilar con Java 21, pero diciéndole al compilador que el fichero Hola.java está codificado en Windows-1252:
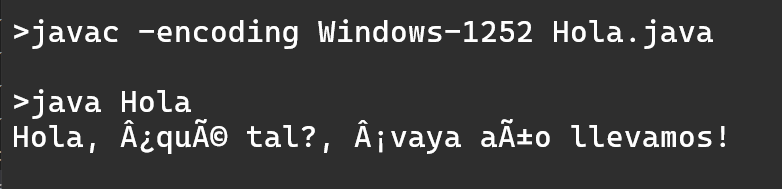
Observa que la salida es la misma que obteníamos con Java 17, cuando interpretaba mal la codificación del fichero fuente.
Por tanto, al compilar ficheros fuente codificados en UTF-8, si utilizamos la versión Java 17 o una inferior, tendremos que utilizar el parámetro -encoding UTF-8 para obtener resultados correctos. Si usamos una versión de Java superior a la 17, ya se presupone que los ficheros fuente están codificados en UTF-8 y no será necesario utilizar el parámetro -encoding.
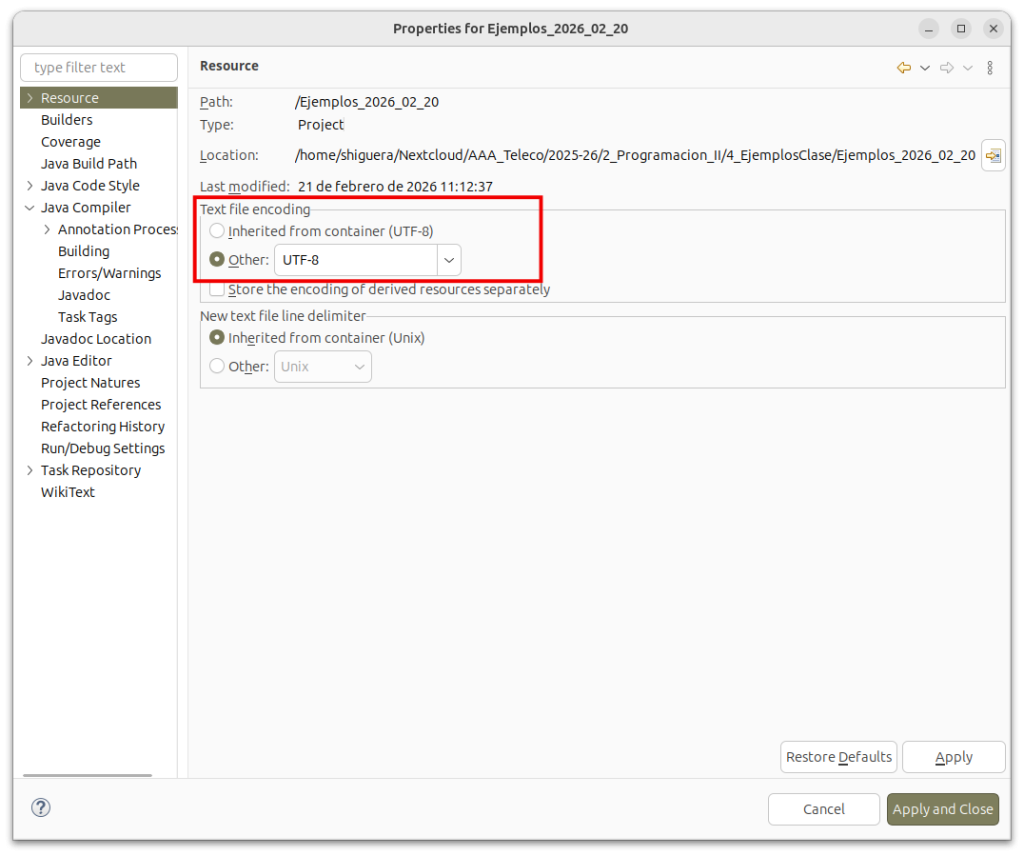
¿Y si estamos trabajando en Eclipse? Bueno, Eclipse proporciona una opción para indicar la codificación de los ficheros fuente y luego se encarga de pasarla al compilador o al entorno de ejecución. La opción la podemos configurar en: “Propiedades del proyecto -> Resource -> Text file encoding“, como se ve en la siguiente figura:
Santiago Higuera, 21 febrero 2026