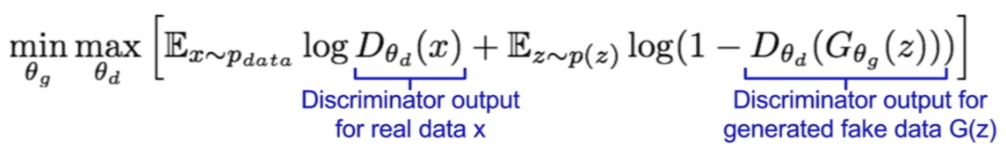Introducción
En el campo del procesamiento de datos tridimensionales, las Redes Adversarias Generativas (GANs) se han posicionado como una de las tecnologías más prometedoras y transformadoras de los últimos años. Estas redes están marcando un cambio significativo en la forma en que se crea contenido en 3D, especialmente en campos como el desarrollo de juegos y simulaciones realistas.
En este blog, nos sumergiremos en el mundo de la generación de terrenos tridimensionales utilizando GANs, explorando los avances más recientes, las técnicas aplicadas y los desafíos que enfrentamos. Nos enfocaremos en la generación procedimental de terrenos 3D, desde la creación de mapas de altura hasta la síntesis de imágenes de satélite, aprovechando arquitecturas avanzadas como ProGAN, CGAN y StyleGAN para alcanzar resultados de alta calidad y realismo visual.
Además, examinaremos de cerca cómo estas técnicas están siendo aplicadas en diferentes contextos, desde la industria del entretenimiento hasta la planificación urbana y la simulación ambiental. Al hacerlo, esperamos proporcionar una visión general de las posibilidades y los límites actuales en la generación de terrenos 3D mediante el uso de GANs.

Estado del Arte
Como hemos dicho en la introducción, vamos a adentrarnos en las Generative Adversarial Networks (GANs), y para ello, es fundamental entender el contexto y los avances recientes en el campo junto con sus operaciones y las diversas aplicaciones que ofrecen. El punto de inicio del uso de GANs para la generación de terrenos realistas se remonta a los primeros experimentos con GANs en el campo de la informática gráfica. Investigadores como Tero Karras, Samuli Laine y Timo Aila exploraron el potencial de las GANs para sintetizar paisajes naturales y urbanos con una alta fidelidad visual tras la introducción de estas por Ian GoodFellow en 2014. (Karras et al., 2017)
Uno de los desarrollos más notables en este ámbito es la arquitectura ProGAN, la cual ha demostrado una notable eficacia en la generación de terrenos realistas en entornos virtuales. Esta arquitectura, con su enfoque de entrenamiento progresivo, ofrece ventajas significativas sobre otras GANs para la generación de terrenos realistas. Al comenzar con imágenes de baja resolución y aumentar gradualmente la resolución, ProGAN logra un entrenamiento más estable, una mejor calidad de imagen, y una mayor capacidad para capturar detalles finos y texturas complejas. Además, su eficiencia computacional y técnicas de regularización mejoradas permiten generar imágenes de alta resolución de manera más efectiva, lo que es fundamental para aplicaciones prácticas en videojuegos, simulaciones de realidad virtual y visualizaciones geográficas.
Además, la comunidad investigadora ha explorado técnicas de regularización y entrenamiento adversarial más avanzadas para mejorar la calidad y la diversidad de los terrenos generados. La incorporación de mecanismos de atención ha permitido a las GANs enfocarse en características geográficas específicas, generando terrenos más realistas y coherentes, como puede llegar a ser BigGAN. Esta, es una versión escalable y eficiente de las GANs capaz de generar terrenos de alta calidad en una amplia variedad de escenarios geográficos. BigGAN utiliza un enfoque de atención ampliada para capturar detalles finos en los terrenos generados, lo que resulta en una mejora significativa en la calidad visual y la diversidad de los resultados.
Desarrollo
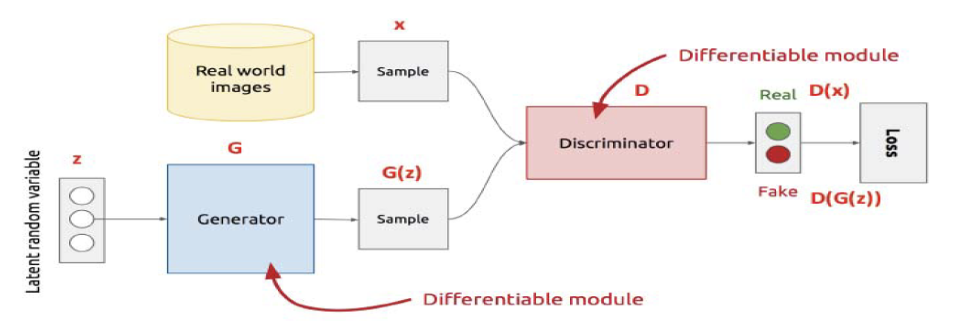
Las GANs, emplean una dinámica dual entre dos redes neuronales: el generador y el discriminador. El generador se encarga de producir datos ficticios que se asemejen a los datos reales, mientras que el discriminador se encarga de distinguir entre las muestras generadas y las auténticas. Ambas redes se entrenan a la vez en un juego competitivo, donde el generador intenta mejorar su capacidad para engañar al discriminador, mientras que este último busca mejorar su habilidad para detectar la falsedad. Este, es un proceso de constante confrontación y evolución, que nos lleva al siguiente nivel en la generación de datos realistas mediante la inteligencia artificial.
En el desarrollo de terrenos tridimensionales para entornos virtuales mediante el uso de GANs, el generador transforma vectores de un espacio latente aleatorio en representaciones realistas de paisajes en 3D. Por otro lado, el discriminador se entrena para diferenciar entre los modelos de terreno sintéticos y los obtenidos a partir de imágenes satelitales reales.
Estas técnicas facilitan la creación de entornos más ricos y variados, adecuados para simulaciones realistas y videojuegos de mundo abierto.

