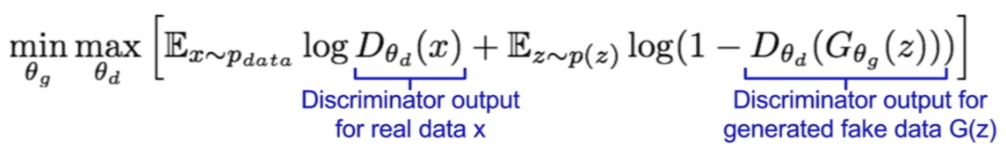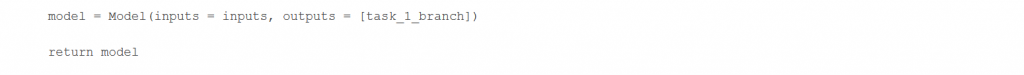En el campo del procesamiento avanzado de señales y datos, una de las tecnologías más innovadoras y prometedoras que ha surgido en los últimos años son las Redes Adversarias Generativas, comúnmente conocidas como GANs. Estas redes neuronales han revolucionado la manera en que generamos y procesamos información, abriendo un abanico de posibilidades en campos como la visión por computadora, la generación de contenido creativo y la simulación de datos realistas.
La generación de imágenes realistas de rostros humanos ha sido durante mucho tiempo un desafío en el campo del aprendizaje automático. Sin embargo, gracias a los avances en las GANs, ha surgido una técnica revolucionaria que ha permitido la creación de imágenes faciales sorprendentemente realistas a partir de datos aleatorios. En esta entrada de blog, exploraremos el enfoque específico de la generación de caras mediante GANs, examinando los avances más destacados, las técnicas utilizadas y los desafíos pendientes. Nos centraremos en aspectos clave, como el uso de arquitecturas específicas como StyleGAN, la mejora de la calidad de las imágenes generadas y la manipulación de atributos faciales.
Estado del arte
Antes de sumergirnos en el funcionamiento y las aplicaciones de las GANs, es importante realizar una breve revisión del estado del arte en este campo. Desde su introducción por Ian Goodfellow en 2014, las GANs han captado rápidamente la atención de la comunidad científica y tecnológica. Diversos avances han permitido mejorar la estabilidad y la calidad de las generaciones, así como la capacidad de aprender y representar distribuciones complejas de datos. Estos avances han dado lugar a aplicaciones sorprendentes en áreas como la síntesis de imágenes, el procesamiento de voz y el diseño de fármacos, entre otros. [1]
Una arquitectura que ha destacado es StyleGAN, que permite el control y la manipulación fina de los atributos faciales en las imágenes generadas. Además, la incorporación de técnicas como la normalización por lotes estilizada (Style-based Batch Normalization) y el uso de redes generadoras y discriminadoras de múltiples escalas ha mejorado aún más la calidad y la diversidad de las imágenes generadas. [2]
Desarrollo
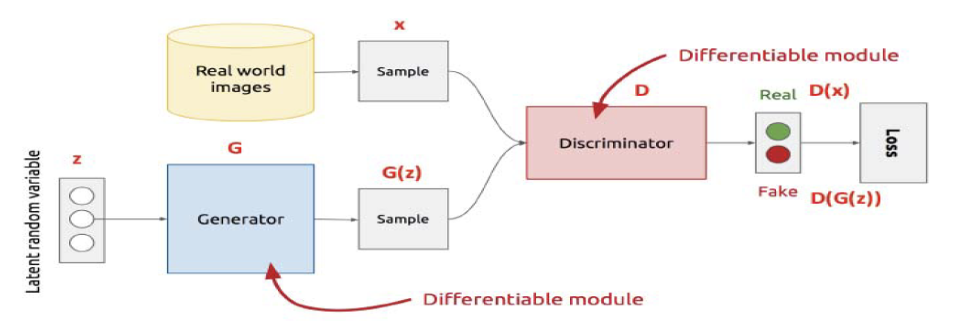
Las GANs se basan en un enfoque novedoso que involucra la interacción entre dos redes neuronales: el generador y el discriminador. El generador tiene como objetivo crear muestras sintéticas que se asemejen a las muestras reales, mientras que el discriminador busca distinguir entre las muestras generadas y las reales. Ambas redes se entrenan de manera simultánea, en un proceso de competencia adversarial, donde el generador busca engañar al discriminador y, este último, trata de mejorar su capacidad de discriminación.
Esquema de una GAN básica [12]
En el proceso de generación de caras mediante GANs, el generador mapea un espacio latente de datos aleatorios a imágenes de caras realistas. El discriminador, por su parte, se entrena para distinguir entre imágenes generadas y reales.
El enfoque de StyleGAN ha permitido avances notables en la generación de caras realistas. Al introducir una descomposición de estilo en el generador, se puede controlar de manera más precisa el aspecto de las imágenes generadas, como la edad, el género, la expresión facial y otros atributos específicos. Además, la incorporación de técnicas de normalización por lotes estilizada y la generación en múltiples escalas ha llevado a una mejora significativa en la calidad visual y la diversidad de las imágenes generadas.
Materiales
El uso de derivaciones matemáticas es fundamental para comprender el funcionamiento de las GANs y optimizar su entrenamiento. La minimización de una función de pérdida, como la divergencia de Kullback-Leibler o la pérdida de Wasserstein, permite establecer una dinámica de aprendizaje entre el generador y el discriminador. Estos conceptos matemáticos fundamentales se ven reflejados en el código de implementación de las GANs, que consta de la definición de las arquitecturas de las redes, la elección de la función de pérdida y la configuración de los hiperparámetros.
La generación de imágenes realistas se logra mediante la minimización de la función de pérdida adversarial. La función objetivo se define como:
Donde D(x) es la estimación del discriminador de la probabilidad de que la instancia de datos reales x sea real, Ex es el valor esperado sobre todas las instancias de datos reales, G(z)es la salida del generador cuando se da ruido z, D(G(z)) es la estimación del discriminador de la probabilidad de que una instancia falsa sea real, Ezes el valor esperado sobre todas las entradas aleatorias al generador (en efecto, el valor esperado sobre todas las instancias falsas generadas G(z)). pdata es la distribución real de los datos y p(z)es la distribución de ruido latente. [11]
El generador intenta maximizar esta función de pérdida mientras que el discriminador intenta minimizarla, creando la competencia adversarial.
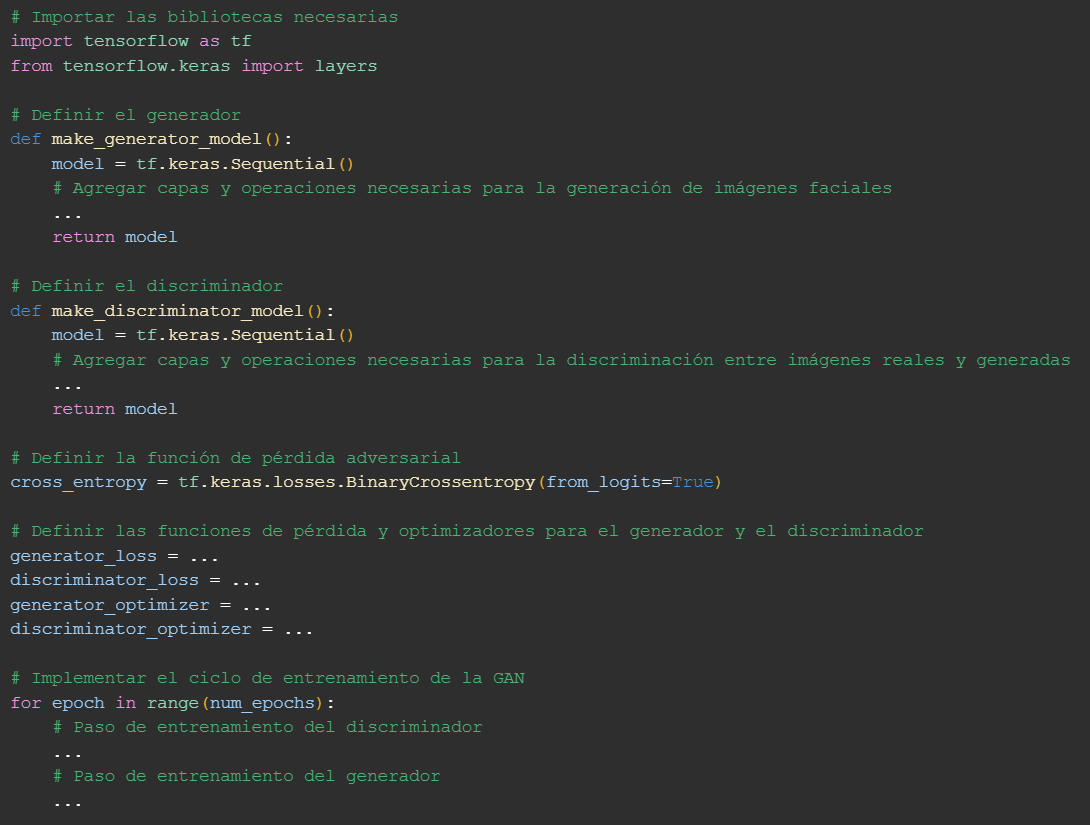
A continuación, se presenta un ejemplo de estructura de una implementación básica de una GAN para la generación de caras utilizando la biblioteca de Python TensorFlow:
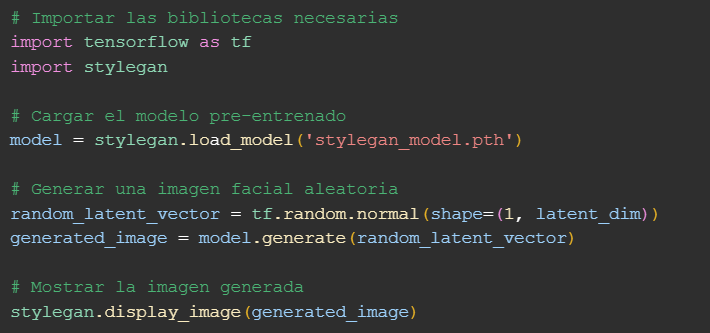
Y, usando la arquitectura StyleGAN:
Discusión de los resultados
La potencia de las GANs se hace evidente al observar los resultados obtenidos en diversos experimentos. Mediante la aplicación de GANs, se ha logrado generar imágenes hiperrealistas, imitar el estilo de artistas famosos, completar imágenes dañadas o faltantes, e incluso simular la evolución de enfermedades en datos médicos.
Se han logrado imágenes faciales altamente realistas, con detalles finos y una calidad visual sorprendente. Además, la capacidad de controlar los atributos faciales ha permitido la creación de imágenes personalizadas y la manipulación de características específicas.
Sin embargo, a pesar de estos avances, aún existen desafíos importantes que deben abordarse en la generación de caras mediante GANs. Uno de estos es lograr una mayor estabilidad en el entrenamiento de los modelos. A veces, las GANs pueden ser difíciles de entrenar y pueden sufrir de problemas como el colapso del modo, donde el generador produce imágenes similares y de baja diversidad. También es fundamental mejorar la interpretabilidad de los modelos y garantizar la ética en la generación de caras, evitando posibles sesgos y discriminación involuntaria. [6]
A continuación, se muestran algunos ejemplos de imágenes generadas utilizando una GAN entrenada para la generación de caras. Estas imágenes demuestran la capacidad de las GANs para producir resultados visualmente atractivos. Además, se pueden proporcionar métricas de evaluación, como el puntaje de Inception (Inception Score), para cuantificar la calidad y la diversidad de las imágenes generadas.
Visualización de la salida del programa de SAYAK en Kaggle [11]
Conclusiones
Las Redes Adversarias Generativas han revolucionado el procesamiento de señales y datos, ofreciendo una poderosa herramienta para la generación y simulación de información compleja. Su capacidad de aprender y representar distribuciones de datos complejas ha permitido avances significativos en campos como la visión por computadora, la creatividad computacional y la generación de contenido realista.
La generación de caras mediante GANs ha alcanzado niveles sorprendentes de realismo y control de atributos faciales. La arquitectura StyleGAN ha sido un avance significativo en este campo, permitiendo una generación más precisa y diversa. Sin embargo, aún existen desafíos a superar, como la estabilidad del entrenamiento y la ética en la generación de imágenes faciales. La investigación continua se centra en mejorar estos aspectos y abrir nuevas posibilidades en la generación de caras.
Los avances en esta área de investigación continúan abriendo nuevas posibilidades en el campo del procesamiento avanzado de señales y datos. A medida que se superan los desafíos restantes, se espera que las GANs sigan evolucionando y proporcionando resultados aún más impresionantes.
