Un problema habitual al leer datos de un fichero de texto es que cada linea de datos contenga datos de distinto tipo: cadenas de caracteres y datos numéricos. La lectura y extracción de dichos datos a variables es un poco más complicada que los casos en los que toda la información es del mismo tipo. Se va a resolver un ejemplo que permita aprender las técnicas que son necesarias en estos casos.
Para la resolución se va a utilizar el fichero datos.txt que, tras una línea de cabecera, contiene en cada línea los datos de incidencia COVID de un municipio de la provincia de Madrid a fecha 24 de noviembre de 2020. El fichero es el siguiente:
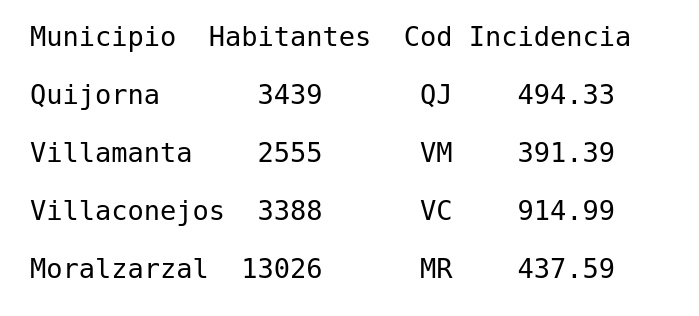
El alumno deberá crear este fichero con el editor, copiando los datos que contiene, y grabarlo con el nombre ‘datos.txt’, en el mismo directorio de trabajo donde se va a crear el programa .m de lectura del mismo.
La lectura del fichero debe comenzar con la apertura del mismo en modo lectura, ‘read’. El listado siguiente realiza la apertura del fichero y la comprobación de que el fichero se ha abierto correctamente. Al final del programa se pone la orden fclose(fid), para cerrar el fichero. El alumno deberá copiar estas instrucciones en el editor y guardarlo en el disco, en el mismo directorio en el que ha guardado el fichero ‘datos.txt’. El fichero del programa lo podemos llamar ‘readcovid.m‘, por ejemplo:

Conviene probar esta parte del programa. El programa se ejecuta desde la ventana de comandos, tecleando el nombre del programa ‘readcovid’. Antes de ejecutar el programa haga un ‘clear’, para borrar las variables del espacio de trabajo. Si al ejecutarlo no aparece nada en pantalla, es que ha funcionado bien. En el espacio de trabajo veremos la variable ‘fid’ con el identificador de fichero que le haya sido asignado, y la variable ‘ans’ con el valor cero, correspondiente a la ejecución correcta de la instrucción ‘fclose()’. Si en pantalla se muestra el mensaje ‘Error al abrir fichero’, es que el programa no encuentra el fichero de datos, quizás por poner mal el nombre en la instrucción ‘fopen’, o quizás porque el fichero de datos no está en el mismo directorio que el fichero del programa.
Una vez que se comprueba que funciona correctamente, vamos a proceder a completar las instrucciones de lectura antes de la orden ‘fclose(fid)’. El problema que vamos a resolver es leer los datos del fichero, determinar el municipio con mayor incidencia de COVID, y mostrar en pantalla sus datos: Municipio, Habitantes, Cod e Incidencia.