Materiales Usando ProGAN
Para comprender cómo funcionan las GANs y mejorar su entrenamiento, es esencial entender algunos conceptos matemáticos clave. Estos incluyen la optimización de una función de pérdida, como la divergencia de Kullback-Leibler o la pérdida de Wasserstein, que guía la interacción entre el generador y el discriminador.
En la implementación de las GANs, se establecen las arquitecturas de las redes, se elige la función de pérdida y se configuran los hiperparámetros. El objetivo principal es generar imágenes realistas, lo que se logra minimizando la función de pérdida adversarial.
Esta función de pérdida tiene en cuenta la estimación del discriminador sobre la probabilidad de que una instancia de datos real sea real (D(x)), así como la probabilidad de que una instancia falsa generada por el generador sea considerada real (D(G(z))). Se busca maximizar esta función de pérdida por parte del generador, mientras que el discriminador trata de minimizarla, lo que genera una competencia adversarial entre ambos.

En resumen, las GANs se basan en un juego competitivo entre dos redes neuronales, donde el generador intenta engañar al discriminador generando imágenes realistas, y el discriminador intenta distinguir entre imágenes reales y generadas. Este proceso de competencia y aprendizaje mutuo es fundamental para lograr la generación de imágenes de alta calidad.
Ahora presentamos una posible estructura para la implementación de una GAN usando ProGAN para la generación de terrenos realistas:

En esta imagen vemos una implementación básica de las funciones para construir el generador y el discriminador en una Progressive GAN (ProGAN) utilizando TensorFlow y Keras.
La función “build_generator_progan” construye el generador de la ProGAN. Para cada etapa de ProGAN (en este caso solamente para la etapa 4), se agregan las capas necesarias al modelo. En la etapa 4, se utiliza una capa densa seguida de capas de convolución transpuesta para generar una imagen de salida de tamaño 4x4x3 (para imágenes RGB). Luego, se devuelve el modelo construido.
La función “build_discriminator_progan” construye el discriminador de la ProGAN. Al igual que con el generador, se definen las capas del discriminador para cada etapa de ProGAN. En la etapa 4, se utilizan capas convolucionales seguidas de capas de activación LeakyReLU y de Dropout para clasificar la autenticidad de la imagen. Finalmente, se devuelve el modelo construido.