Referencias
[1] Goodfellow, I., Pouget-Abadie, J., Mirza, M., Xu, B., Warde-Farley, D., Ozair, S., … & Bengio, Y. (2014). Generative adversarial nets. In Advances in neural information processing systems (pp. 2672-2680). [Enlace]
[2] Karras, T., Laine, S., & Aila, T. (2019). A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 4401-4410). [Enlace]
[3] Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2020). Training generative adversarial networks with limited data. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition (pp. 5937-5947). [Enlace]
[4] Zhao, S., Liu, Z., & Shen, X. (2021). Learning to Generate Faces: A Survey. arXiv preprint arXiv:2103.01763. [Enlace]
[5] Brock, A., Donahue, J., & Simonyan, K. (2018). Large scale GAN training for high fidelity natural image synthesis. arXiv preprint arXiv:1809.11096. [Enlace]
[6] Brock, A., Donahue, J., & Simonyan, K. (2019). Large scale GAN training for high fidelity natural image synthesis. In International Conference on Learning Representations. [Enlace]
[7] Arjovsky, M., & Bottou, L. (2017). Towards principled methods for training generative adversarial networks. arXiv preprint arXiv:1701.04862. [Enlace]
[8] Zhang, H., Xu, T., Li, H., Zhang, S., Wang, X., Huang, X., & Metaxas, D. N. (2018). Self-attention generative adversarial networks. In International Conference on Machine Learning (pp. 7354-7363). [Enlace]
[9] Huang, X., Li, Y., Poursaeed, O., Hopcroft, J., & Belongie, S. (2017). Stacked generative adversarial networks. In IEEE Conference on Computer Vision and Pattern Recognition (pp. 6487-6495). [Enlace]
[10] Arjovsky, M., Chintala, S., & Bottou, L. (2017). Wasserstein generative adversarial networks. In International conference on machine learning (pp. 214-223). [Enlace]
El aprendizaje automático es una rama de la Inteligencia Artificial que permite que un sistema aprenda y mejore de forma autónoma, mediante técnicas como las redes neuronales y el aprendizaje profundo, sin tener que ser programado explícitamente. Con el desarrollo de nuevas técnicas dentro de este campo, van saliendo nuevos problemas que buscan desafiar la forma en la que las máquinas aprenden los algoritmos, no solo para solucionar dichos problemas, sino para mejorar la eficiencia y el rendimiento con el que lo hacemos. Uno de esos nuevos problemas, el cual ganó bastante popularidad en las redes a mediados de 2016, es el famoso problema ‘Muffin VS Chihuahua’. Se presenta una serie de imágenes de perros (más concretamente de Chihuahuas) y de magdalenas de arándanos, y el objetivo es que la máquina sea capaz de identificar qué imágenes son de perros y cuáles de muffins. Este caso no es más que un ejemplo de un problema mayor, que lleva varios años siendo estudiado y abordado mediante varios métodos y técnicas dentro del área del aprendizaje automático: que una máquina sea capaz de identificar y clasificar imágenes correctamente.
Collage de fotos de muffins y chihuahuas [1]
En este blog, abordaremos el problema del Muffin Chihuahua haciendo uso de tres grandes campos dentro del aprendizaje automático, que solaparemos entre ellos para cumplir el objetivo de identificar si la imagen es de un perro o de una muffin. Estos son los campos del aprendizaje profundo, el aprendizaje por transferencia, y el aprendizaje multi-tarea.
1. Estado del arte
Para enfrentarnos a este problema, empezamos tratando de responder a la siguiente pregunta: ¿Cuáles son las técnicas disponibles en el campo del aprendizaje automático?
Después de explorar las diferentes alternativas existentes dentro del aprendizaje profundo, decidimos centrarnos en en el aprendizaje por transferencia y aprendizaje multi-tarea.
Aprendizaje por transferencia[2]
El aprendizaje por transferencia hace referencia a aquel aprendizaje que hace uso de parte del conocimiento adquirido por un algoritmo para otro. En vez de empezar completamente desde cero, aprovechas las arquitecturas y los pesos de tareas y dominios parecidos para tu propia tarea y dominio.
Aprendizaje multi-tarea [3]
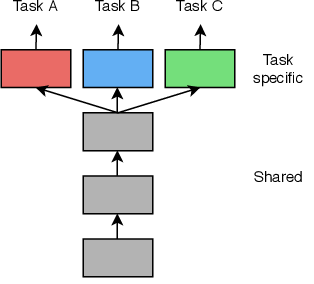
El aprendizaje multitarea consiste en entrenar un modelo para realizar múltiples tareas relacionadas simultáneamente. A diferencia del enfoque tradicional de entrenar modelos separados para cada tarea, el aprendizaje multitarea busca aprovechar las similitudes entre las tareas para mejorar el rendimiento global. Las tareas comparten un conjunto común de características aprendidas por el modelo. Estas actúan como un vínculo entre las diferentes tareas, permitiendo que el conocimiento adquirido en una tarea influya en el rendimiento de las demás tareas[4]. De esta manera, podemos evitar los principales problemas que nos encontramos a la hora de crear nuevas redes neuronales: el elevado tiempo que requiere entrenarla y la baja cantidad de datos que suele haber para el entrenamiento de una nueva tarea. Dentro de este campo, hay un espectro de posibles formas de implementar dicho aprendizaje[5]. En los extremos de dicho espectro se encuentran el hard parameter sharing y el soft parameter sharing. [6]
El “hard parameter sharing” es una técnica en el campo del aprendizaje automático que implica compartir los mismos pesos y conexiones en diferentes partes de una red neuronal. A diferencia de tener parámetros separados para cada tarea o módulo, se comparten los mismos parámetros entre ellos. Esta estrategia resulta especialmente útil cuando se trabaja con múltiples tareas relacionadas que comparten características comunes. Al compartir los parámetros, se aprovecha el conocimiento aprendido en una tarea para mejorar el rendimiento en otra tarea, logrando así una mejor utilización de los recursos computacionales y una mayor generalización del modelo.
El hard parameter sharing tiene la ventaja de poder aprender representaciones compartidas, es decir, la red neuronal puede capturar características útiles que son relevantes para todas las tareas. Esto resulta especialmente beneficioso cuando las tareas están estrechamente relacionadas y comparten patrones subyacentes. Al compartir los parámetros, la red puede aprender estas características de manera más efectiva. No obstante, existen limitaciones en esta técnica. Por ejemplo, si las tareas son muy diferentes entre sí y requieren representaciones muy distintas, el hard parameter sharing puede no ser la opción más adecuada. Además, si una tarea dominante está presente y domina a los demás módulos, el rendimiento en las tareas secundarias puede verse afectado negativamente.
La estructura que suele presentar es la siguiente:
Diagrama de la arquitectura para hard parameter sharing [7]
Las primeras capas de la red son compartidas entre todas las tareas. Por ello, los parámetros y los pesos obtenidos en dichas capas son iguales para todas las tareas y no hacen distinción. Es en las últimas capas donde nos centramos en extraer las características para cada tarea en concreto, obteniendo cada una de ellas sus propios pesos y resultados.
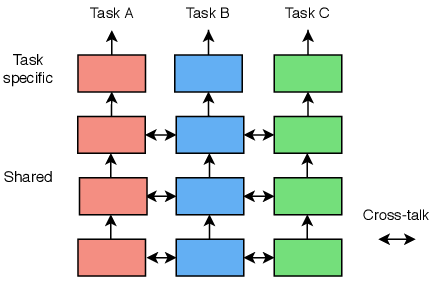
Por otro lado, tenemos el “soft parameter sharing”, que se podría considerar el otro extremo del espectro del aprendizaje multitarea. En vez de tener una sola estructura, una sola red para todas las tareas, tendremos una red individual para cada una de ellas. A pesar de ello, todavía buscamos que los parámetros de todas las redes se parezcan un poco. En el caso anterior, los parámetros se compartían directamente, pero con esta técnica, utilizaremos mecanismos de penalización para conseguir que los parámetros correspondientes se parezcan más entre sí. De esta manera, conseguimos una mayor adaptabilidad y capacidad de fine-tuning, ya que el algoritmo se beneficia de la transferencia de conocimiento mientras mantiene la capacidad de aprender características distintas en cada parte específica de la tarea.
El soft parameter sharing[8] es una técnica muy amplia y diversa en su propio campo, por lo que las formas de implementarla son múltiples. Al igual que en el hard parameter sharing, es el desarrollador el que toma decisiones de diseño, como que se comparta el conocimiento entre capas. A pesar de ello, podemos definir una estructura general, la cual es la siguiente:
Diagrama de la arquitectura para soft parameter sharing [7]
En esta podemos ver que se puede compartir el conocimiento adquirido de las primeras capas de cada red y dejar las últimas para que sean específicas para cada tarea.
2. Desarrollo
Una vez realizada la investigación para identificar la situación actual y las diferentes técnicas que pueden ser usadas para nuestro problema, podemos comenzar a desarrollar nuestro trabajo. Para ello, necesitaremos poner en práctica la información obtenida en el apartado anterior y encontrar el material necesario. Más concretamente, podemos dividir el desarrollo de esta trabajo en dos partes:
¿Cuáles son los recursos disponibles sobre este problema?
Implementación de las técnicas sobre el problema.
2.1 ¿Cuáles son los recursos disponibles sobre este problema?
Empezamos haciendo una búsqueda sobre los recursos disponibles sobre el problema del Muffin Chihuahua[1]. Dado que lo que pretendíamos era entrenar un algoritmo para aprender a diferenciarlos, necesitábamos tener los suficientes datos para dicho entrenamiento. Por ello, empezamos viendo qué datos había disponibles para dicha labor. Al ser un problema conocido dentro del campo del aprendizaje automático, el número de artículos sobre el mismo es abundante. Incluso hay varios apartados en la comunidad de Kaggle[8] orientados a la resolución de este problema. Dichos apartados fueron un punto de partida para la investigación para este blog[9]. En especial nos interesaron aquellos resultados que hacían uso de redes neuronales, ya que nuestro primer objetivo era aplicar aprendizaje profundo para resolver el problema. Encontramos así una base de datos abierta en el propio Kaggle con 5917 imágenes de chihuahuas y muffins[10]. Esta será el material utilizado para el algoritmo.
2.2 Implementación de las técnicas sobre el problema.
Una vez definidos los recursos del problema y las técnicas que queremos aplicar para tratar de resolver el mismo, combinamos el conocimiento adquirido para aplicarlo a la práctica. Lo que decidimos hacer fue hacer uso de las redes ya entrenadas en los códigos del Kaggle[9] para aplicar aprendizaje por transferencia. Sobre los pesos congelados de esa red, aplicaríamos después los dos extremos del aprendizaje multitarea. En el caso de hard parameter sharing, las capas compartidas entre tareas serían aquellas congeladas del algoritmos entrenado previamente y las capas específicas para cada tarea serían entrenadas por separado. En el caso del soft parameter sharing, en vez de enfocarlo con conocimiento compartido entre las distintas redes, decidimos implementarlo congelando las primeras capas con los pesos del algoritmo entrenado y dejar el resto de capas entrenarse específicamente para la tarea de cada una de las redes, haciendo así un modelo híbrido más asequible teniendo en cuenta que no contamos con recursos computacionales muy potentes.
Para implementar esto, hicimos uso de un código base desarrollado en Kaggle[10.1] que conseguía una exactitud del 90% en la clasificación. Dicho código implementaba una red convolucional para resolver el problema. Además, la forma en la que cargamos y evaluamos los datos se basó en dicho código también. El código implementa pytorch en vez de keras, pero al estar más familiarizados con la segunda, decidimos adaptarlo a dicha librería.
Debido a que muchas de las decisiones tomadas para el trabajo se basan en este código, explicaremos a continuación el contenido del mismo. Muchos cambios han sido realizados sobre este código para adaptarlo, así que mencionaremos en detalle solamente aquellas partes del código que utilizamos nosotras a la hora de desarrollar el propio. El notebook está dividido en 5 partes.
Comienza con una breve introducción en la que define los conjuntos de train y de test. Nosotras realizamos esto mismo de la misma forma. Primero define la función build_metadata(), la cual tiene como objetivo coger una ruta donde están los datos y devolver un dataframe donde tenemos una columna con los datos (en este caso las imágenes) y otra columna con las etiquetas de estos.
Una vez tiene la función, como el Kaggle proporciona el dataset de imágenes tanto de entrenamiento como de test, llama a esta función para ambos, definiendo así los dataframe de train y test.
Termina la introducción cambiando las etiquetas. Las etiquetas son strings que marcan ‘muffin’ o ‘chihuahua’. Lo que hace es cambiarlo a valores numéricos para poder trabajar mejor con ellas. Quedan así los mismos dataframes pero la columna de ‘label’ es una colección de 0 (muffin) y 1 (chihuahua).
Una vez definido esto pasa a la siguiente parte del notebook, que está dedicada a definir clases a las que se llamarán para conseguir el dataset de imágenes en el formato deseado y conseguir dataloaders. En nuestro caso, esto lo hacemos de manera distinta por lo que el código desarrollado en el notebook en esta sección no es de especial interés de cara a entender el por qué del código desarrollado por nosotras. La siguiente sección, sin embargo, si que vuelve a ser de interés, ya que define el modelo. Como dicho anteriormente este modelo será la base de nuestros modelos de multitask, entrenaremos este y luego congelaremos las capas para quedarnos con parte de su arquitectura. A pesar de que está definido en PyTorch y nosotras lo adaptamos a keras, la arquitectura es la misma.
Define la red como una serie de convoluciones combinadas con capas de MaxPooling y normalización del Batch. Además, dentro de la clase define una serie de funciones que marcan el tamaño de los pasos de train, test y validación. Eso no lo aplicaremos en nuestro código, por lo que no entraremos en detalle. A partir de aquí además, lo restante del código está completamente cambiado y muchas partes no son de utilidad para nosotras.
El desarrollo que se siguió para obtener el código y los resultados que se verán en detalle en la siguiente parte partieron de este código. Teniendo los datos cargados y entrenados, guardamos los pesos de la red para poder hacer el aprendizaje por tranferencia con dichos pesos aprendidos. Una vez hecho eso, y una vez adaptado el código, tomamos las dos rutas explicadas anteriormente. En el caso del hard parameter sharing, congelamos todas las capas salvo las 7 últimas, las cuales serían las capas task specific. En el caso del soft parameter sharing, decidimos congelar incluso menos capas y jugar con redes más distintas entre sí, por lo que solamente congelamos las 5 primeras capas del modelo entrenado y las demas las adaptamos a los que buscábamos. Una vez hecho esto, sacamos varias métricas sobre los modelos para comparar los resultados no solo entre el hard y el soft parameter sharing, sino también con la red original, para ver si aplicar estas técnicas de transfer learning y multitask learning verdaderamente suponen una mejora sobre la red solamente.