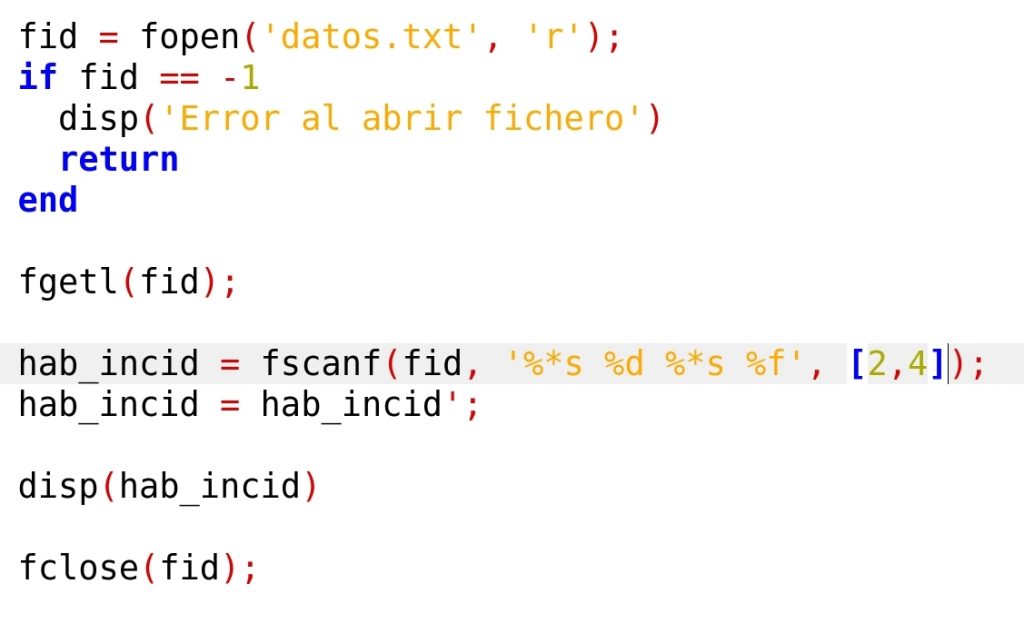
Vamos a empezar leyendo solo una línea, para entender el funcionamiento. La siguiente versión del programa lee los datos del primer municipio y los guarda en variables.

Lo primero que hace el programa es saltarse la línea de las cabeceras, mediante ‘fgetl()’. A continuación, lee los datos de una línea, de uno en uno, y los guarda en variables. Por último, hace un ‘fgets()’, para completar la lectura de la línea, leyendo el caracter fin de línea. De esta manera, el ‘cabezal de lectura’ quedará posicionado al principio de la siguiente línea de datos, preparado para seguir leyendo. El alumno debe observar que, para leer cada dato, la instrucción ‘fscanf’ utiliza el formato adecuado e indica que solo lee 1 dato. Tras ejecutar el programa y si todo va bien, la ventana del espacio de trabajo deberá mostrar las variables con los valores correctos (conviene hacer un ‘clear’, antes de cada ejecución del programa, para vaciar la memoria y el espacio de trabajo. Si se hace así, el espacio de trabajo mostrará, además de las variables del municipio, la variable ‘ans’ con el valor 0, correspondiente al resultado correcto de la orden ‘fclose’).
Una vez comprobado que podemos leer una línea de manera correcta, podemos proceder a leer todo el fichero, mediante un bucle ‘while’ con la condición ‘~feof(fid)’, o sea, ‘mientras no estemos en el FILE END OF FILE’. Para localizar el municipio con mayor incidencia de COVID en los últimos catorce días, aplicaremos el algoritmo del máximo. Inicializamos a cero unas variables donde