Spoken Language Understanding
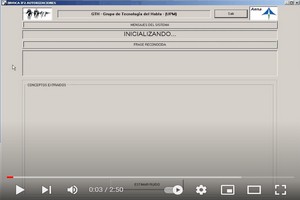 |
The INVOCA project was funded by AENA. INVOCA had as the main objective of analyzing the possibilities offered by the state of the art in speech recognition technologies for their application to air traffic control systems. It is therefore a project of technological exploration and evaluation. The functionality of the developed system is the detection of key data in the ground-air channels through which the controller-pilot communications take place. These are based on spontaneous speech and respond to an official phraseology applicable to all tower control positions. They can be produced in both English and Spanish, so we are dealing with a multi-language system. |
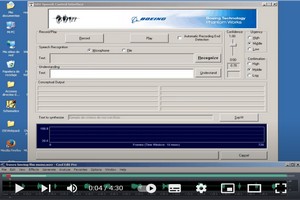 |
This video presents a speech control interface developed as a result of the collaboration between the GTH (Grupo de Tecnología del Habla or Speech Technology Group) at Universidad Politécnica de Madrid (UPM) and the company Boeing Research and Technology Europe. Several speech technology improvements for increasing robustness, reliability and ergonomics in speech interfaces for controlling aerial vehicles are introduced. These improvements consist of including a statistical language model for increasing the robustness against spontaneous speech, incorporating confidence measures for evaluating the performance of on-line the speech engines (better reliability), and a flexible response generation for improving the interface ergonomics. |
Emotional Spoken Dialogue Systems
 |
This demo presents a spoken dialogue system including speech recognition and understanding, speech synthesis and dialogue modeling technologies. This system is able to consider different emotional states and emotional speech synthesis adapting its behavior to the conversation success. |
Text to Speech Conversion
 |
This demo presents an example of the voice generated during Simple4ALL european project. This voice is able to reproduce a soccer game announcer. |
Audio Segmentation
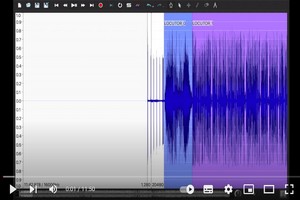 |
Speaker diarization is the task of identifying the number of participants in a meeting and creating a list of speech time intervals for each participant. Speaker diarization can be used as a first step in the speech transcription of meetings in which each sentence has to be associated with a specific speaker. The diarization task is carried out without any previous knowledge about the position, number or characteristics of the speakers, the position or quality of the microphones used during the meeting or the characteristics of the room where the recording has taken place. The video presents a demonstration of one of the automatic speaker diarization systems developed at GTH labs. |
 |
AMIC aims to progress a set of diverse technologies and use them to deal with affective analysis on multimedia documents and affect-aware person-computer interactive systems. We are committed to contribute to an improved study on all kind of sources of information including traditional broadcast media and new massive and heterogeneous social media. We aim at proposing novel technological solutions to support a comprehensive information extraction of multimedia sources that includes audio, image, speech and language technologies devoted to multimedia information extraction and processing, affect aware Multimedia Analytics and natural, affective and inclusive communication. |
Video and image processing
 |
The video shows a mosaic-like composition in which both the original videos recorded by means of a mobile phone camera on board a car and the result of processing said videos can be viewed by applying the Enet model for semantic segmentation trained on the Cityscapes database (https://www.cityscapes-dataset.com/) , and automatically coloring the different regions within the video according to the result of the segmentation. |
 |
Object recognition demo with deep learning using MobileNetSSD, a compact 25MB model specifically developed for HW platforms with limited resources (e.g. mobile) on Raspi optimized for almost 1 frame per second. |
 |
(Video in Spanish) ESITUR-UPM: Interactive Tourist Showcase. Accessible from any mobile (without application) and with content extracted from analyzing and interpreting public photos uploaded to social networks by tourists visiting the same area. ESITUR is a project carried out in collaboration with Universidad Carlos III de Madrid and the company MOVILOK INTERACTIVIDAD MOBILE Awarded in the 2016 Call for Collaboration Challenges of the Ministry of Economy and Competitiveness, the project is aimed at the design and development of ‘smart tourism’ solutions that improve the tourist experience of its users during their stay at the destination. |  |
(Video in Spanish) ESITUR-UPM Promotional video. This video shows a real application using the tehcnologies developed in the ESITUR-UPM project. |  |
This video shows a tracking demo where the system localizes a marker and followes its movement. |
 |
Demonstration video of a system for recognizing emotions (i.e., happy, sad, surprised…) using MediaPipe FaceMesh, based on a Raspberry Pi 3B+ platform. Emotion classification is performed processing raw images are captured and obtaining specific points from the user’s face. These landmarks are fed into a convolutional neural network that determines the emotion class from the images. |
Spoken Language Translation
 |
This video shows two translation modules: the first one translates spoken Spanish into Sign Language (Spanish Sign Language) that the signs are represented by an animated avatar. A second module is able to generate Spanish speech from sign language sentences represented in GLOSSES. These sentences can be specified by an advanced interface adapted to this language. Although the explanation is in Spanish, it is possible to see the behaviour of both modules. |
Human Motion
 |
This video corresponds to a presentation in which Manuel Gil offers an overview of the applications of human movement modeling such as the recognition of gestures or physical activities or the early diagnosis of neurodegenerative diseases such as Parkinson’s. |
 |
This video shows a Raspberry Pi 3B+ running our Sign Language Recognition system to convert your signed letters into readable text. The system leverages the Raspberry Pi’s processing power to run the MediaPipe and TensorFlow Lite models, enabling real-time sign language recognition on the device. |
 |
Demonstration video of a system for recognizing ping-pong gestures (i.e., drive, backhand, lob, and serve) using inertial sensors, based on a Raspberry Pi 3B+ platform. Gesture classification is performed with 4-second windows (with a 1-second shift between consecutive windows) during which raw accelerations are captured for the x, y, and z axes (sampling frequency of 50 Hz). These accelerations are fed into a recurrent neural network model (LSTM) that determines the gesture class for each window based on the recorded motion. |
Natural Language Processing
 |
Demonstration video in which the operation and capabilities of the Sentiment Analysis system deployed on the occasion of the project “DEVELOPMENT OF A MODULE FOR THE ASSESSMENT OF THE QUALITY OF DIALOGUE WITH CONVERSATIONAL AGENTS” can be verified. The model has been developed for El Corte Inglés S.A. by researchers from the Universidad Carlos III de Madrid, universidad de Granada y Universidad Politécnica de Madrid. The demonstration includes both phrases typical of the COAR domain on which the model is trained (phrases related to opinions about hotels and restaurants), as well as other phrases of a more general nature.. |
Human-Robot Interaction
 |
This video is a demonstration of the different capabilities implemented in URBANO. URBANO is a robot that includes a spoken dialogue system for interacting with with the visitors in a Science Museum, providing interactive guided tours. Our main purpose was to provide the robot with some features towards the generation of more human-like interaction. These features are gestual expressivity and emotional speech synthesis. |
 |
This video demonstrates the dialogue capabilities, including speech recognition and synthesis. |