Proceso hard
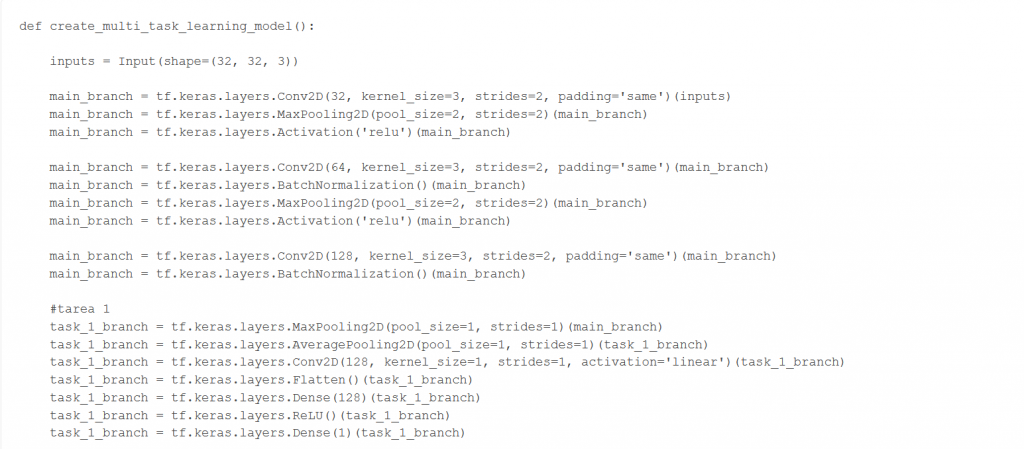
La implementación de la teoría al código empieza con la definición de muestro modelo, el cual definimos en la función create_multi_task_learning_model() de nuestro código.
Para aplicar Hard parameter sharing en multi-task learning (MTL), partimos de un modelo base (el definido), al que nos referiremos como main_branch. En este, tenemos capas convolucionales con los parámetros que compartirán nuestras tareas. Este será el modelo que entrenamos con el objetivo de obtener los pesos y congelarlos sobre las capas de nuestra arquitectura de Hard Parameter Sharing.
Cargamos los datos de entrenamiento y de validación, definimos un modelo, compilamos, entrenamos y evaluamos:
Los pesos del modelo los guardamos en un archivo para poder cargarlos en la futura arquitectura.
Ahora, podemos añadir nuevas tareas.
Estas tareas, denotadas como task_1_branch, task_2_branch y task_3_branch, comparten la estructura inicial, pero tienen sus propias capas finales las cuales se encargarán de obtener diferentes características y las cuales tendrán sus propios parámetros (a los que se sumarán los parámetros de la red base).
Tarea 1: Decidimos mantener la primera tarea con el modelo original, para incluirlo con todas las capas originales en la nueva arquitectura.
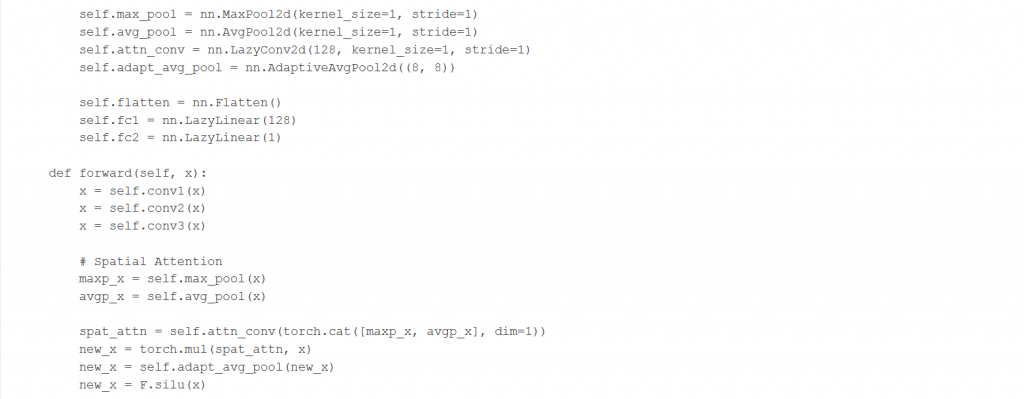
Tarea 2: Capa de max pooling y average pooling para reducir la dimensionalidad. Luego, aplicamos una capa de convolución lineal y una capa Flatten para generar un vector a la salida. Aplicamos después una capa Dense con 128 neuronas y una función de activación ReLU. Tras eso, añadimos la capa de Dropout de 0.2, que lo hacemos para quedarnos con menos neuronas activadas y de esta forma evitar sobre ajuste. Al final, aplicamos una capa Dense de 64 neuronas con función de activación ReLU y otra capa Dense con 1 neurona que produce la salida de nuestro problema.
Tarea 3: Capa de max pooling y average pooling para reducir la dimensionalidad. Después, añadimos una capa de convolución y capa Flatten. Por último, nos encontramos con una capa Dense con 128 neuronas, una capa de Dropout para quedarnos con menos neuronas activadas y dos capas Dense con 64 y 1 neurona, respectivamente.
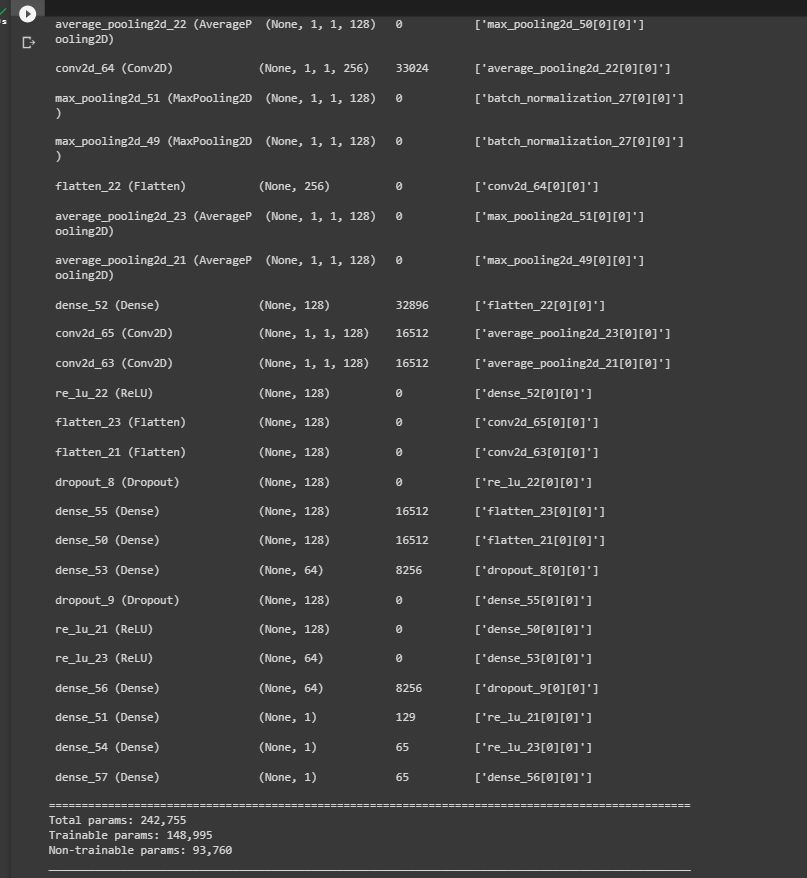
En cuanto a los parámetros, la capa principal (main_branch) está formada por 93,248 parámetros y las tareas 1, 2, y 3 están formadas por 332,025, 49.537 y 32.025 parámetros respectivamente.
Creamos un nuevo modelo donde utilizaremos el mismo main_branch del que cargaremos los pesos guardados y le añadiremos 3 nuevas tareas, que detectarán características distintas. Cargamos los pesos del modelo base (las 9 primeras capas).
Congelamos las capas del modelo base para que se actualicen los pesos de nuestras tareas con los obtenidos tras el entrenamiento, pero que estos no se cambien al volver a ejecutar la arquitectura (no se entrenen).
Entrenamos el modelo:
Como queremos comparar el rendimiento de ambos casos, con una sola tarea (o modelo original) y con 3 tareas, hemos cogido las mismas métricas para analizarlas: binary_crossentropy como función de pérdida y accuracy como métrica. Además, aplicamos el mismo optimizador ‘Adam’.
Evaluamos resultados:
Resultados y discusión de resultados:
Al haber usado un modelo base cuyo objetivo era clasificar entre un muffin y un chihuaha y nuestras tareas estaban altamente relacionadas, esperabamos un rendimiento bueno al aplicar hard parameter sharing .
Observando los resultados, vemos que en general dan resultados similares, salvo por la tarea 1 que da un accuracy menor que en el modelo original. Esto puede ser debido a que esa tarea fue usada junto al modelo base para sacar los pesos que guardaríamos y ahora al entrenarlo con más tareas, el accuracy se ve afectado.
La tarea 1 parece ser la más desafiante, ya que tiene la pérdida más alta. La tarea 2 obtiene bastantes buenos resultados, teniendo en cuenta que tiene menos parámetros en comparación con las otras dos tareas con una pérdida de 0.8081 y una precisión de 0.6993. Por último, la tarea 3 da mejores resultados que en el entrenamiento y test del modelo base (que había obtenido un accuracy de 0.71) con una pérdida de 0.5851 y una precisión de 0.7297
Estos resultados dependen de cómo se definan nuestras tareas y las capas que la componen. En general, podemos concluir que el modelo tiene un desempeño promedio en nuestras tres tareas altamente relacionadas. Nos hemos ahorrado bastante tiempo de cómputo y de memoria al no tener que entrenar el modelo de cero teniendo los pesos de main_branch guardados. Además, si queremos añadir tareas o utilizar tareas distintas podemos volver a utilizar estos pesos e incluso usar los pesos de alguna tarea y hacer fine-tunning dependiendo de nuestros objetivos
Proceso soft
Hemos tenido algunas dificultades a la hora de implementar este proceso, ya que la documentación y los ejemplos son escasos. Además, se requiere un tiempo y recursos computacionales elevados, algo que no tenemos disponible. Por estos motivos, no hemos logrado obtener resultados para este apartado; sin embargo, describiremos el proceso seguido y el problema principal que nos ha dificultado el desarrollo.
Para ahorrar recursos computacionales, no creamos un modelo soft puro, sino que se definió un híbrido. Comenzaremos de la misma manera que en el hard, con la función create_multi_task_learning_model() para definir nuestro modelo original, cargar los datos de entrenamiento y validación, compilar, entrenar y evaluar.
Una vez hecho esto, crearemos tres nuevos modelos basados en el modelo definido anteriormente, cogiendo las 5 primeras capas y congelándolas (evitando que se entrenen). Para ello, usaremos las siguientes líneas de código:
Repetiremos este proceso para las tres redes, que realizarán una tarea distinta cada una. A continuación, crearemos las capas específicas para cada una de ellas. Serán más abundantes que en el caso anterior, ya que queremos acercarnos lo máximo posible a una arquitectura soft pura.
La tarea 1 estará basada en una red VGG16[15], con una capa lineal, una ReLU, un dropout, otra lineal y por último una función de activación sigmoid. Para hacer las capas lineales en keras, hemos usado una Dense pasando como parámetro 256 píxeles.
La red de la tarea 2 está inspirada por una red EfficientNet [14], que tendrá una normalización, una capa ReLU, un dropout y una capa dense, y repetirá este proceso dos veces.
Por último, en la tarea 3 expandiremos las capas convolucionales[16] que se realizaban en la red original.
Una vez hecho esto, crearemos los nuevos modelos añadiendo a la main branch las tareas nuevas y evaluamos los resultados:
Es aquí donde nos hemos encontrado el siguiente problema:
ValueError: `logits` and `labels` must have the same shape, received ((None, 4, 4, 1) vs (None,)
Nos indica que hay una discrepancia entre las formas de los logits (los valores de salida de la red neuronal antes de aplicarles una función de activación) y las etiquetas en la función de pérdida 'binary_crossentropy' (hemos probado con varias funciones de pérdida y el error persistía). Más concretamente, específica que se recibieron logits con forma (None, 4, 4, 1) y etiquetas con forma (None,). Revisamos la forma de crear las variables train_generator, val_generator y test_generator pero no detectamos ningún error. También probamos a cambiar varias secciones del código para modificar los dataframe que se generaban, volvimos a descargar los datos y revisamos el fichero de pesos generado, además de revisar distintos foros[NUM] y páginas de documentación[NUM] para intentar solucionar nuestro problema. Sin embargo, el error persistió.
Discusión de los posibles resultados: Aunque no hemos conseguido obtener resultados, estudiaremos qué significarían los posibles resultados que podríamos obtener:
La arquitectura soft es mejor que la del modelo original En este caso, obtendríamos una arquitectura capaz de clasificar mejor entre fotos de chihuahuas y muffins. Esto demostraría que las tareas están relacionadas, y por tanto compartir parámetros mejora nuestros modelos, haciendo que aprendan representaciones más robustas y generales. Además, conseguiríamos aprovechar los datos de manera más eficiente, algo muy útil cuando se cuenta con con un conjunto de datos muy pequeño o desequilibrado (el número de datos varía mucho entre las clases). Si se diese esta situación, también sería probable que los resultados fuesen mejores a los obtenidos con hard parameter sharing, lo que indicaría que permitir más flexibilidad y capacidad de adaptación en las tareas es beneficioso en este caso. Se da la opción de que las tareas ajusten su propio conjunto de parámetros de manera independiente, por lo que se adapta a sus necesidades específicas y aprende las representaciones especializadas (todo esto manteniendo la compartición de parámetros entre ellas, ya que son tareas relacionadas)
La arquitectura soft es peor que la del modelo original
Podría ocurrir el caso contrario, que los resultado empeorasen frente al modelo original y por tanto frente al hard parameter sharing. Esto podría deberse a varias razones:
Las tareas son muy diferentes entre sí: Si las tareas no tienen características o patrones comunes, la compartición suave de parámetros puede conducir a una interferencia negativa entre las tareas, afectando al aprendizaje de cada una
Se produce un sobreajuste: Si el modelo comparte demasiados parámetros o se ajusta mucho a las características específicas de una tarea, se pueden tener dificultades generalizando nuevas imágenes o tareas, empeorando el resultado en el conjunto de test.
