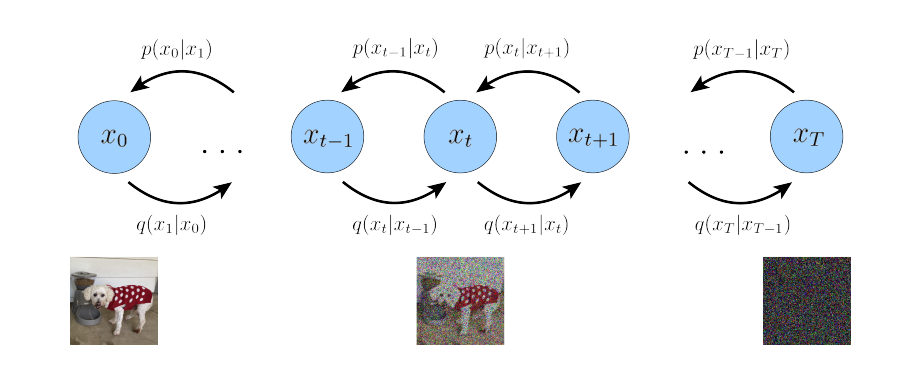
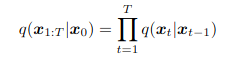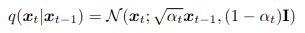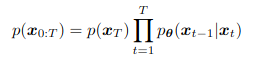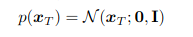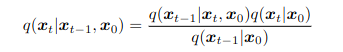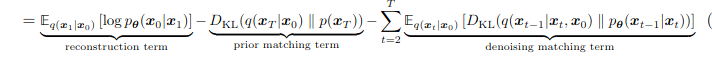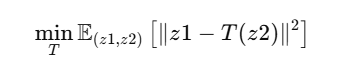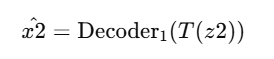INTRODUCCIÓN
El reconocimiento biométrico, una tecnología que identifica individuos mediante características biológicas, está en auge. Los modelos generativos, capaces de aprender y replicar datos, juegan un papel esencial en este campo. Estas técnicas avanzadas mejoran la precisión y seguridad de los sistemas biométricos al crear representaciones precisas de los rasgos biológicos. [1]
En este contexto, exploremos cómo los modelos generativos aumentan la eficacia y fiabilidad de los sistemas biométricos en diversas aplicaciones. A continuación, se presentan algunos de los objetivos comunes [2]:
Mejora de la precisión: Los modelos generativos capturan mejor las variaciones y características sutiles de los rasgos biométricos, lo que resulta en una identificación más confiable de individuos. Esto se traduce en una mayor precisión en el reconocimiento biométrico.
Incremento de la seguridad: Al generar representaciones biométricas más robustas y difíciles de falsificar, los modelos generativos fortalecen la seguridad de los sistemas biométricos. Esto reduce los riesgos de suplantación de identidad o manipulación fraudulenta.
Reducción de la dependencia de datos masivos: Los modelos generativos pueden aprender las distribuciones subyacentes de los datos biométricos y generar nuevas muestras. Esto disminuye la necesidad de grandes conjuntos de datos de entrenamiento, haciendo que los sistemas biométricos sean más eficientes y rentables.
Mejora de la privacidad: Estos modelos pueden generar representaciones biométricas que preservan la privacidad del individuo. Esto mitiga preocupaciones relacionadas con la privacidad y el uso indebido de datos biométricos, al mismo tiempo que permite un reconocimiento efectivo y seguro.