guardar los datos máximos: munimax, habmax, codmax y incidmax. Cada vez que encontremos un municipio con incidencia máxima, guardaremos sus datos en las variables. Al final del bucle, tendremos guardados en las variables los datos del municipio con mayor incidencia, y los mostraremos en pantalla:
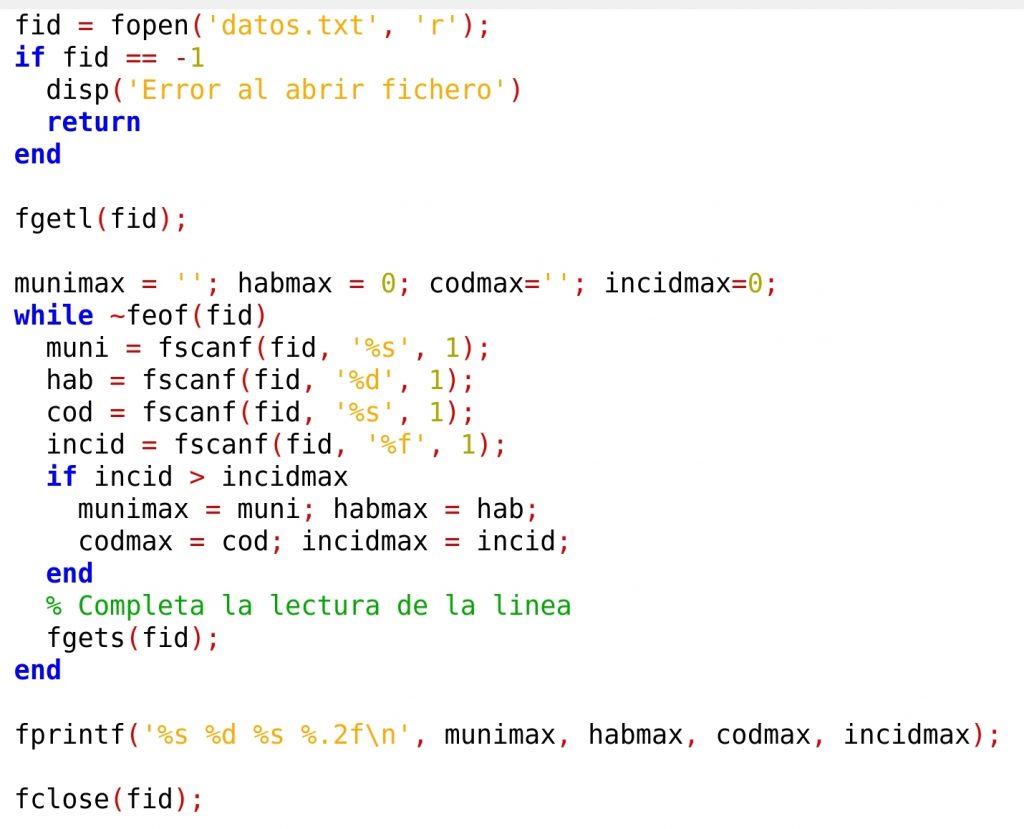
Al ejecutar el programa, y si todo va bien, deberíamos obtener una salida como la siguiente:

Otra técnica para leer este tipo de ficheros consiste en utilizar la instrucción ‘sscanf()’, que permite decodificar una cadena de texto. La instrucción ‘sscanf (String Scan Formatted)‘ funciona igual que la instrucción ‘fscanf’ (File Scan Formatted), con la salvedad de que ‘sscanf’ lee datos desde una cadena de texto, mientras que ‘fscanf’ lee datos desde un fichero.
La técnica es similar, pero se leen líneas completas del fichero a una cadena de texto con ‘fgetl()’, y luego se decodifica la cadena con ‘sscanf()’. Para explicar el funcionamiento de la instrucción ‘sscanf’, vamos a jugar un poco en la ventana de comandos, antes de hacer el programa que lee el fichero COVID.
Ejecute en la ventana de comandos las siguientes instrucciones:

Creamos primero una cadena de texto en la variable cad, y luego utilizamos la instrucción ‘sscanf’ para extraer el primer valor, como cadena de texto, a la variable ‘muni’. Observese que el primer parámetro que pasamos a la instrucción ‘sscanf’ es la cadena que queremos decodificar, luego el formato de la decodificación y, por último, el número de elementos que queremos extraer con ese formato.