Problemas de convergencia: El soft parameter sharing puede hacer que el modelo sea más complejo y difícil de entrenar, por lo que se corre más riesgo de que el modelo no llegue a converger.
La arquitectura soft y el modelo original obtienen resultados similares
Por último, podría ocurrir que los resultados entre las tres arquitecturas fueran muy similares. Puede ocurrir en dos casos:
La compartición de parámetros no afecta al rendimiento: Si las tareas no son lo suficientemente similares (no comparten características ni patrones, o no tienen dependencias entre ellas) o compartir parámetros no es necesario para obtener un beneficio significativo, estos procesos no tendrán ningún impacto importante en el rendimiento de nuestro modelo.
El modelo original ya tenía un rendimiento óptimo: El modelo original ya está diseñado y ajustado de manera óptima, por lo que compartir parámetros no ofrece mejoras adicionales.
3. Conclusión del trabajo
En resumen, en este blog hemos explorado dos de los enfoques más comunes en el multitask learning: Hard y Soft parameter sharing. Hemos visto en detalle su funcionamiento y posteriormente lo hemos aplicado a un problema concreto: diferenciar entre fotos de chihuahuas y muffins. Para ello, hemos investigado diferentes arquitecturas de redes neuronales, centrándonos en las redes convolucionales debido a su eficacia en el procesamiento y clasificación de imágenes. También hemos revisado diversos recursos y artículos relacionados con el problema ‘Muffin vs Chihuahua’ para obtener información útil y orientación en la implementación de soluciones. En la implementación del problema, hemos utilizado un conjunto de datos disponible en Kaggle que consta de varias imágenes de chihuahuas y muffins. Hemos adaptado un código base desarrollado en Kaggle, que utiliza redes convolucionales en PyTorch, a la biblioteca Keras para aplicar las técnicas de aprendizaje por transferencia y aprendizaje multi-tarea. También hemos realizado modificaciones en el código para congelar y entrenar diferentes partes de las redes según los enfoques de hard parameter sharing y soft parameter sharing.
Gracias a esto, tenemos un conocimiento mucho más extenso de estas dos técnicas y de las librerías pytorch y keras, que conocíamos de manera muy superficial. De esta manera, hemos aprendido nuevos recursos para lidiar con problemas como contar con un dataset demasiado pequeño o desequilibrado, algo que consideramos fundamental a la hora de enfrentarnos a situaciones reales en un futuro.
Iñigo García-Vallaure Martín, Laura Alejandra Noreña Blandon y Eric Antonio Raymond Rodrigues
INTRODUCCIÓN
A través de este blog vamos a observar las distintas utilidades de la inferencia aproximada y de las redes bayesianas. Se tratan de dos aplicaciones fundamentales en el ámbito del aprendizaje automático y en el campo de la inteligencia artificial, apoyándose en métodos probabilísticos y en la toma de decisiones basadas en la incertidumbre.
El objetivo de la inferencia aproximada es estimar la distribución de probabilidad de variables que no son conocidas a través de observaciones, ya que computacionalmente puede resultar costoso. Es útil en problemas donde las relaciones entre variables son difíciles de ajustar de forma exacta.
Por su parte, las redes bayesianas son modelos probabilísticos que relacionan variables mediante grafos acíclicos dirigidos. Los nodos representan las variables, las cuales están relacionadas entre ellas de manera dependiente o independiente. Una vez desarrollado el modelo, en base a nuevas evidencias, podemos obtener la probabilidad a posteriori del conjunto de variables. Las aristas que unen los nodos representan las dependencias probabilísticas entre las variables.
Si combinásemos estas dos aplicaciones, podría ser bastante provechoso en distintos ámbitos, como la robótica, medicina, ingeniería o en la toma de decisiones.
En resumen, la inferencia aproximada y las redes bayesianas con herramientas fundamentales para lidiar con la incertidumbre en problemas complejos de inferencia probabilística, ya que sería efectivo a la hora de resolver problemas del mundo real.
ESTADO DEL ARTE
En los últimos años, los campos de la inferencia aproximada y las redes bayesianas han padecido grandes avances. Ambos se centran en realizar inferencias eficientes y precisas en modelos probabilísticos.
La inferencia aproximada, en vez de calcular la distribución posterior exacta (la cual es computacionalmente costosa), busca encontrar una aproximación cercana a través de métodos más eficientes. Algunos de los mencionados métodos son la inferencia variacional: se plantea la inferencia como un problema de optimización donde se busca encontrar una distribución lo más semejante posible a la distribución posterior real; la aproximación de Monte Carlo: emplea distintos procedimientos que utilizan muestras aleatorias para aproximar la distribución posterior. Algunas de las técnicas manejadas son el muestreo de Gibbs, el muestreo de Importancia o el Muestreo de Aceptación y Rechazo; y la aproximación determinista: se aproxima a la distribución posterior mediante técnicas deterministas como la cuadratura de Gauss o la factorización de momentos.
Por su lado, las redes bayesianas son necesarias para modelar incertidumbre y realizar inferencias basadas en reglas de probabilidad. Han ayudado al desarrollo y progreso de redes bayesianas profundas: gracias a la unión de las redes bayesianas con arquitecturas profundas, como por ejemplo, las redes neuronales, han aparecido redes bayesianas profundas, las cuales permiten modelar incertidumbre en las predicciones y proporcionan una forma más robusta de aprendizaje automático; de la inferencia aproximada en redes bayesianas: la inferencia aproximada es bastante importante en las redes bayesianas, sobre todo cuando el número de variables es muy alto o la estructura del modelo es compleja. Los avances en técnicas de inferencia aproximada han mejorado la eficiencia y la precisión de las inferencias realizadas en redes bayesianas; y del aprendizaje estructural: se han llevado a cabo y desarrollado algoritmos más eficientes para estudiar la estructura de las redes bayesianas a partir de datos observados. Con estos algoritmos, se pueden descubrir automáticamente las relaciones de dependencia entre las variables y construir modelos más precisos.
El problema de inferencia en una red bayesiana es un problema NP- completo en redes grandes. Debido a esto, para resolverlo se han propuesto alternativas exactas y aproximadas, las cuales pueden ser determinísticos o estocásticos. Los algoritmos determinísticos intentan simplificar el problema de alguna manera, como por ejemplo, con la eliminación de nodos (se seleccionan nodos para realizar los cálculos necesarios y se eliminan los demás) o con la eliminación de arcos (donde se eliminan todos aquellos arcos que codifican relaciones detectadas como “débiles”). Los algoritmos estocásticos se basan en realizar determinadas simulaciones a partir de una distribución de probabilidad existente en la red y, así, estimar la probabilidad de interés.
DESARROLLO
Las redes bayesianas son modelos probabilísticos que representan relaciones causales entre variables utilizando grafos dirigidos acíclicos. Estas redes se basan en el teorema de Bayes y son utilizadas para modelar la incertidumbre y realizar inferencias probabilísticas. El desarrollo de una red bayesiana generalmente implica los siguientes pasos:
Identificar las variables relevantes: comienza por identificar las variables que deseas modelar en tu problema. Estas variables pueden ser discretas o continuas y representar diferentes aspectos del sistema que estás estudiando.
Definir la estructura del grafo: una vez que hayas identificado las variables, debes definir la estructura del grafo dirigido acíclico que representará las relaciones causales entre ellas. Esto implica determinar qué variables dependen directamente de otras variables.
Especificar las distribuciones de probabilidad condicional: para cada variable en la red, se deben de especificar su distribución de probabilidad condicional (DPC) dado el estado de sus variables padre. Esto implica determinar la probabilidad de cada posible estado de una variable dada la combinación de estados de sus variables padre.
Estimar los parámetros de la red: una vez que se hayan especificado las DPCs, es necesario estimar los parámetros de la red a partir de datos observados. Esto puede implicar el uso de técnicas como el método de máxima verosimilitud o el enfoque bayesiano.
Realizar inferencias: una vez que la red bayesiana está desarrollada y los parámetros están estimados, la utilizamos para realizar inferencias probabilísticas. Esto implica responder preguntas sobre la probabilidad de ciertos estados de las variables dadas ciertos valores observados o evidencia. Es importante destacar que desarrollar una red bayesiana puede ser un proceso iterativo, en el cual puedes ajustar y refinar la estructura del grafo y las DPCs a medida que adquieres más conocimiento y datos. Además, existen diversas herramientas y bibliotecas que pueden facilitar el desarrollo y la manipulación de redes bayesianas, como PyMC3, Stan, y la librería bnlearn en R.
Ejemplo básico de red bayesiana: Supongamos que tenemos las siguientes variables:
“Cáncer de mama”: Variable que indica si el paciente tiene cáncer de mama o no. Puede tomar los valores “Sí” o “No”.
“Resultado de la mamografía”: Variable que indica el resultado de la mamografía del paciente. Puede tomar los valores “Negativo” o “Positivo”.
“Edad”: Variable que indica la edad del paciente. Puede tomar los valores “Joven”, “Media” o “Mayor”.
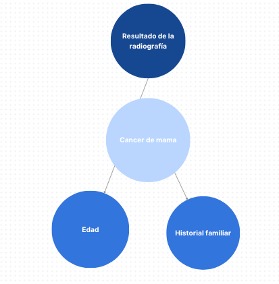
“Historial familiar”: Variable que indica si el paciente tiene antecedentes familiares de cáncer de mama. Puede tomar los valores “Sí” o “No”. La estructura de la red bayesiana para este ejemplo se muestra de la siguiente manera:
En este ejemplo, asumimos que el resultado de la mamografía influye en la probabilidad de tener cáncer de mama, y tanto la edad como el historial familiar también influyen en la probabilidad de tener cáncer de mama. Para desarrollar esta red bayesiana, necesitaríamos definir las distribuciones de probabilidad condicional para cada variable. Por ejemplo:
P(Cáncer de mama = Sí) = 0.01 (1% de probabilidad de tener cáncer de mama sin tener en cuenta otras variables).
P(Resultado de la mamografía = Positivo | Cáncer de mama = Sí) = 0.8 (80% de probabilidad de obtener un resultado positivo en la mamografía si se tiene cáncer de mama).
P(Resultado de la mamografía = Positivo | Cáncer de mama = No) = 0.1 (10% de probabilidad de obtener un resultado positivo en la mamografía si no se tiene cáncer de mama).
P(Edad = Joven) = 0.3 (30% de probabilidad de ser joven).
P(Edad = Media) = 0.5 (50% de probabilidad de ser de mediana edad).
P(Edad = Mayor) = 0.2 (20% de probabilidad de ser mayor).
P(Historial familiar = Sí | Cáncer de mama = Sí) = 0.6 (60% de probabilidad de tener antecedentes familiares de cáncer de mama si se tiene cáncer de mama).
P(Historial familiar = Sí | Cáncer de mama = No) = 0.1 (10% de probabilidad de tener antecedentes familiares de cáncer de mama si no se tiene cáncer de mama). Con estas distribuciones de probabilidad condicional definidas, podemos realizar inferencias probabilísticas sobre la probabilidad de que un paciente tenga cáncer de mama dadas las observaciones de otras variables, como el resultado de la mamografía, la edad y el historial familiar.
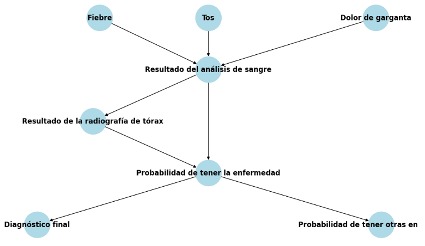
RED BAYESIANA IMPLEMENTADA
Se realiza un script en Python para implementar un modelo bayesiano que representa un sistema de diagnóstico médico basado en síntomas y resultados de pruebas médicas. El modelo utiliza una red bayesiana para modelar las relaciones causales entre las variables involucradas:
Las variables en el modelo son las siguientes:
Fiebre: representa la presencia o ausencia de fiebre en el paciente.
Tos: representa la presencia o ausencia de tos en el paciente.
Dolor de garganta: representa la presencia o ausencia de dolor de garganta en el paciente.
Resultado del análisis de sangre: representa el resultado del análisis de sangre del paciente.
Resultado de la radiografía de tórax: representa el resultado de la radiografía de tórax del paciente.
Probabilidad de tener la enfermedad: representa la probabilidad de que el paciente tenga la enfermedad en cuestión.
Diagnóstico final: Representa el diagnóstico final del paciente.
Probabilidad de tener otras enfermedades: representa la probabilidad de que el paciente tenga otras enfermedades Las relaciones entre las variables se establecen mediante las aristas en el grafo de la red bayesiana. Por ejemplo, se establece que Fiebre, Tos y Dolor de garganta influyen en el Resultado del análisis de sangre, y este último influye en la Probabilidad de tener la enfermedad y en el Resultado de la radiografía de tórax. A su vez, la Probabilidad de tener la enfermedad influye en el Diagnóstico final y en la Probabilidad de tener otras enfermedades. Las distribuciones de probabilidad condicional (CPDs) se definen para cada variable en función de sus padres en el grafo. Estas CPDs especifican cómo las variables padre afectan la probabilidad de los valores de las variables hijas.