Estado del arte
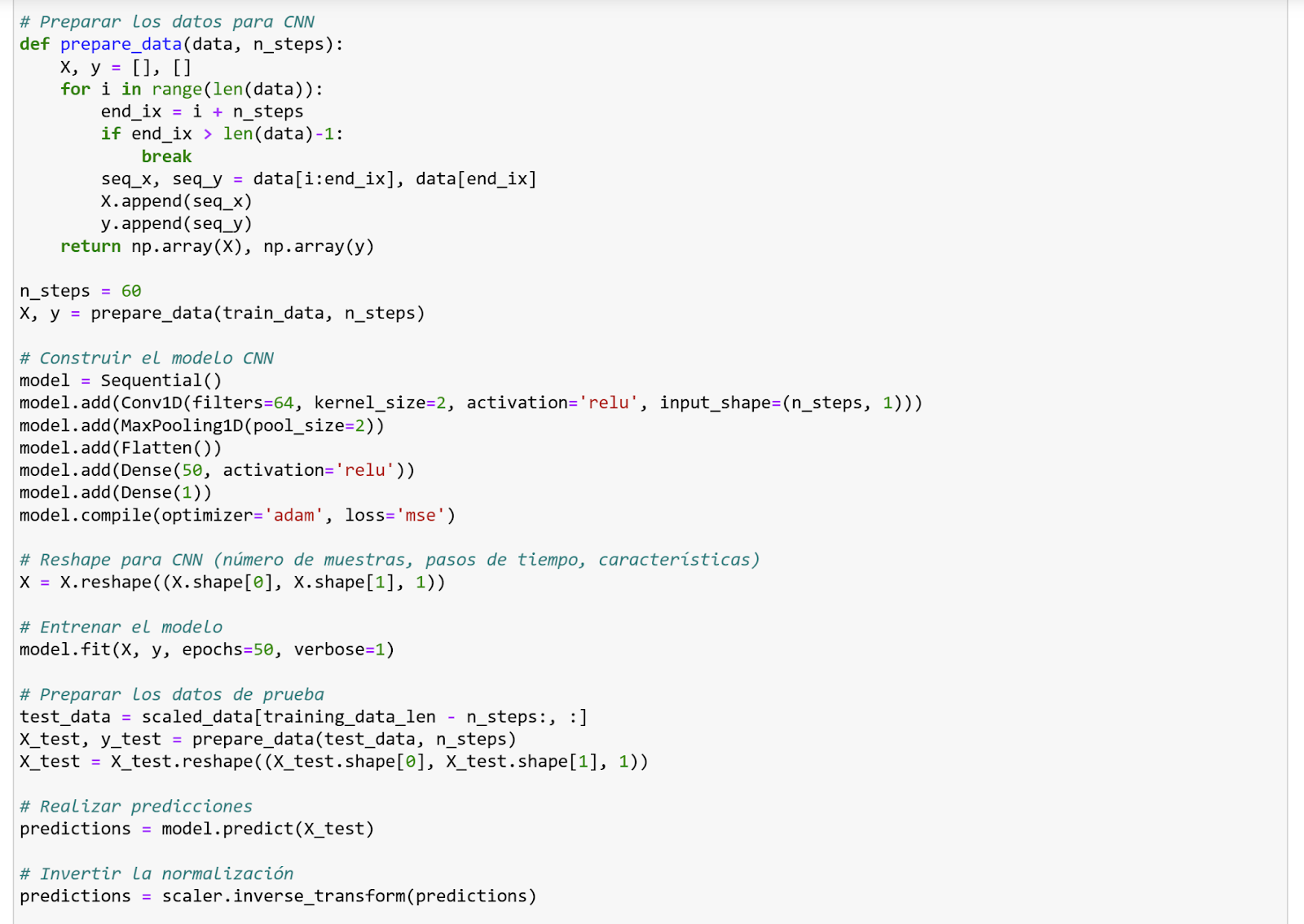
Para enfrentarnos a este problema, hemos decidido trabajar con las GAN y para ello primero debemos entender en qué consiste.
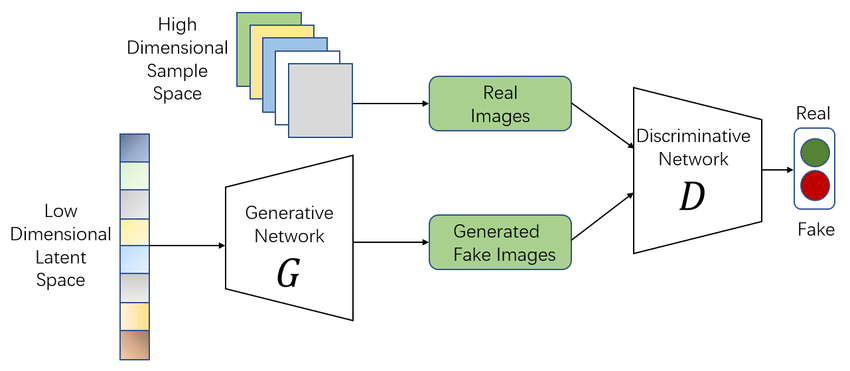
Las Redes Generativas Antagónicas (GANs, por sus siglas en inglés) son un tipo de modelo de aprendizaje automático introducido por Ian J. Goodfellow en 2014. Las GANs consisten en dos redes neuronales que compiten entre sí: una red generadora y una red discriminadora.