En esta imagen vemos otra parte del codigo de ProGAN en donde primero se definen las dimensiones del espacio latente y la etapa inicial. Luego, se define la función de pérdida adversarial y se compila el discriminador inicial. Posteriormente, se construye el generador y el discriminador iniciales para la etapa inicial de ProGAN. Después, se compila el discriminador ProGAN y se congela durante el entrenamiento del generador. Finalmente, se arma la GAN conectando el generador y el discriminador ProGAN, y se compila la GAN ProGAN.
Pruebas realizadas con ProGAN
Comenzamos generando imágenes con un conjunto de entrenamiento muy reducido (diez imágenes descargadas de distintos terrenos). Como es lógico, al ser una muestra tan reducida, en las imágenes generadas no se observan terrenos como tal, pero nos sirvió para confirmar que nuestro modelo era capaz de generar imágenes dadas unas muestras de entrenamiento. Se muestra el código con el que se cargaron las imágenes y dos salidas, cuyas diferencias se deben a pequeñas modificaciones en el generador y la función de entrenamiento.



Tras esto, decidimos probar con muestras mucho más grandes y representativas. Para la primera, creamos un proyecto en Google Earth Engine y tratamos de acceder a sus muestras.

Concretamente, probamos con la colección LANDSTAT, como se muestra en la imagen.

No obstante, las imágenes generadas aparecían en blanco. Tras investigar y probar con otra colección (Sentinel 2), vimos que el problema ocurría al cargar las imágenes, no en el entrenamiento, pues nos salían en blanco desde el principio. Se muestra la representación matricial.

Por ello, decidimos probar con EuroSAT.

Y, a diferencia de lo que sucedía con Google Earth, sí conseguimos cargar las imágenes.

No obstante, tras pasar las muestras al modelo, las imágenes generadas eran todas grises, lo que sugería un problema en el generador.

Realizando algunos cambios, lo máximo que conseguimos fue que se observara una ligera textura sobre el gris.

La última prueba, consistió en descargar un dataset de un repositorio GitHub.


Y, esta vez sí, logramos que el modelo generase algunas imágenes con cierta similitud con los terrenos. Es cierto que no se observan de forma clara y que en algunas el modelo se observa sobreajustado, pero creemos que si tuviéramos la capacidad de entrenar con un número mayor de muestras y ajustando el número de épocas y el tamaño del batch, podríamos lograr la generación de imágenes de terrenos. Además, vemos que algunas imágenes tienen una apariencia más detallada y definida, mientras que otras parecen más abstractas o ruidosas, lo que también es indicativo de que la consistencia del modelo tiene margen de mejora.
Por otro lado, como aspectos positivos, destacamos la variedad de patrones y colores, que indicaría que el modelo es capaz de producir diversidad en sus salidas, así como de texturas y formas, que indican que el modelo está capturando distintos tipos de características. Concluimos con que para la generación de terrenos realistas necesitamos varios miles de muestras para alcanzar los resultados que se esperarían, en vez de obtener imágenes abstractas de poca resolución.
Materiales Usando BigGAN
Para finalizar, hemos probado a implementar las BigGans, siguiendo el mismo patrón inicial que con las ProGANS.
La primera función construye un generador de imágenes para un modelo GAN utilizando Keras. Por otro lado, la segunda función construye un discriminador que evalúa si una imagen es real o generada. Utiliza Keras para definir un modelo secuencial que empieza con capas convolucionales, las cuales extraen características de la imagen de entrada. Este discriminador, por lo tanto, es responsable de distinguir entre imágenes reales y falsas y es entrenado en conjunto con el generador en un marco de aprendizaje adversarial.
Realizando algunas pruebas con este modelo con las mismas muestras que para ProGAN, no hemos obtenido mejores resultados. Esto puede deberse a la falta de muestras de entrenamiento o a que ProGAN se ajusta mejor a los parámetros de las muestras dadas.

Bibliografía
Anónimo. (2020, 1 junio). Redes Neuronales Generativas Adversarias (GANs). Brain4AI. Recuperado 12 de mayo de 2024, de
Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2017, 27 octubre). Progressive Growing of GANs for Improved Quality, Stability, and Variation. ArXiv.org. Recuperado el 12 de mayo de 2024, de https://arxiv.org/abs/1710.10196
Ward, J. (2021). This Landscape Does not Exist: Generating Realistic Landscape Imagery with StyleGAN2. Medium. Recuperado 27 de abril de 2024, de https://medium.com/geekculture/train-a-gan-and-keep-both-your-kidneys-bcf672e94e81