MATERIALES
Para el desarrollo correcto de este modelo que implementa la red bayesiana se utilizaron las siguientes librerías de Python:
pgmpy: para modelado y análisis de redes bayesianas y modelos gráficos probabilísticos. Proporciona clases y métodos para construir y manipular redes bayesianas, calcular inferencias probabilísticas y realizar operaciones en los modelos gráficos. En este script, se utiliza para construir el modelo bayesiano, definir las CPDs y realizar inferencias.
networkx: para la creación, manipulación y estudio de estructuras de grafo. Proporciona una implementación de grafo flexible y eficiente, junto con algoritmos para recorrer y analizar los grafos. En este script, se utiliza para visualizar el grafo del modelo bayesiano.
pygraphviz: para la creación y manipulación de gráficos basados en Graphviz. Proporciona una interfaz de Python para trabajar con las funciones y características de Graphviz. En este script, se utiliza junto con networkx para definir el diseño del grafo del modelo bayesiano.
Estas librerías son ampliamente utilizadas en el campo del aprendizaje automático y la inteligencia artificial para modelar y analizar problemas probabilísticos, así como para visualizar y comunicar estructuras de datos complejas como las redes bayesianas.
RESULTADOS
La presencia de fiebre tiene una influencia significativa en la probabilidad de tener la enfermedad. Al observar que una persona presenta fiebre, la probabilidad de tener la enfermedad aumenta considerablemente. Por otro lado, al no presentar fiebre, la probabilidad de tener la enfermedad disminuye significativamente.
Esto sugiere que la fiebre es un factor clave en la detección y diagnóstico de la enfermedad en cuestión. La relación positiva entre la fiebre y la probabilidad de tener la enfermedad puede indicar que la fiebre es un síntoma característico o un indicador temprano de la enfermedad en el modelo.
En resumen, la presencia de fiebre tiene un impacto significativo en la probabilidad de tener la enfermedad según el modelo bayesiano. Esto destaca la importancia de considerar la fiebre como un síntoma relevante al evaluar el riesgo de tener la enfermedad y al tomar decisiones clínicas relacionadas con su diagnóstico y tratamiento.
La presencia de la enfermedad aumenta considerablemente la probabilidad de tener otras enfermedades. Cuando se observa que una persona tiene la enfermedad, la probabilidad de tener otras enfermedades es alta, con un valor de 0.8.
Por otro lado, cuando no se tiene la enfermedad, la probabilidad de tener otras enfermedades disminuye significativamente a 0.2. Esto sugiere que la presencia de la enfermedad está asociada con un mayor riesgo de tener múltiples enfermedades simultáneamente.
Esta inferencia puede tener implicaciones importantes en el ámbito médico. La detección temprana de la enfermedad puede ser un factor crucial para identificar y abordar la presencia de otras enfermedades comórbidas. Por lo tanto, es fundamental considerar la posibilidad de enfermedades adicionales al diagnosticar y tratar a los pacientes con la enfermedad en cuestión.
En resumen, el modelo bayesiano muestra una relación significativa entre la presencia de la enfermedad y la probabilidad de tener otras enfermedades. La detección temprana y el manejo integral de las comorbilidades pueden ser aspectos clave en la atención médica de los pacientes con la enfermedad en cuestión.
DISCUSIÓN
Se pueden sugerir algunas mejoras o áreas de enfoque para mejorar la precisión y utilidad del modelo. Mejorar el modelo bayesiano considerando la inclusión de más variables relevantes, obtener datos más precisos, validar y ajustar el modelo, refinar las distribuciones de probabilidad condicional y considerar la incertidumbre y la sensibilidad en las predicciones. Estas mejoras pueden contribuir a un modelo más preciso y útil para la detección y el manejo de la enfermedad en cuestión.
Mientras que la veracidad de los resultados obtenidos con este modelo bayesiano depende de varios factores como: si el modelo ha sido desarrollado y validado correctamente utilizando datos confiables y representativos, y si se han tenido en cuenta las suposiciones y limitaciones del modelo, los resultados obtenidos pueden ser considerados como una aproximación razonable de la realidad. Sin embargo, es importante recordar que ningún modelo es perfecto y siempre existe cierto grado de incertidumbre asociado a las predicciones realizadas. Por lo tanto, es fundamental interpretar los resultados con precaución y considerarlos como una herramienta complementaria para la toma de decisiones, en lugar de una verdad absoluta.
Finalmente, una red bayesiana es una herramienta muy útil para este tipo de aplicación descrita en el script. Una red bayesiana permite modelar de manera explícita las relaciones probabilísticas entre las variables relevantes en un dominio específico, lo que facilita el razonamiento y la toma de decisiones basados en la incertidumbre. En el contexto de la aplicación descrita, la red bayesiana permite modelar las relaciones entre los síntomas (fiebre, tos, dolor de garganta), los resultados de los análisis médicos, las probabilidades de tener la enfermedad y otras enfermedades, y el diagnóstico final. Esto proporciona un marco estructurado para representar y analizar la información disponible y realizar inferencias sobre la probabilidad de tener la enfermedad. La red bayesiana permite combinar de manera coherente la evidencia observada (por ejemplo, la presencia de fiebre) con las probabilidades condicionales y las relaciones causales en el modelo para calcular las probabilidades posteriores de interés, como la probabilidad de tener la enfermedad. Además, la visualización gráfica de la red bayesiana facilita la comprensión de las relaciones entre las variables y la comunicación de los resultados a diferentes partes interesadas, como médicos, investigadores o pacientes. Si se construye y valida correctamente, una red bayesiana puede ser una herramienta poderosa para el diagnóstico y la toma de decisiones en el ámbito médico, ya que permite cuantificar y utilizar de manera explícita la información incierta y probabilística disponible. Sin embargo, es importante tener en cuenta las limitaciones y suposiciones del modelo, así como la calidad de los datos utilizados, para interpretar adecuadamente los resultados y tomar decisiones informadas.
CLIP, which stands for “Contrastive Language–Image Pretraining”, is an artificial intelligence model developed by OpenAI that has been trained to understand images and text together. This allows it to perform tasks involving a combination of text and image processing, which sets it apart from many other AI models.
The CLIP model is trained using a method known as “contrastive learning”. This approach involves presenting the model with pairs of images and text that correspond to each other (for example, a picture of a dog and the phrase “a dog”) and pairs that do not correspond (for example, the same picture of a dog and the phrase “a coffee cup”). The model’s goal is to learn to correctly associate images with their corresponding text and reject incorrect pairings.
One of the most interesting aspects of CLIP is that, unlike many AI models that are trained for a specific task, CLIP is capable of performing a wide range of text and image processing tasks without any additional training. This is due to its ability to understand and generate representations of images and text in a shared feature space.
For instance, you could ask CLIP to classify images according to a variety of text descriptions, generate descriptive text for an image, or find the most relevant image for a given phrase. This makes it highly versatile and useful for a variety of applications.
2. State of the art
CLIP model strongly relies on three modern concepts of Artificial Intelligence: Firstly, it uses zero-shot transfer learning so that the model, that has been trained on one task, can later be applied to a different, unseen task without any task-specific training data. Secondly, it uses natural language supervision (human-generated natural language annotations or labels to guide and train machine learning models rather than a set of predefined features) and lastly, it is also a multimodal model since it processes data from two different modalities: text and image.
These disciplines had been explored for the last decade with the main goal of achieving generalised predictions of unseen object categories. One of the most important insights on this line of investigation was leveraged in 2013 by Richer Socher and co-authors at Stanford: They trained a model on CIFAR-10 dataset that was able to make predictions in a word embedding space that was able to predict two unseen classes. In that same year, DeVISE successfully scaled this approach and showcased the feasibility of fine-tuning an ImageNet model, enabling accurate predictions of objects beyond the original 1000 classes in the training set [2].
One of the most inspiring works for CLIP was made by Ang Li and his co-authors at FAIR in 2016 [3]. They made a paper in which they showcased the use of natural language supervision to enable zero-shot transfer learning on popular computer vision classification datasets, including the well-known ImageNet dataset. By fine-tuning an ImageNet CNN with the help of textual information from titles, descriptions, and tags of a vast collection of Flickr photos (around 30 million), they successfully expanded the model’s ability to predict a broader range of visual concepts (visual n-grams). As a result, they achieved an impressive accuracy of 11.5% on zero-shot ImageNet classification.
CLIP belongs to a line of investigation about learning visual representations from natural language supervision. Most of the papers that study this concept use modern AI techniques and architectures such as transformers, autoregressive language modelling, masked language modelling and other approaches of contrastive learning in different fields such as medical imaging [2].
3. Development
3.1. Architecture
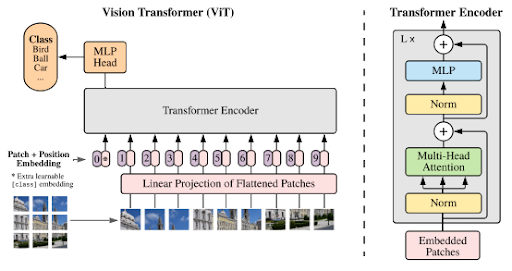
According to [6], CLIP is based on two different encoders to codify the images and text, respectively:
For the image encoder they proposed two different architectures, initially a ResNet-50 was used (along with other modifications for this base architecture), and a Visual Transformer (ViT). The final architecture to use was ViT due to the better efficiency shown than ResNet (up to 3 times more efficient).
For the text encoder they used a transformer model, with some modifications, following the base architecture from GPT-2 ([8])
ViT Architecture [7]
These two Transformers are used jointly to get powerful image and text representations, and be able to relate both representation types.
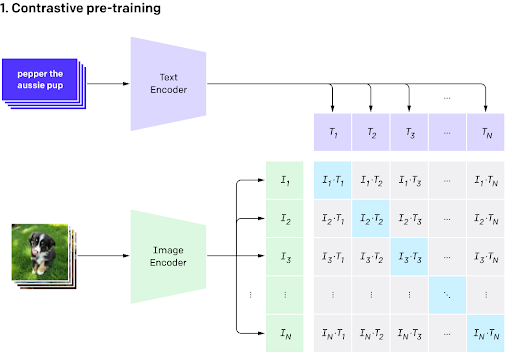
3.2. Contrastive Pre-training
Once we have explained the architecture, we now explain how to train both encoders (Contrastive Pretraining, [4]):
Select “N” images and “N” text describing each one of the images, respectively, as a batch
Codify the different images and texts with their respective encoder
To evaluate the similarity of each pair possible between image and text, calculate the cosine similarity between each pair image/text to get a matrix [N x N] representing the cross-similarity between the images and texts. A higher value means a greater similarity (semantic) between the corresponding image and text, while a lower value means the opposite
Image from CLIP: Connecting Text and Images, OpenAI [2]
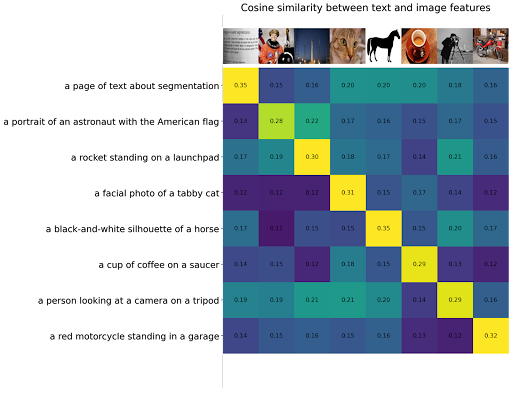
The objective is to maximize the values of the main diagonal (representing the pairs with the corresponding image/text) and minimize the other values. With this approach, we can describe the i-th picture only using the i-th description and not other independent descriptions. In the next image, we show the cosine similarity between text and image features for 8 images from the skimage dataset. As we have just mentioned, it can be clearly seen that this matrix adapts to a diagonal-matrix [5].
This approach allows us to train both text and image encoder to make better representations for the next point: Zero-Shot Learning.
3.3. Case of use: Zero-Shot Learning
Once we have explained the architecture, we put some examples to explain the different parts of the model. First of all, we need an image and different texts describing the image, some more detailed, others not, even wrong descriptions.
For the codification of the text and image, where use for both transformers (for image, a Vision Transformer; and for text, other similar to the used for image) already pre-trained with the “Conceptual Captions” dataset (a very large dataset with images of various web sources) for explication purposes.
3.4. Limitations
As we will see, the model shows a high potential to make a relationship between text features and image features, but also we can appreciate a little gap between the performance between using “prepared” data and real data due to these images can have noisy sections, affecting the representation produced by the encoder, giving less accurate predictions as a result.
The performance also depends on the used dataset. According to [1], if we use a lineal classification on the ImageNet Dataset using the CLIP features, the CLIP accuracy has a 10% increment in the results, but on average, using other datasets, the performance is worse, so we can conclude that there is an implicit “bias” depending on the dataset used.
The CLIP model used is focused on physical object recognition (chair, cat, tree…), but for other tasks more abstract like counting the different objects on an image (three cars, six chairs…); and more complex like predicting the depth of each object or making a facial emotion recognizer to predict the respective text according to the proposed image.
Lastly, CLIP isn’t able to generalize objects not included in the pre-trained dataset (for example, using images of the dataset MNIST (handwritten digits), the model’s accuracy decreases 10%), making the model very sensitive to how we must describe the images for a better or worse representation.