- Generador: Esta red toma una entrada de ruido aleatorio y genera datos que intentan imitar el conjunto de datos reales. Su objetivo es producir datos que sean indistinguibles de los datos reales.
- Discriminador: Esta red recibe tanto datos reales como los datos generados por la red generadora, y su tarea es distinguir entre ambos. Su objetivo es identificar correctamente si una entrada es real o generada. [3]
Estas se han usado con diferentes objetivos, incluyendo la generación de imágenes, videos, diseño de productos, aplicaciones médicas e incluso arte.
En nuestro caso práctico, nuestro objetivo es entrenar las GANs pasándole imágenes reales e imágenes corruptas de huellas dactilares para que aprenda a reconstruir la imágen corrupta y que se parezca lo máximo a la real. [4]
Las Redes Generativas Adversarias (GAN) han revolucionado la generación de imágenes, y su evolución ha dado lugar a técnicas cada vez más sofisticadas. Aquí podemos encontrar algunas de ellas.
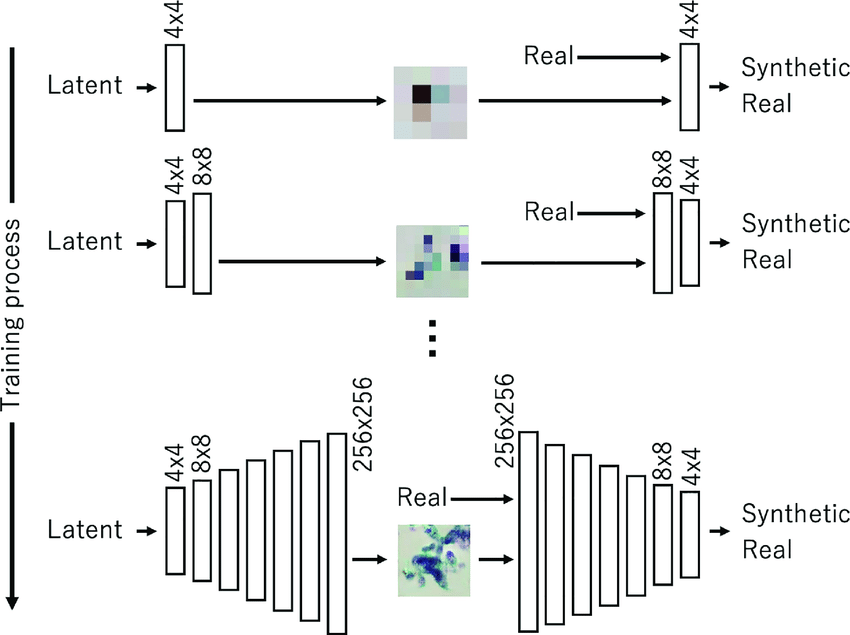
Progresive Growing GAN (PGGAN): Entrena el modelo en etapas, comenzando con imágenes de baja resolución y aumentando gradualmente la resolución para mejorar la estabilidad y la calidad de las imágenes generadas. [5]
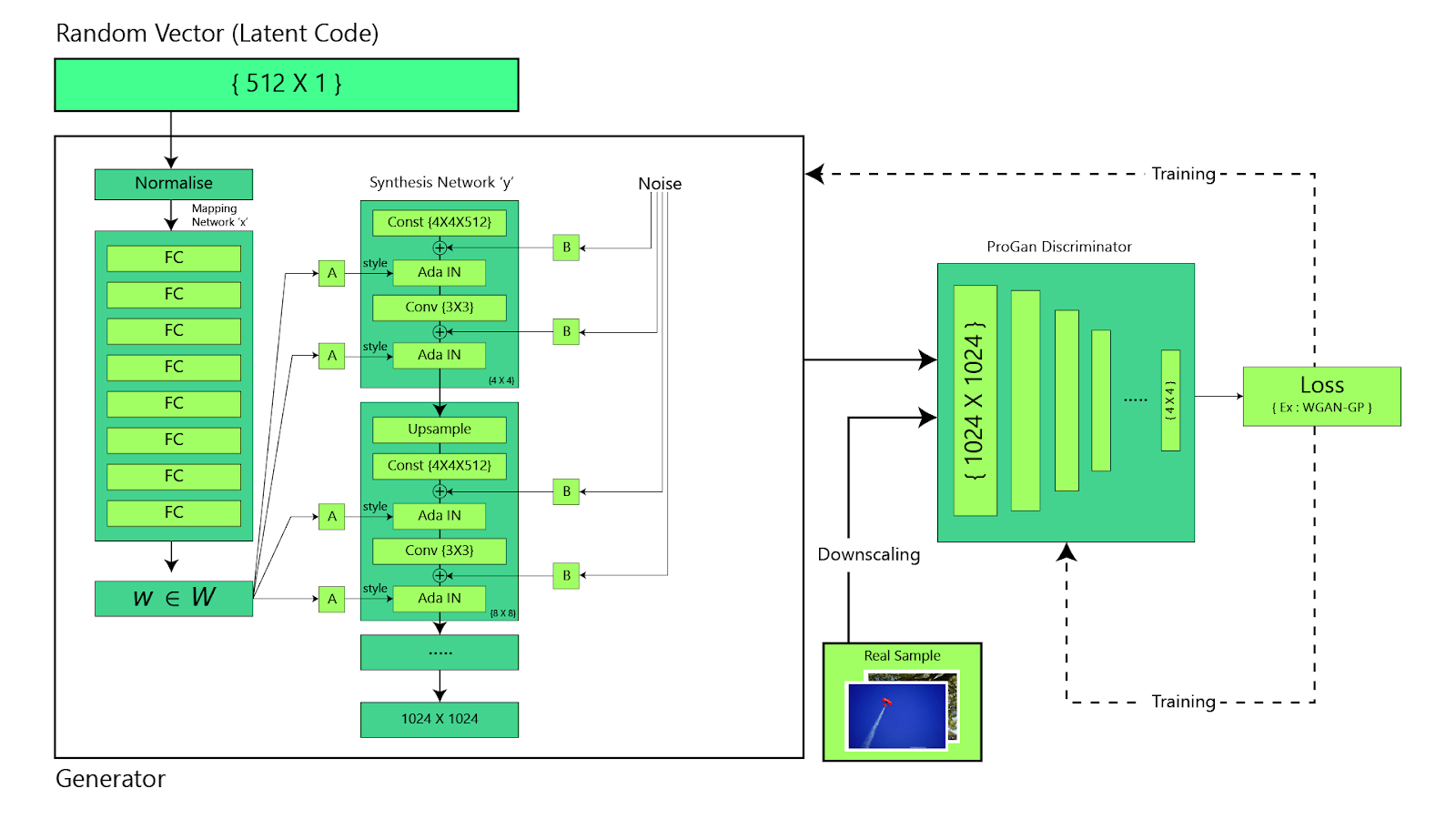
StyleGAN y StyleGAN2: Permiten controlar el estilo de las imágenes generadas y ofrecen un mayor grado de disentanglement (separación de características). [6]
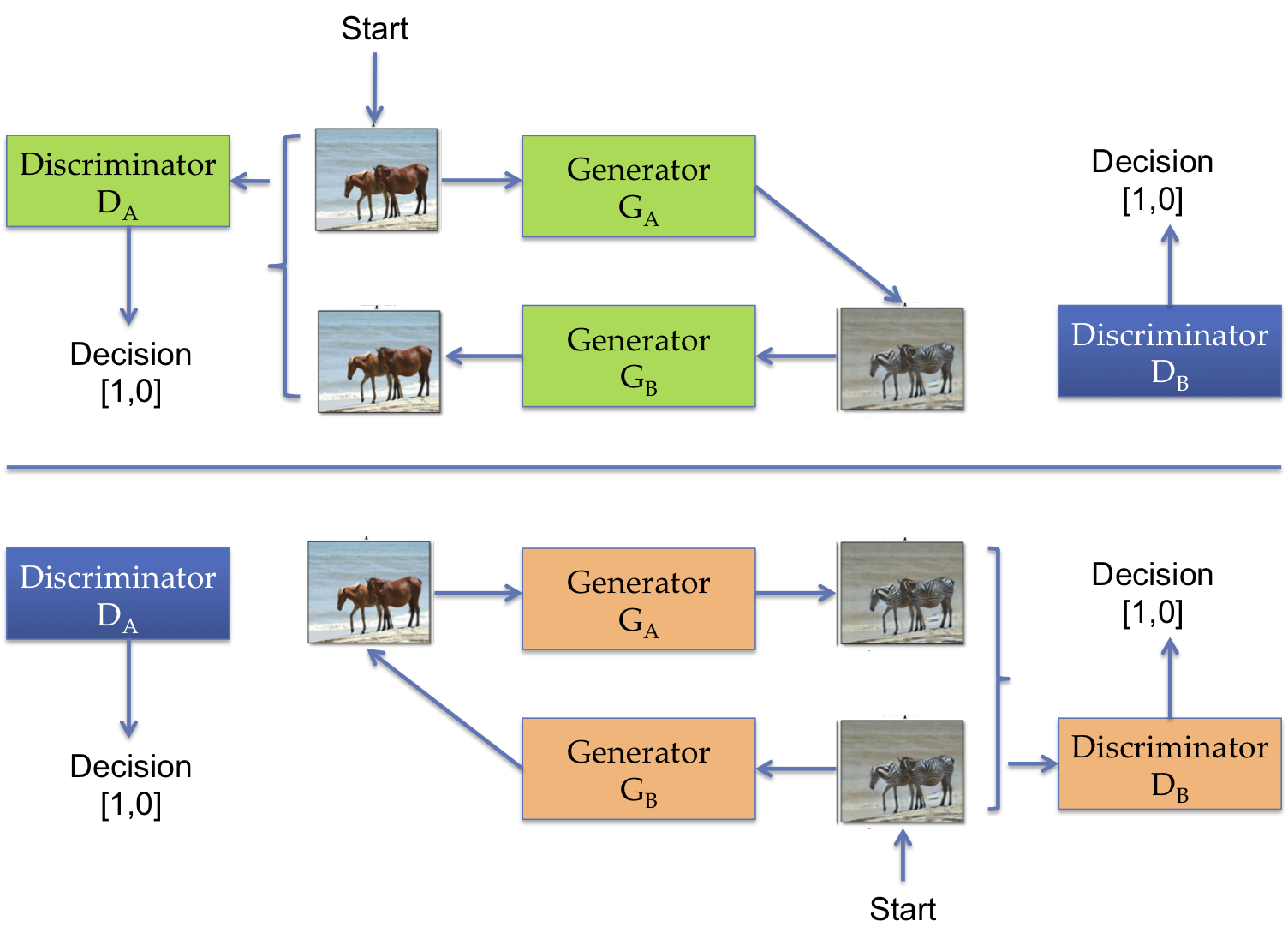
CycleGAN: Permite realizar traducciones de imagen a imagen sin necesidad de pares de imágenes emparejadas. [7]
Self-Attention GAN (SAGAN): Incorpora mecanismos de autoatención para mejorar la calidad de las imágenes generadas y capturar dependencias de largo alcance. [8]
Estas técnicas han permitido avances significativos en la calidad y diversidad de las representaciones generadas, y su impacto se ha sentido en múltiples campos. Por ejemplo, en la medicina, las GANs se utilizan para generar imágenes sintéticas que pueden mejorar los diagnósticos o entrenar modelos sin necesidad de grandes conjuntos de datos reales.

A pesar de investigar y posteriormente conocer sobre algunos avances más recientes y sofisticados en las GANs. Hemos decidido centrarnos en la arquitectura original de las GANs para nuestro proyecto. Creemos que comenzar con el modelo básico nos permitirá una comprensión más profunda de los fundamentos y principios subyacentes de estas.
Esta elección también se aliena mejor con nuestro objetivo de reconstruir imágenes corruptas de huellas dactilares, proporcionando una base sólida y bien estudiada sobre la cual construir nuestras futuras investigaciones y posibles mejoras.

