
Have you ever wondered what makes some videos so unforgettable? What if we could create AI that understands and predicts a video's memorability? Our brand new paper "Parameter-Efficient Adaptation of Large Vision-Language Models for Video Memorability Prediction" by Martín-Fernández et al. (2025) introduces a novel approach to predicting video memorability using the QLoRA technique to fine-tune the Qwen-VL model. This method achieves a state-of-the-art Spearman Rank Correlation Coefficient (SRCC) of 0.744 on the Memento10k dataset, demonstrating the effectiveness of leveraging generalist multimodal pre-training in specialized domains.



Research

Automatic Speech Recognition

Speaker Identification / Diarization
Language Recognition

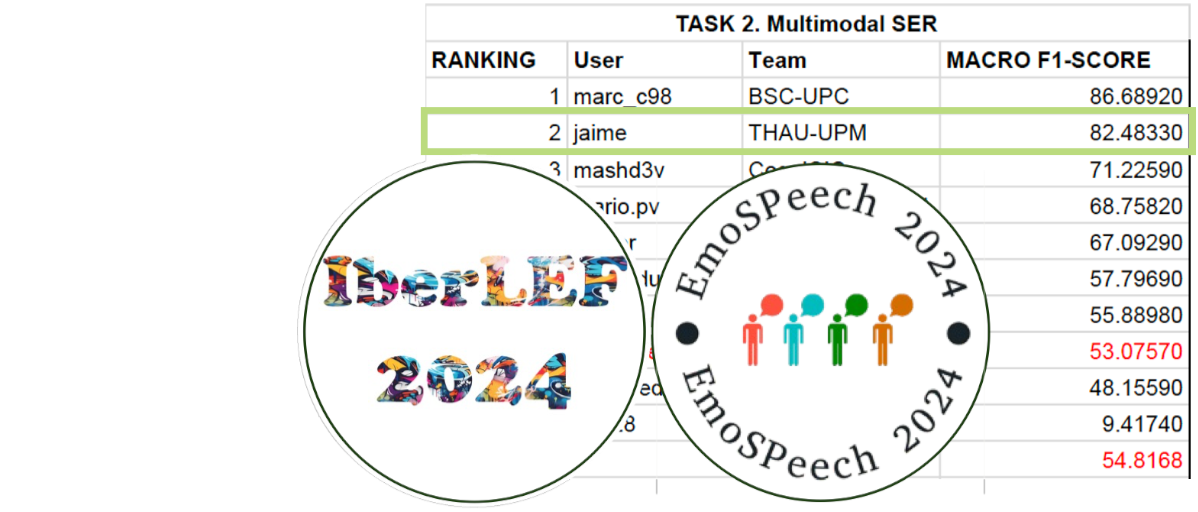
Multimodal Emotion Recognition

Machine Translation

Keyword Spotting
Natural Language Understanding
Intent Detection

Spoken Dialog Systems

Conversational Agents (chatbots)
Text-To-Speech Synthesis
Topic identification

Text Generation

Trustworthiness Assessment
Wearable Sensing
Multimedia Information Retrieval
Image and Video Processing
Scene Understanding
Multimedia Content Perception

Human Motion Modeling