4. Results
In our case of use, we have followed two approaches:
Applying it to some random images from the public dataset CIFAR100, which contains 32×32 images belonging to 100 different classes of objects.
Testing CLIP’s real-world performance selecting some images to understand the behaviour of the model with images never seen by the pre-trained model.
For these 3 examples from CIFAR100, we show their top predictions, where it can be seen that CLIP wrongly predicts a lion whilst the real label is a lion. Nevertheless, the two following images are correctly classified.
import os
import clip
import torch
from torchvision.datasets import CIFAR100
import matplotlib.pyplot as plt
import random
# Load the model
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load('ViT-B/32', device)
# Download the dataset
cifar100 = CIFAR100(root=os.path.expanduser("~/.cache"), download=True, train=False)
# Get 4 random images from the dataset
id_images = random.sample(range(len(cifar100)), 3)
# Apply the model to the images
for i in id_images :
# Prepare the inputs
image, class_id = cifar100[i]
image_input = preprocess(image).unsqueeze(0).to(device)
text_inputs = torch.cat([clip.tokenize(f"a photo of a {c}") for c in cifar100.classes]).to(device)
# Calculate features
with torch.no_grad():
image_features = model.encode_image(image_input)
text_features = model.encode_text(text_inputs)
# Pick the top 5 most similar labels for the image
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
similarity = (100.0 * image_features @ text_features.T).softmax(dim=-1)
values, indices = similarity[0].topk(5)
# Print the result
print("\nTop predictions:")
for value, index in zip(values, indices):
print(f"{cifar100.classes[index]:>16s}: {100 * value.item():.2f}%")
# Print the original label with the image
print("Real label:", cifar100.classes[class_id])
plt.imshow(image)
plt.axis('off')
plt.show()
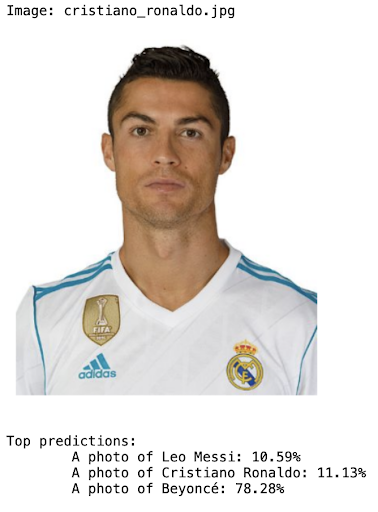
For some images from the internet, as it is mentioned by Nikos Kafritsas [4], we show that CLIP knows how to correctly understand the context and the background from a given image. This case distinguishes between a dog in different scenarios.
import torch
import clip
from PIL import Image
import pandas as pd
import os
import numpy as np
import matplotlib.pyplot as plt
device = "cuda" if torch.cuda.is_available() else "cpu"
model, preprocess = clip.load("ViT-B/32", device=device)
dir_path = './images/'
text_input = ["A photo of Cristiano Ronaldo", "A photo of Leo Messi", "A photo of Rauw Alejandro", \
"A photo of C. Tangana", "A photo of a dog", "A photo of a golden retreiver running", \
"A golder retriever standing", "A dog", "A dog in the beach",
"A photo of a diagram", "A photo of a chair", "A photo of a table", "A photo of a banana"\
]
text = clip.tokenize(text_input).to(device)
for img in os.listdir(dir_path):
original_image = Image.open(dir_path+img)
image = preprocess(Image.open(dir_path+img)).unsqueeze(0).to(device)
with torch.no_grad():
image_features = model.encode_image(image)
text_features = model.encode_text(text)
logits_per_image, logits_per_text = model(image, text)
probs = logits_per_image.softmax(dim=-1).cpu().numpy()
indices = np.argsort(probs[0])[-5:]
values = probs[0][indices]
# Print the result
print("Image:", img)
plt.imshow(original_image)
plt.axis('off')
plt.show()
print("\nTop predictions:")
for value, index in zip(values, indices):
print(f"\t{text_input[index]:}: {100 * value.item():.2f}%")
print("\n",'-'*15, "\n")
We also show the results on some other different tasks like recognizing a banana, a chair or something more abstract like a diagram, completing it without any difficulty.
Moreover, we have tested by ourselves the limitations mentioned (celebrity-recognition, hand-written digits, facial emotions and counting objects) [6] and they all struggle to complete the task correctly.
5. Discussion
As we have seen in the previous examples, CLIP model is a powerful tool for understanding and connecting text and images, with the ability to comprehend context and perform tasks such as automatic image labelling and text-image pairing. However, it may have limitations and poorer performance in tasks that involve a deeper level of understanding, such as sentiment detection, getting the exact number of objects that are in an image, or generating images from text instead of text from images. It is important to consider these strengths and limitations when applying CLIP in different scenarios and tasks.
Bibliography
[1] R. Taori, A. Dave, V. Shankar, N. Carlini, B. Recht, and L. Schmidt, “Measuring robustness to natural distribution shifts in image classification,” arXiv [cs.LG], 2020.
[2] Clip: Connecting text and images (2021) CLIP: Connecting text and images. Available at: https://openai.com/research/clip (Accessed: 10 June 2023).
[3] A. Li, A. Jabri, A. Joulin, and L. van der Maaten, “Learning visual N-grams from web data,” arXiv [cs.CV], 2016.
En la actualidad, la detección temprana y precisa de enfermedades pulmonares a través de radiografías desempeña un papel fundamental en el ámbito médico.
La utilización de técnicas de Deep Learning ha adquirido un papel destacado en el análisis médico, permitiendo mejoras significativas en la detección y clasificación de enfermedades. En este contexto, el estudio realizado por Shen et al. [1] ha demostrado los avances prometedores que se han logrado en el campo del análisis médico mediante el uso de redes neuronales profundas.
Los modelos preentrenados, como los utilizados en el estudio de Shen et al. [1], capturan de manera efectiva la información relevante en grandes conjuntos de datos y pueden adaptarse para abordar tareas específicas, mediante el uso de transfer learning, como la detección de COVID-19 en radiografías pulmonares.
Basándonos en las investigaciones previas y en los avances logrados en el análisis médico mediante el uso de redes neuronales profundas [1], junto con la técnica de transfer learning descrita por Pan y Yang [2], buscamos desarrollar un sistema de detección de COVID-19 en radiografías pulmonares.
El transfer learning es una técnica en la cual se aprovecha el conocimiento y la representación aprendida por una red neuronal previamente entrenada en un conjunto de datos relacionado. Nuestro objetivo es aprovechar el conocimiento y la representación aprendida por modelos preentrenados para lograr una detección precisa y temprana de la enfermedad.
Formulación
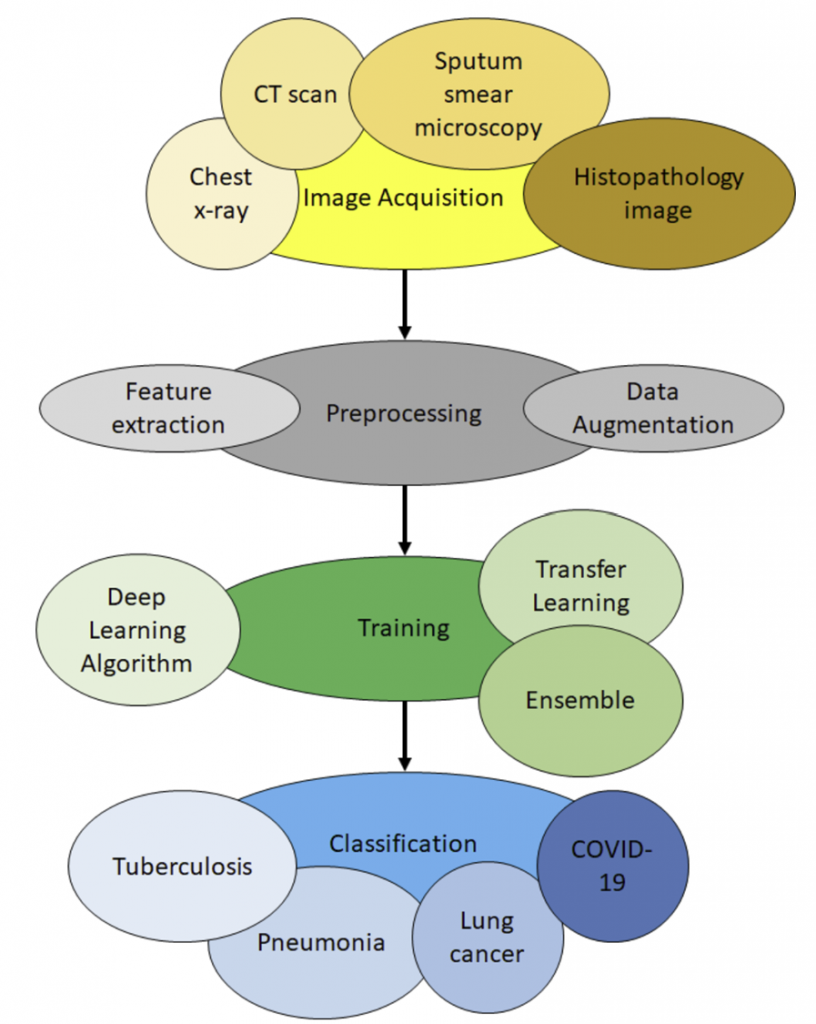
Nuestro objetivo principal es desarrollar un sistema capaz de detectar la presencia de COVID-19 en radiografías pulmonares. Para lograr esto, nos hemos basado en un proyecto previo disponible en Kaggle [3], el cual se enfoca en la detección de diversas enfermedades pulmonares utilizando una red neuronal MobileNet con una capa de promediado global (GAP) propuesta por K Scott Mader. En este proyecto, se han entrenado y guardado los pesos de la red neuronal.
En nuestro enfoque, utilizamos la técnica de transfer learning. El primer paso en la aplicación del transfer learning fue adquirir la solución propuesta por K Scott Mader y utilizarla como punto de partida. Esta etapa de preentrenamiento implica alimentar la red con imágenes de radiografías pulmonares etiquetadas con diferentes clases de enfermedades, lo que permite a la red aprender características relevantes y generar pesos óptimos para reconocer y clasificar las diversas enfermedades pulmonares.
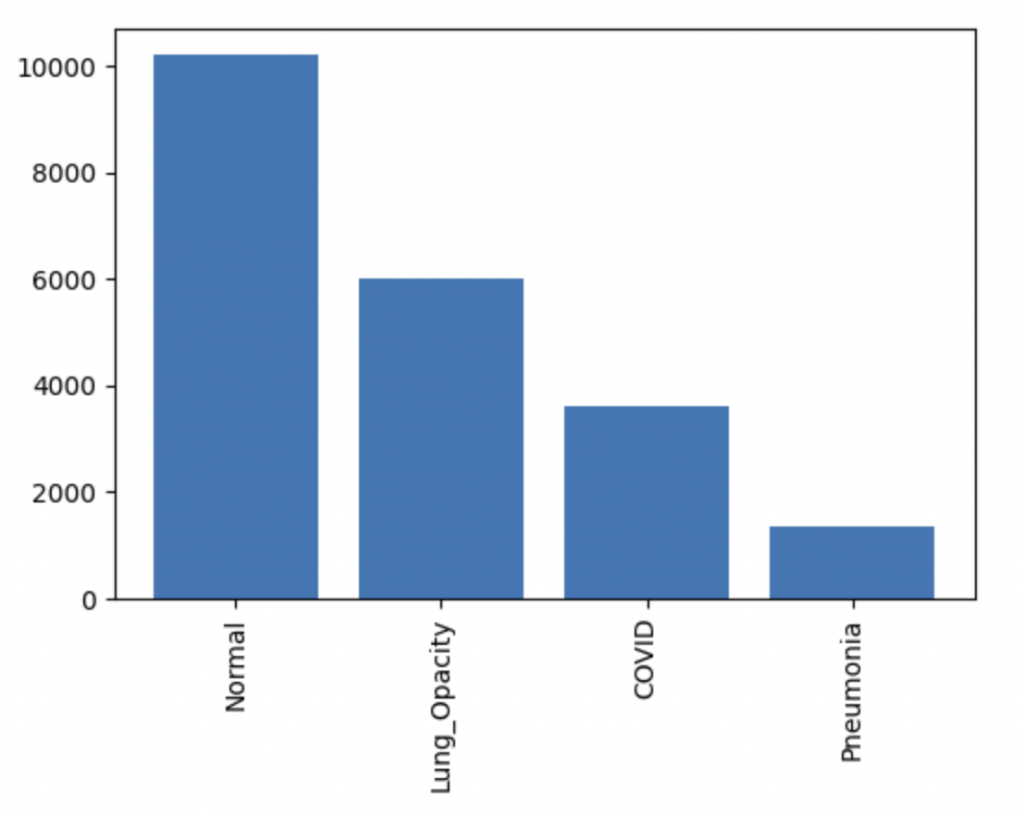
Una vez obtenido el modelo preentrenado, realizamos modificaciones específicas para adaptarlo a nuestra tarea de detección de COVID-19 en radiografías. Para ello, ajustamos las capas finales del modelo, eliminando las capas de clasificación originales y reemplazándolas con nuevas capas adecuadas para nuestro nuevo conjunto de datos, que hemos seleccionado también en la plataforma de Kaggle [4] y que consta de cuatro clases: COVID-19, neumonía viral, diagnóstico normal y opacidad pulmonar.
Este enfoque nos permite aprovechar el conocimiento y la representación aprendida por el modelo preentrenado en el dominio de enfermedades pulmonares. Al iniciar el entrenamiento con un modelo que ya ha capturado características relevantes en imágenes de radiografías pulmonares, podemos acelerar el proceso de aprendizaje y mejorar la precisión en la detección de COVID-19. Además, al adaptar el modelo a nuestro conjunto de datos específico, nos aseguramos de que pueda reconocer y clasificar correctamente las cuatro clases relevantes para nuestra tarea.
Desarrollo
Para comprobar las ventajas que puede tener el enfoque de transfer learning, hemos realizado un pequeño caso de estudio. Comenzamos cargando una red neuronal previamente entrenada que se encuentra en un proyecto de K Scott Mader [1].
En esta red se utiliza la arquitectura MobileNet como modelo base sin los pesos preentrenados. Luego se construye un modelo secuencial en el que se agregan capas adicionales. En nuestro caso de trabajo, cargamos los pesos guardados previamente, que contienen la información aprendida durante el entrenamiento del modelo original. Finalmente, compilamos el modelo utilizando la función de pérdida y métricas adecuadas.
Después de cargar la red previamente entrenada, ajustamos las capas finales del modelo MobileNet para adaptarlo a nuestra tarea de detección de COVID-19 en radiografías pulmonares. Para lograr esto, congelamos las capas de la red base, lo que significa que los pesos de esas capas no se actualizarán durante el entrenamiento. Luego, añadimos capas adicionales al final del modelo para ajustarlo a nuestras cuatro clases específicas, (COVID-19, neumonía viral, diagnóstico normal y opacidad), actualizando así la red neuronal previa.
# Congelar las capas
for layer in base_mobilenet_model.layers:
layer.trainable = False
# Agregar capas adicionales
num_classes = 4
x = base_mobilenet_model.output
x = GlobalAveragePooling2D()(x)
x = Dropout(0.5)(x)
x = Dense(512, activation='relu', kernel_regularizer=l2(0.001))(x) # Regularización L2 con factor de penalización 0.001
x = Dropout(0.5)(x)
predictions = Dense(num_classes, activation='softmax')(x)
covid_model = Model(inputs=base_mobilenet_model.input, outputs=predictions)
covid_model.compile(optimizer=Adam(), loss='categorical_crossentropy', metrics=['accuracy']) # Utiliza categorical_crossentropy para problemas de múltiples clases
# Calcular los pesos de clase
class_weights = {}
for i, c_label in enumerate(np.unique(all_labels)):
class_weights[i] = 1 / np.mean(test_Y[:, i])
weight_path_new = "{}_weights_new.best.hdf5".format('xray_class')
checkpoint = ModelCheckpoint(weight_path_new, monitor='val_loss', verbose=1,
save_best_only=True, mode='min', save_weights_only=True)
early = EarlyStopping(monitor="val_loss",
mode="min",
patience=3)
callbacks_list = [checkpoint, early]
covid_model.fit_generator(train_gen,
steps_per_epoch=396,
validation_data=(test_X, test_Y),
epochs=3,
class_weight=class_weights, # Ajustar los pesos de clase
callbacks=callbacks_list)
Agregamos una capa de promediado global para capturar características globales de las imágenes y reduce la dimensionalidad de la salida.
Incluimos una capa de regularización por eliminación(dropout) para prevenir el sobreajuste al apagar aleatoriamente un porcentaje de las unidades de entrada durante el entrenamiento.
Añadimos una capa densa con activación ReLU para combinar características y generar representaciones más complejas. Para evitar el sobreajuste, aplicamos regularización L2 a los pesos de esta capa
Por último, utilizamos una capa de salida con activación softmax para obtener las probabilidades de pertenencia a cada clase.
Posteriormente, para abordar el desequilibrio de clases en el conjunto de datos, calculamos los pesos de clase. Estos pesos se asignan de forma inversamente proporcional a la media de las muestras en cada clase, lo que permite que el modelo se enfoque más en las clases menos representadas.
Finalmente, ajustamos el modelo utilizando un generador de datos para el conjunto de entrenamiento y especificamos los hiperparámetros. A través de este enfoque de transfer learning y la adaptación del modelo a nuestro dominio de interés, logramos entrenar un modelo capaz de detectar COVID-19 en radiografías pulmonares.
Discusión de resultados
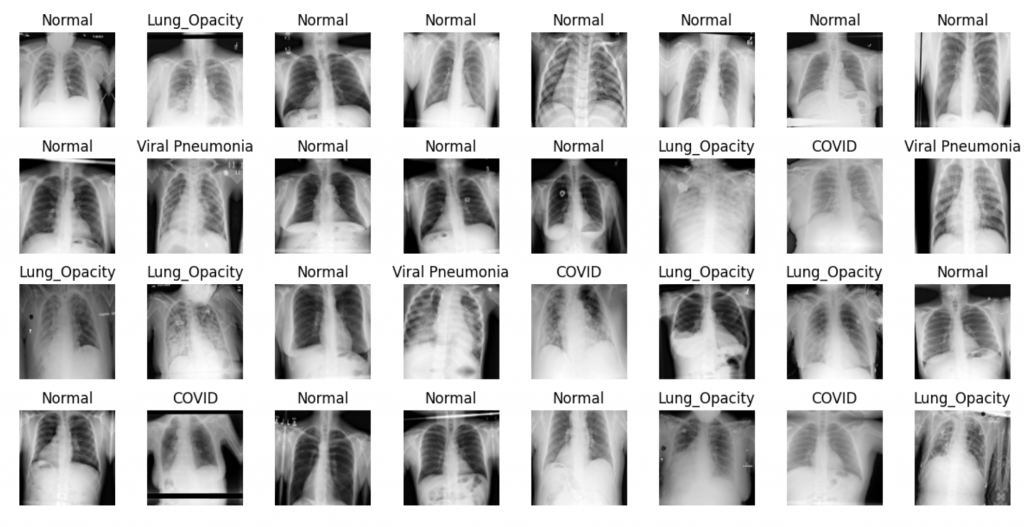
En primer lugar, analizamos una forma de evaluar y visualizar la precisión del modelo en la clasificación de cada clase individualmente, mostrando el porcentaje de aciertos para cada clase en relación con el conjunto de prueba, obteniendo los siguientes resultados:
Los resultados obtenidos indican que el modelo logró identificar correctamente aproximadamente el 22% de las radiografías con Covid-19 en el conjunto de prueba (Dx: 21.88%). Además, las predicciones del modelo tuvieron un 26.50% de aciertos en la clasificación de casos de Covid-19 (PDx: 26.50%).
Esto significa que el modelo mostró cierta capacidad para detectar la presencia de Covid-19 en las radiografías pulmonares analizadas, aunque también se observa un margen de mejora, ya que hubo una proporción considerable de casos que no fueron identificados correctamente.
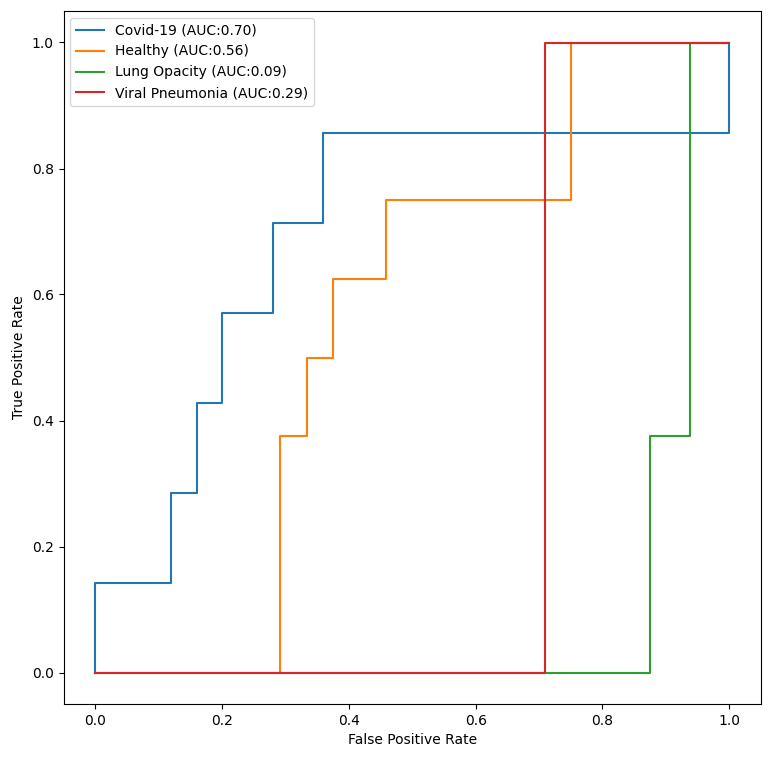
También se empleó la métrica de área bajo la curva ROC (ROC AUC) para evaluar el rendimiento del modelo en la detección de COVID-19, obteniendo un valor de 0.70. Esta métrica evalúa la capacidad del modelo para distinguir entre casos positivos y negativos de COVID-19. Cuanto más cercano a 1 sea el valor de ROC AUC, mejor será el desempeño del modelo en la clasificación.
En este caso, un valor de 0.70 indica que el modelo tiene una capacidad moderada para diferenciar entre casos positivos y negativos de COVID-19, lo que implica una tasa aceptable de verdaderos positivos y falsos positivos en la clasificación de casos de COVID-19. La métrica de ROC AUC permite evaluar la eficacia de un modelo en términos de su capacidad para realizar predicciones precisas.
Durante el entrenamiento de los datos mediante tres épocas, los resultados muestran que el modelo logró una precisión de alrededor del 50% en la clasificación de las imágenes en todas las clases, incluyendo el caso específico del COVID-19. Esto indica que el modelo tiene dificultades para realizar predicciones precisas en este conjunto de datos. Sería necesario mejorar el modelo o ajustar los parámetros de entrenamiento para obtener una precisión más alta y un mejor rendimiento en la detección de casos de COVID-19.
Conclusión
Para concluir, en este caso de trabajo se ha desarrollado un sistema de detección de COVID-19 en radiografías pulmonares utilizando técnicas de transfer learning y redes neuronales profundas.
El enfoque de transfer learning nos permitió aprovechar el estado del arte en el análisis médico mediante el uso de modelos preentrenados, capturando características relevantes en grandes conjuntos de datos de enfermedades pulmonares.
A pesar de que el modelo logró identificar correctamente aproximadamente el 22% de las radiografías con COVID-19 en el conjunto de prueba, se observa la necesidad de mejorar la precisión en la detección de casos de COVID-19. Estos resultados están en línea con el estado del arte en este campo, donde se han logrado avances prometedores en la detección y clasificación de enfermedades pulmonares mediante el uso de redes neuronales profundas.
Como propuesta de mejora, futuras investigaciones podrían enfocarse en la optimización del modelo y el ajuste de los parámetros de entrenamiento para obtener una mayor precisión y un mejor rendimiento en la detección temprana y precisa de COVID-19 en radiografías pulmonares.
Hemos utilizado el artículo de Venugopal et al. [6] como referencia para la investigación de casos e información, así como para los conjuntos de datos utilizados en nuestro caso de estudio.
Referencias
[1] Shen, D., Wu, G., & Suk, H. (2017). Deep Learning in Medical Image Analysis. Annual Review of Biomedical Engineering, 19, 221-248. doi: 10.1146/annurev-bioeng-071516-044442. [Enlace]
[2] Pan, S.J., & Yang, Q. (2010). A Survey on Transfer Learning. IEEE Transactions on Knowledge and Data Engineering, 22, 1345-1359. doi: 10.1109/TKDE.2009.191.[Enlace]
[5] K. Mader, “Train-Simple-XRay-CNN,” Kaggle, 2021. [Enlace]
[6] K. Venugopal, R. Suresh, A. Jaisankar, M. Ramasamy, V. Bhuvaneswari, and S. U. Pillai, “Automated Deep Learning Framework for Detection and Classification of COVID-19 Infections on Chest X-ray Images,” IEEE Access, vol. 9, pp. 108724-108739, 2021. doi: 10.1109/ACCESS.2021.3108905. [Enlace]
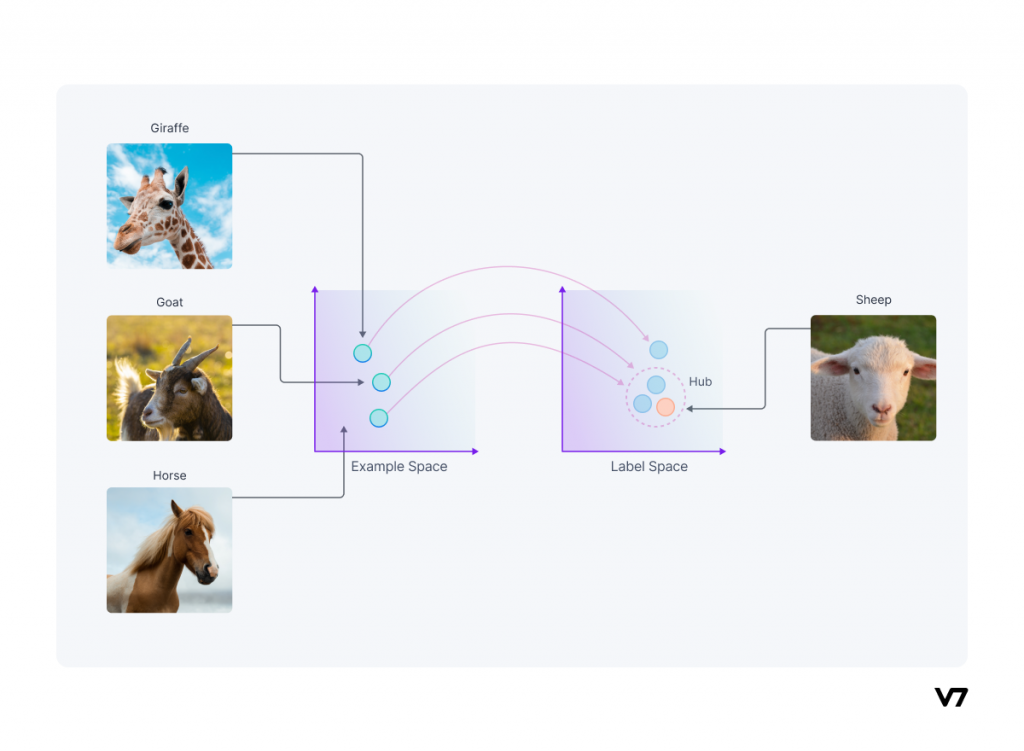
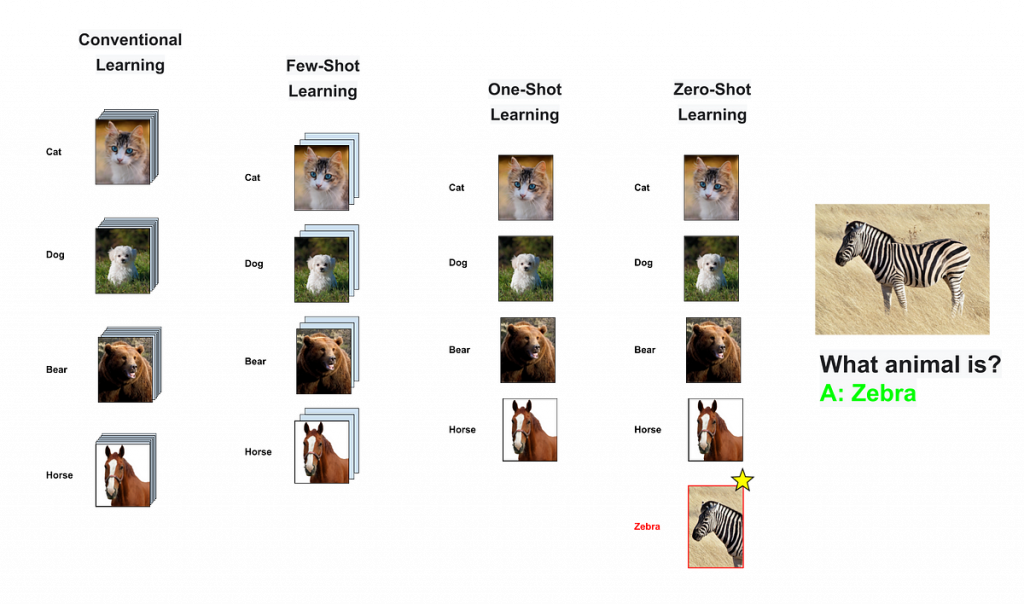
En el ámbito de la inteligencia artificial y el aprendizaje automático, una técnica revolucionaria conocida como Zero Shot Learning o aprendizaje con cero muestras de entrenamiento, está ganando terreno. Esta metodología prometedora está cambiando la forma en que las máquinas aprenden y reconocen objetos, sin necesidad de un entrenamiento específico previo. Al utilizar el Zero Shot Learning, las máquinas pueden adquirir conocimiento sobre conceptos nunca antes vistos, abriendo así nuevas posibilidades en el reconocimiento de imágenes y la comprensión de texto. En esta entrada de blog, examinaremos en detalle qué es exactamente el Zero Shot Learning y todos los aspectos que lo contextualizan.
2. Estado del arte
Zero Shot Learning es un concepto dentro del aprendizaje automático que se ocupa del escenario en el que el modelo se entrena en un conjunto de clases y se prueba en otro conjunto de clases sin recibir supervisión para el segundo conjunto. Es una tarea desafiante que requiere que el modelo aprenda a reconocer nuevas clases basándose en sus atributos, en lugar de memorizar solo los ejemplos del conjunto de entrenamiento. En los últimos años, se ha logrado un progreso significativo en el campo del aprendizaje sin ejemplos, y se han propuesto muchas técnicas para abordar este problema.
Rezaei y Shahidi (2020) [1] ofrecen una revisión exhaustiva de las técnicas de aprendizaje sin ejemplos y sus aplicaciones, desde vehículos autónomos hasta el diagnóstico de COVID-19. Long et al. (2017) [2] proponen un método para sintetizar datos visuales invisibles para el Zero-Shot Learning, lo que permite una transformación de este a la clasificación supervisada convencional. Xian et al. (2020) [3] evalúan los algoritmos de vanguardia para el aprendizaje sin ejemplos, destacando sus fortalezas y debilidades. Proporcionan una evaluación exhaustiva de los diferentes enfoques de aprendizaje sin ejemplos y sus limitaciones. Yang et al. (2022) [5] realizan una encuesta sobre la clasificación de imágenes sin ejemplos, abarcando una amplia gama de métodos, implementaciones y evaluaciones justas. Además, Fool et al. (2017) [6] ofrecen una descripción general de los avances recientes en el reconocimiento sin ejemplos, discutiendo la investigación más reciente sobre este tema.
En general, el aprendizaje sin ejemplos es un área de investigación activa, y hay muchos esfuerzos en curso para mejorar el rendimiento de los modelos en esta tarea desafiante. Los investigadores han propuesto varios enfoques diferentes, cada uno con sus fortalezas y limitaciones. Sin embargo, los avances significativos logrados hasta ahora en esta área han demostrado el potencial del aprendizaje sin ejemplos para abordar muchos problemas del mundo real al permitir modelos que generalizar a nuevas clases con cantidad limitadas de datos de entrenamiento.
3. Desarrollo
Zero-Shot Learning (ZSL) es un enfoque revolucionario en el campo del aprendizaje automático que permite a los modelos reconocer y clasificar objetos, o simplemente conceptos, sin haberlos visto previamente durante el entrenamiento. Se logra estableciendo una relación semántica entre los datos de entrenamiento y los nuevos datos de prueba, lo que facilita la transferencia de conocimientos a través de dominios no vistos. Esta metodología demuestra su poder como una herramienta que amplía las capacidades de los modelos y tiene aplicaciones en diversos campos, desde la visión por computadora hasta el procesamiento del lenguaje natural. Mientras que el Zero-Shot Learning se basa en la capacidad de reconocer clases no vistas durante el entrenamiento, existen otros tipos de aprendizaje diferentes a este:
One-Shot Learning (OSL)[1] One-Shot Learning es un desafío que consiste en aprender clases novedosas con un conjunto de entrenamiento reducido, compuesto por una o unas pocas imágenes por categoría.
Few-Shot Learning (FSL)[1] Few-Shot Learning aborda el desafío de aprender nuevas clases con un conjunto de datos de entrenamiento pequeño, generalmente unos pocos ejemplos por categoría.
Dentro del Zero-Shot Learning existen diferentes tipos de arquitecturas [4] como la basada en grafos, la basada en redes neuronales convolucionales y la basada en redes neuronales recurrentes. Cada una de estas arquitecturas tiene sus propias características y funcionalidades. En la arquitectura basada en grafos se utilizan grafos semánticos para representar las relaciones entre las características de los objetos y las categorías. En la arquitectura basada en redes neuronales convolucionales se utilizan redes neuronales convolucionales para extraer características de las imágenes y se combinan con atributos de texto para realizar la clasificación. Por último, en la arquitectura basada en redes neuronales recurrentes se utilizan redes neuronales recurrentes para aprender una representación de los atributos de texto y se combinan con características visuales para realizar la clasificación.
Finalmente, con respecto a las métricas de evaluación comunes utilizadas en el aprendizaje sin supervisión, como el Zero-Shot Learning, incluyen la Exactitud (Accuracy), la Precisión (Precision), la Sensibilidad (Recall) y el F1-score. La exactitud calcula el porcentaje de predicciones correctamente etiquetadas en comparación con el total de predicciones realizadas. La precisión mide la fracción de instancias que se clasifican correctamente como positivos en relación con el total de instancias que se clasifican como positivas. La sensibilidad mide la fracción de los verdaderos positivos que se identifican correctamente como tales en relación con el total de verdaderos positivos. El F1-score es una medida que combina tanto la precisión como la sensibilidad.
En resumen, el Zero-Shot Learning es un enfoque revolucionario que permite reconocer y clasificar objetos o conceptos no vistos previamente durante el entrenamiento, estableciendo relaciones semánticas. Además, existen otros enfoques como el One-Shot Learning y el Few-Shot Learning. En cuanto a las métricas de evaluación comunes en el aprendizaje sin supervisión, se utilizan la exactitud, precisión, sensibilidad y F1-score para medir la calidad de las predicciones.
4. Materiales y Resultados
En el contexto de los experimentos realizados, se utilizó la biblioteca Transformers [7], en particular la librería pipeline, para implementar un clasificador de Zero-Shot Learning. Esta biblioteca, desarrollada por Hugging Face, proporciona una interfaz sencilla y eficiente para utilizar modelos pre-entrenados en tareas de procesamiento del lenguaje natural. El clasificador de Zero-Shot Learning, cargado mediante el código proporcionado, permite asignar automáticamente etiquetas a textos sin la necesidad de entrenar un modelo específico para cada clase. Utilizando técnicas de transferencia de aprendizaje, el clasificador aprovecha un modelo pre-entrenado en una amplia gama de tareas de clasificación y puede ser aplicado a problemas en los que se necesita clasificar textos en clases no vistas previamente.
# Importación de la librería de trabajo
from transformers import pipeline
# Cargar el modelo de zero-shot classification
classifier = pipeline("zero-shot-classification")
Este código presenta un ejemplo de clasificación de una frase sin haberla visto durante el entrenamiento utilizando el clasificador de Zero-Shot Learning. En este caso, se proporciona la secuencia de texto “El hielo es agua en estado sólido” y se define una lista de posibles etiquetas de clasificación, como “animales”, “deportes”, “comida”, “geografía” y “ciencia”. Al ejecutar el clasificador, se obtiene un resultado que muestra la clasificación más probable para la frase de entrada, así como la confianza asociada a esa clasificación. En este ejemplo específico, se imprimiría la secuencia de texto, la clasificación obtenida (“ciencia”) y la confianza asociada a esa clasificación (por ejemplo, 0.3024).
# Clasificar una frase sin necesidad de haberla visto durante el entrenamiento
sequence = "El hielo es agua en estado sólido"
candidate_labels = ["animales", "deportes", "tecnología", "comida", "geografía", "ciencia"]
result = classifier(sequence, candidate_labels)
# Imprimir los resultados
print("Secuencia:", sequence)
print("Clasificación:", result['labels'][0])
print("Confianza:", result['scores'][0])
Procedemos a mostrar a continuación, distintos ejemplos de utilización del código para observar si la clasificación la realiza de manera correcta o comete fallos significativos:
5. Discusión
En los resultados anteriores, se clasificaron correctamente las secuencias: “Las islas Azores pertenecen a Portugal” como “geografía” (confianza: 0.33), “Zero-Shot Learning (ZSL) es un enfoque revolucionario en el campo del aprendizaje automático” como “tecnología” (confianza: 0.79), y “Zoe es un cachorro de la raza Pomerania” como “animales” (confianza: 0.86).
6. Referencias
[1] Rezaei, M., & Shahidi, M. (2020). Zero-shot learning and its applications from autonomous vehicles to COVID-19 diagnosis: A review. Intelligence-Based Medicine, 3-4, 100005. Enlace al documento [2] Long, Y., Liu, L., Shao, L., Shen, F., Ding, G., & Han, J. (2017). From Zero-shot Learning to Conventional Supervised Classification: Unseen Visual Data Synthesis. Department of Electronic and Electrical Engineering / University of Sheffield; School of Computing Sciences / University of East Anglia; Center for Future Media / University of Electronic Science and Technology of China; School of Software / Tsinghua University; Department of Computer Science and Digital Technologies / Northumbria University Enlace al documento [3] Xian, Y., Lampert, C.H., Schiele, B., & Akata, Z. (2020). Zero-Shot Learning: A Comprehensive Evaluation of the Good, the Bad, and the Ugly. Enlace al documento [4] Xian, Y., Schiele, B., & Akata, Z. (2020). Zero-Shot Learning: The Good, the Bad, and the Ugly. Max Planck Institute for Informatics. Enlace al documento [5] Yang, G., Ye, Z., Zhang, R., & Huang, K. (2022). A Comprehensive Survey of Zero-shot Image Classification: Methods, Implementation, and Fair Evaluation. Department of Intelligent Science / Xi’an Jiaotong-Liverpool University; Department of Foundational Mathematics / Xi’an Jiaotong-Liverpool University; Institute of Applied Physical Sciences and Engineering / Duke Kunshan University. Enlace al documento [6] Fu, Y., Xiang, T., Jiang, Y.-G., Xue, X., Sigal, L., & Gong, S. (2017). Recent Advances in Zero-shot Recognition. Enlace al documento [7] Hugging Face. Transformers Documentation. Extraído de: Enlace a la documentación
Esta web utiliza cookies para que podamos ofrecerte la mejor experiencia de usuario posible. La información de las cookies se almacena en tu navegador y realiza funciones tales como reconocerte cuando vuelves a nuestra web o ayudar a nuestro equipo a comprender qué secciones de la web encuentras más interesantes y útiles.
Cookies estrictamente necesarias
Las cookies estrictamente necesarias tiene que activarse siempre para que podamos guardar tus preferencias de ajustes de cookies.
Si desactivas esta cookie no podremos guardar tus preferencias. Esto significa que cada vez que visites esta web tendrás que activar o desactivar las cookies de nuevo.