Para extraer el segundo valor de la cadena, hay que saltarse el primer valor y leer el segundo. Esto se consigue poniendo un formato ‘%*s’. El asterisco que ponemos entre el símbolo % y la letra s hace que dicho formato lo lea, pero no lo guarde. El valor que guarda en la variable es el del segundo formato. Seguimos diciendo a ‘sscanf’ que lea un solo valor, el valor que se salta no cuenta:

Para leer el tercer valor, hay que saltarse los dos primeros. Aquí hay que tener cuidado: aunque el segundo valor sea un entero, para saltarlo hay que utilizar ‘%*s’, como si fuera una cadena de texto. Si lo intentáramos saltar con un formato ‘%*d’, el tercer valor no lo leería como cadena, sino como un array de doubles. Por tanto, para saltarse valores, siempre hay que hacerlo con ‘%*s’, como si fueran cadenas, aunque sean números lo que queremos saltar:

La lectura del cuarto dato no presenta mayores dificultades:

Una vez entendido cómo funciona la instrucción ‘sscanf’, reproducimos a continuación el listado del mismo programa que hicimos antes, para extraer los datos del municipio con mayor incidencia:
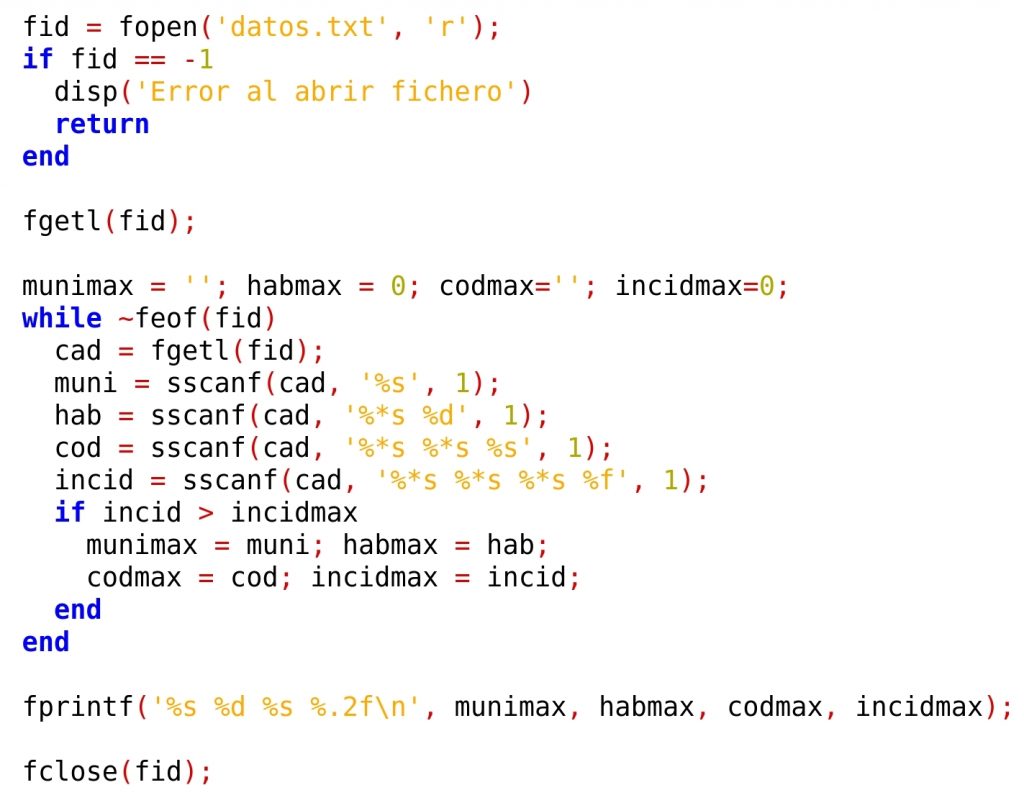
La salida de este programa debería ser idéntica a la de la otra versión.