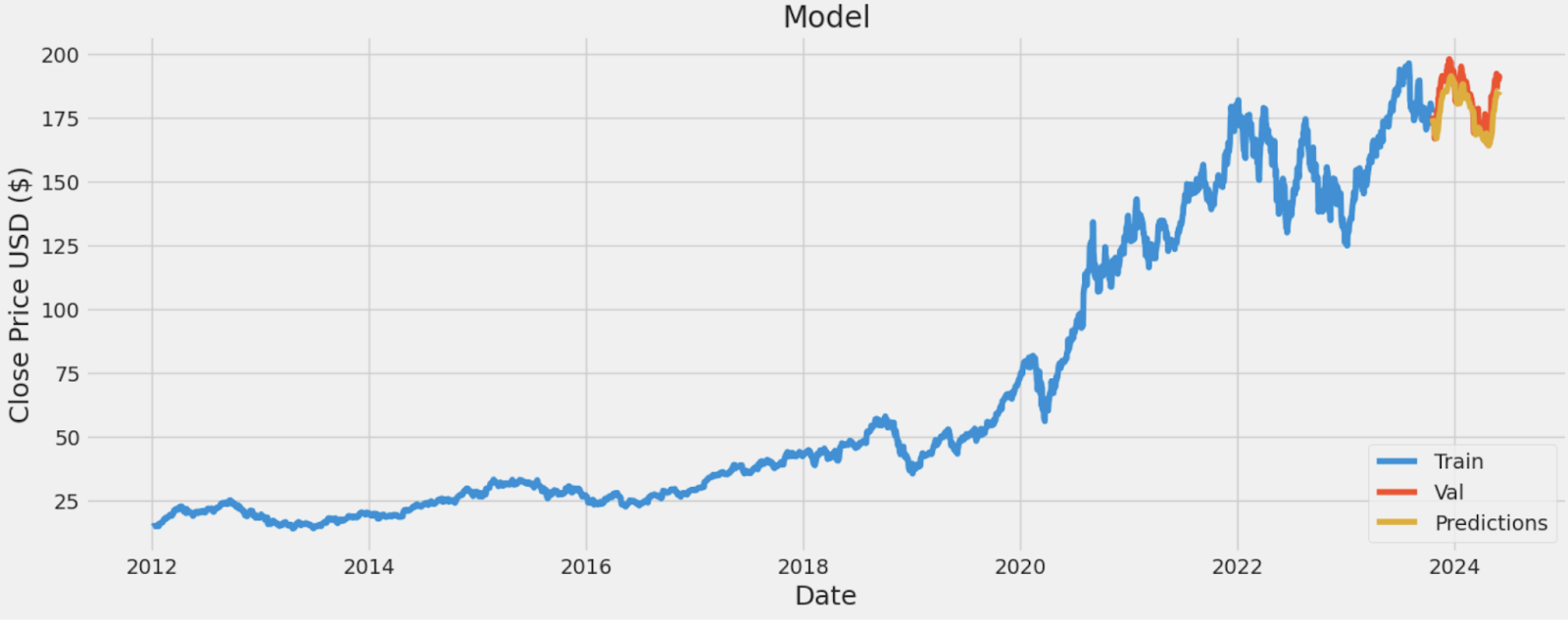
Para comprobar los resultados hemos usado las imágenes de entrenamiento.

En estas figuras podemos ver como si que hay imágenes que se reconstruyen bien (fila 1) pues no contienen mucho ruido y la reconstrucción se asemeja a la imagen real.
Sin embargo, tal y como hemos comentado antes, las imágenes que contienen ruido en partes clave de la huella son complicadas de reconstruir y los resultados son huellas que contienen fallos importantes y que impedirían un posible reconocimiento.
Después de entrenarlas, lo que haremos será generar nuestras propias imágenes con una GAN (todavía por hacer) para que ‘demuestre’ lo aprendido y que veamos cómo de bien reconstruye nuestras imágenes generadas.
Desarrollo
Nosotros nos vamos a centrar en un único patrón biométrico que consideramos bastante importante, las huellas dactilares.
Hemos analizado diversos notebooks que hemos encontrado y que nos han parecido interesantes.
En el primero( https://github.com/denkovarik/Fingerprint) se utilizan GANs
para reconstruir imágenes de baja calidad de huellas dactilares. Podemos ver que los resultados no llegan a ser muy satisfactorios, sobretodo en aquellas imágenes en las que no están bien definidas las zonas centrales, que presentan patrones más complejos.
En el segundo (https://www.kaggle.com/code/dijorajsenroy/fingerprint-feature-extraction-for-biometrics) se explica y analiza cuales son las características que se extraen de las huellas dactilares para que estas puedan ser reconocidas y diferenciadas.
Preparación de Datos:
- Se recopilan imágenes de huellas dactilares, tanto de alta calidad como de baja calidad o corruptas.
- Las imágenes se preprocesan para limpiarlas, eliminar ruido y normalizarlas.
- Se pueden aplicar técnicas de aumento de datos para crear variaciones artificiales de las huellas existentes, enriqueciendo así el conjunto de datos.
- Las imágenes se dividen en conjuntos de entrenamiento y validación.
Generación de huellas:
Para generar las huellas sobre las que vamos a trabajar, vamos a utilizar el programa Anguli: https://dsl.cds.iisc.ac.in/projects/Anguli/ que es un proyecto desarrollado por el Instituto Indio de Ciencias que permite generar huellas dactilares sintéticas en C++ a partir de datasets privados. Este problema es capaz de generar también las huellas con distintos tipos de ruidos.
En nuestro caso vamos a generar 100 huellas con sus respectivas correspondencias con ruido. Para el ruido hemos definido su nivel entre 0 y 10 y para los scratches también entre 0-10.
Los parámetros que definimos son:
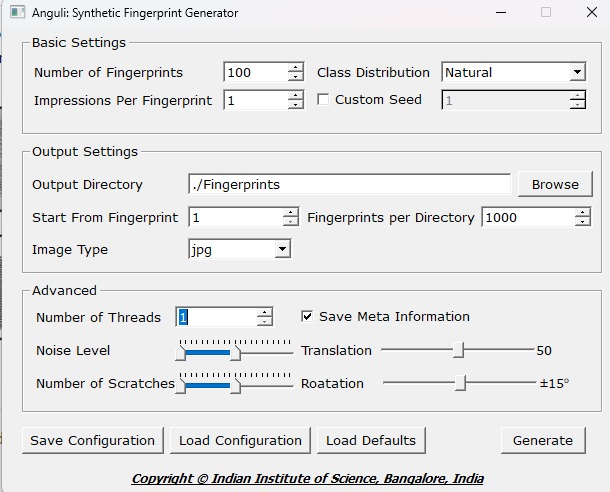
Y nos genera una serie de carpetas con las huellas.

Diseño de la Arquitectura GAN:
- Se define la estructura del generador, que tomará como entrada una huella dactilar de baja calidad y generará una versión mejorada.
- Se define la estructura del discriminador, que recibirá tanto huellas dactilares reales como generadas y aprenderá a distinguir entre ellas.


Entrenamiento del Modelo GAN:
- El generador y el discriminador se entrenan de forma iterativa y competitiva.
- El generador intenta crear huellas dactilares falsas cada vez más realistas para engañar al discriminador.
- El discriminador se esfuerza por mejorar su capacidad para distinguir entre huellas reales y falsas.
- Este proceso continúa hasta que el generador produce huellas dactilares que son prácticamente indistinguibles de las reales.



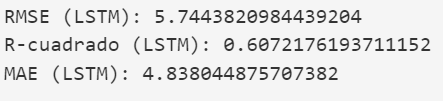
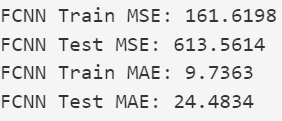
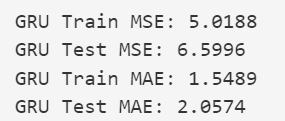
Evaluación y Validación:
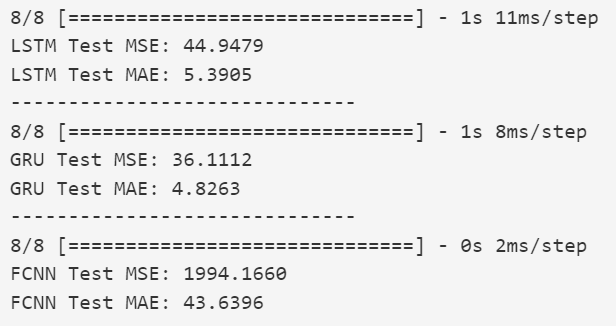
- Se evalúa el rendimiento del modelo utilizando métricas como la precisión, el recall y el F1-score en un conjunto de datos de prueba independiente.
- Se realizan pruebas de robustez para evaluar cómo el modelo maneja huellas dactilares borrosas, incompletas o con ruido.
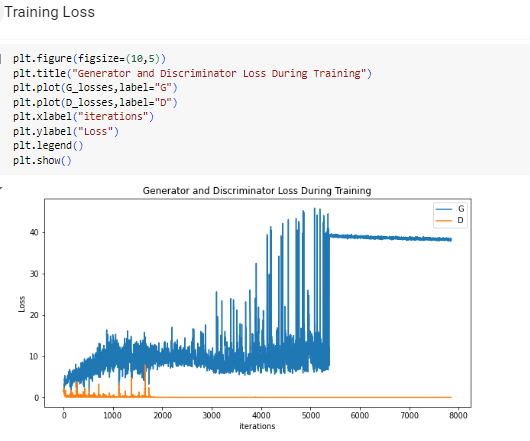
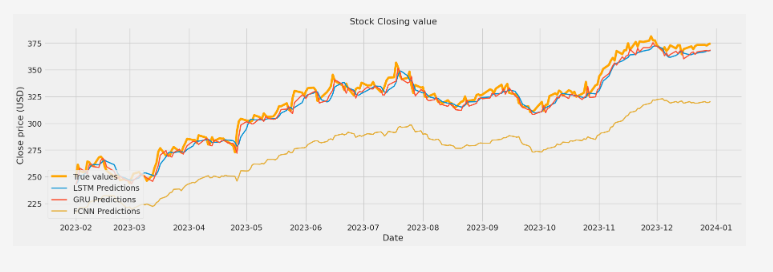
- La gráfica muestra la evolución de las funciones de pérdida del generador y el discriminador durante el entrenamiento de una Red Generativa Antagónica (GAN).
- El entrenamiento parece haber sido exitoso en general, ya que ambos modelos han alcanzado un equilibrio y el generador produce muestras realistas. Sin embargo, el posible sobreajuste del generador es algo que se debería investigar más a fondo.
Extracción de las características de las huellas:
Después de generar las imágenes de huellas, utilizamos técnicas avanzadas de procesamiento de imágenes para extraer características distintivas de las huellas.
Sabemos que no es un modelo generativo pero nos servirá para hacernos una idea de cómo se extraen.
Mostramos imágenes aleatorias a partir de datos:

Transformamos las imágenes implementando un suavizado a las imágenes y que detecte bordes.

Además, realizamos la umbralización de huellas dactilares utilizando el valor medio de intensidad de pixeles como umbral.

Y extrae características como terminación, bifurcación y minucias de las huellas dactilares.



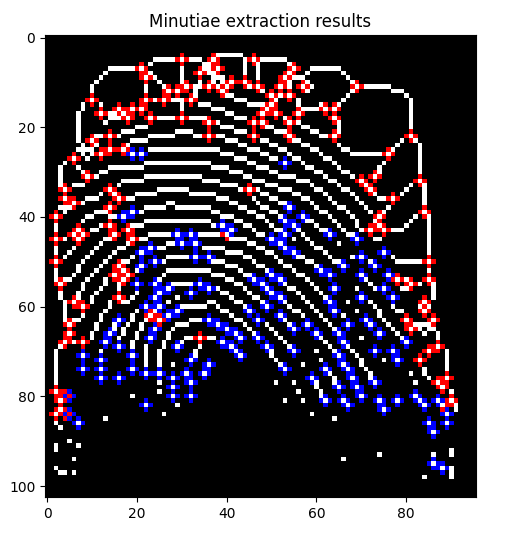
Aquí es fundamental la extracción precisa de estas características para la identificación biométrica, ya que permite comparar y verificar identidades de manera eficaz.
Combinando ambos códigos se podrían cuantificar la diferencia de las características entre las huellas reconstruidas y las reales y asi podriamos ver la eficacia del modelo de generación.
Consideraciones Éticas y de Privacidad:
- Se garantiza que los datos biométricos se recopilen y utilicen de manera ética y responsable, respetando la privacidad de los individuos.
- Se abordan posibles sesgos en los datos y en el modelo para asegurar la equidad en el uso de la tecnología.
El trabajo se encuentra desarrollado en el notebook llamado “CodigoPASD.ipynb”.
Referencias
- https://www.biometricupdate.com/202403/financial-fraud-is-exploding-fueled-by-cheap-and-easy-generative-ai-tools
- https://www.sciencedirect.com/science/article/pii/S0952197623018961
- https://www.iic.uam.es/innovacion/generacion-imagenes-tecnicas-basadas-gans/
- https://www.researchgate.net/publication/373551906_Ten_Years_of_Generative_Adversarial_Nets_GANs_A_survey_of_the_state-of-the-art
- https://arxiv.org/abs/1710.10196
- https://arxiv.org/abs/1812.04948
- https://arxiv.org/abs/1703.10593
- https://arxiv.org/abs/1805.08318
- https://github.com/denkovarik/Fingerprint
- https://www.kaggle.com/code/dijorajsenroy/fingerprint-feature-extraction-for-biometrics