Vamos a ver, por último, cómo resolver si no se quieren guardar todos los datos de cada línea, sino solo alguno de ellos, descartando los demás. Por ejemplo, vamos a leer el número de habitantes de cada municipio a un vector, pero descartando todo el resto de información. La técnica consiste en leer en cada línea hasta el dato que buscamos, y descartar el resto de la línea haciendo ‘fgets()’:
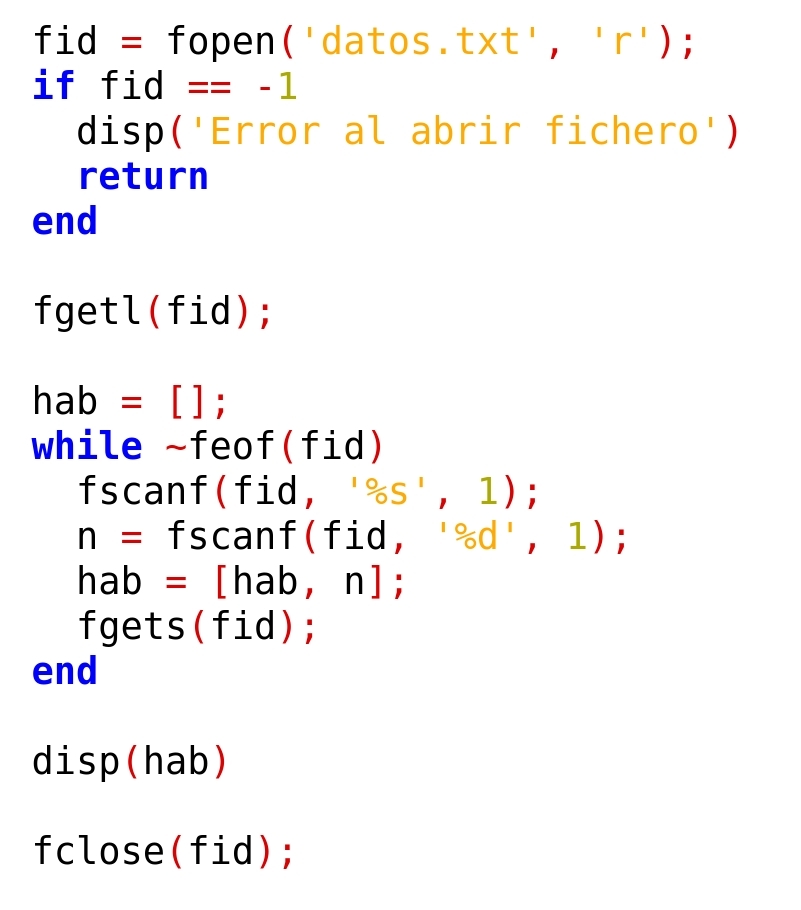
La salida de este programa debería ser la siguiente:
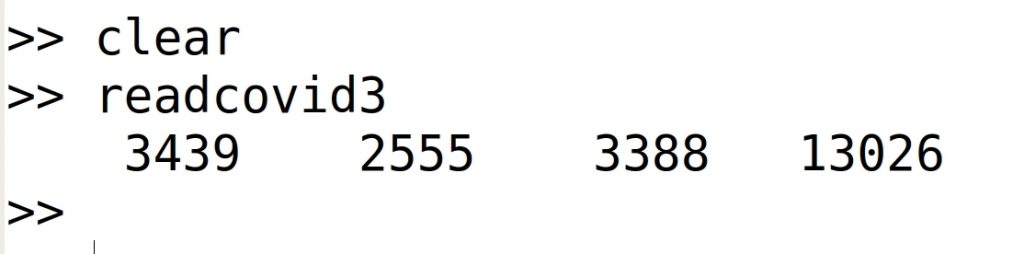
Analogamente a lo realizado en el caso resuelto con ‘sscanf’, aquí también podríamos utilizar la técnica de saltarnos datos, con lo que el programa quedaría:
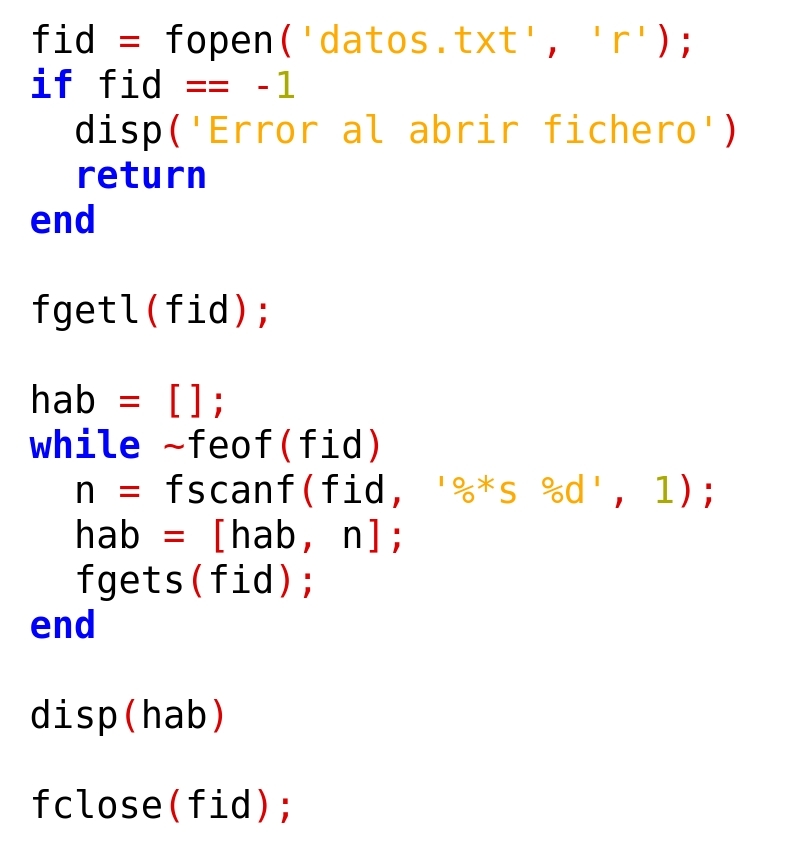
Al ejecutar el programa, el resultado sería idéntico al anterior.
Para este caso de querer leer solo los datos numéricos de una de las columnas del fichero a un vector, podemos combinar la técnica de saltarse datos con la de repetir el formato hasta que se acabe el fichero, y leer el vector con el número de habitantes de los municipios en una única instrucción y sin utilizar bucles:
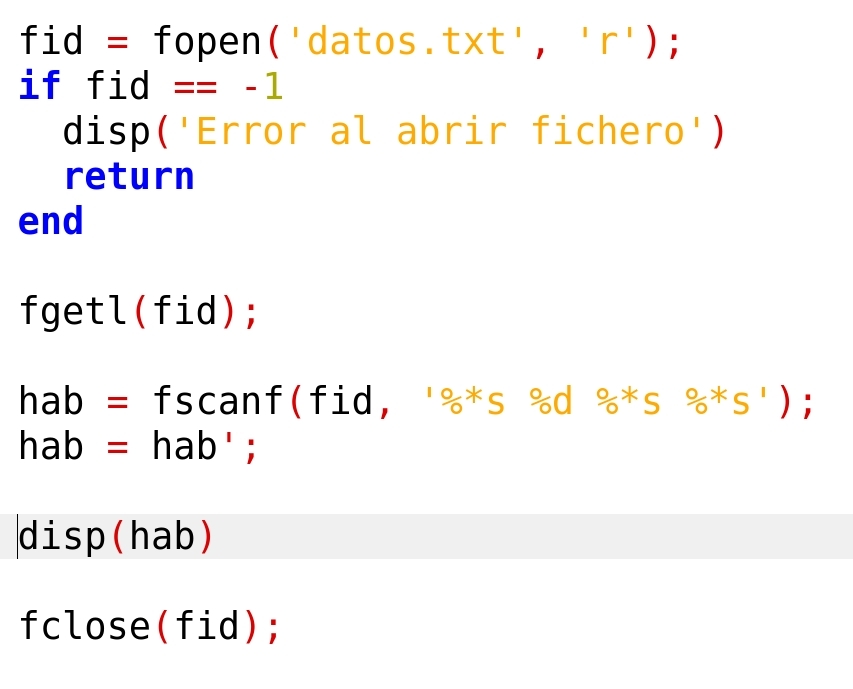
La salida de resultados sería la misma que en los dos casos anteriores.
Por último, utilizando esta técnica, podríamos leer una matriz que tenga en la primera columna el número de habitantes, y en la segunda columna la incidencia COVID: