INTRODUCCIÓN
La seguridad en las calles urbanas es un desafío importante en las grandes ciudades, donde el alto volumen de vehículos y la diversidad de transporte aumentan el riesgo de accidentes. Madrid enfrenta retos significativos en este aspecto al ser una gran ciudad.
Analizar los datos históricos de accidentes de tráfico nos ayuda a identificar patrones y factores clave, así como detectar las áreas con mayor frecuencia de accidentes.
ESTADO DEL ARTE
En los últimos años, se han realizado varios estudios para mejorar la seguridad vial en entornos urbanos, analizando patrones de accidentes. Estos enfoques han sido útiles en ciudades como Madrid, donde debido a su actividad, se requieren métodos avanzados para analizar situaciones, tomar decisiones útiles y así, intentar evitar siniestros.
Un trabajo destacado en este campo es el proyecto de Mario de los Santos (2018). Analizó las incidencias de tráfico en Madrid entre 2010 y 2018; identificando las áreas con más accidentes, destacando la importancia de factores temporales (día y hora) y espaciales (zona y distrito). Esta ha sido la base de nuestro estudio.
DESARROLLO
En el desarrollo de nuestro proyecto, nos hemos centrado en el análisis de las Incidencias de Tráfico en Madrid, basándonos en el código proporcionado por Mario de los Santos [2], hemos ampliado los datos hasta 2024 e incorporado nuevas técnicas de análisis. Hemos realizado un análisis descriptivo y visual, así como una estimación de la probabilidad de accidentes según diversas variables.
Los datos fueron extraídos del Portal de Datos Abiertos del Ayuntamiento de Madrid, desde 2010 a 2024 [1]. Es importante destacar que los datos entre 2010 y 2018 presentan un formato diferente al de los años posteriores. Para poder analizarlos conjuntamente, fue necesario realizar un preprocesamiento específico.
Una vez estandarizado el dataset, unificamos toda la información en un único archivo .csv, que se convirtió en la base para los análisis posteriores.
A continuación, desarrollamos varias celdas de código en Python [2], para analizar las tendencias y patrones en los accidentes. Esto nos permite entender mejor los datos y facilitar la interpretación de las predicciones. Para ello, utilizamos gráficos y visualizaciones con la librería matplotlib.
Además del análisis descriptivo, implementamos un programa calculador de riesgo en Python. Este modelo permite estimar el riesgo de realizar un recorrido específico introduciendo ciertos parámetros (distrito, día de la semana, tipo de vehículo y tipo de persona implicada). El cálculo del riesgo se realiza mediante un modelo de regresión lineal no regularizada, lo que nos permite estimar de manera aproximada la peligrosidad de realizar dicho trayecto.
MATERIALES
Para hacer este estudio nos hemos basado en los accidentes de tráfico en la Ciudad de Madrid registrados por la Policía Municipal, los cuales se hacen cuando hay víctimas o daños al patrimonio [1]. Para resolver el problema de la diferencia estructural de los datos, hemos establecido las columnas comunes de los dos tipos de CSV y posteriormente hemos procesado y estandarizado los datos. Entre otras cosas hemos renombrado columnas, eliminado aquellas irrelevantes en nuestro análisis, hemos unificado en categorías, convertido a formato datatime… (adjuntamos parte del código)
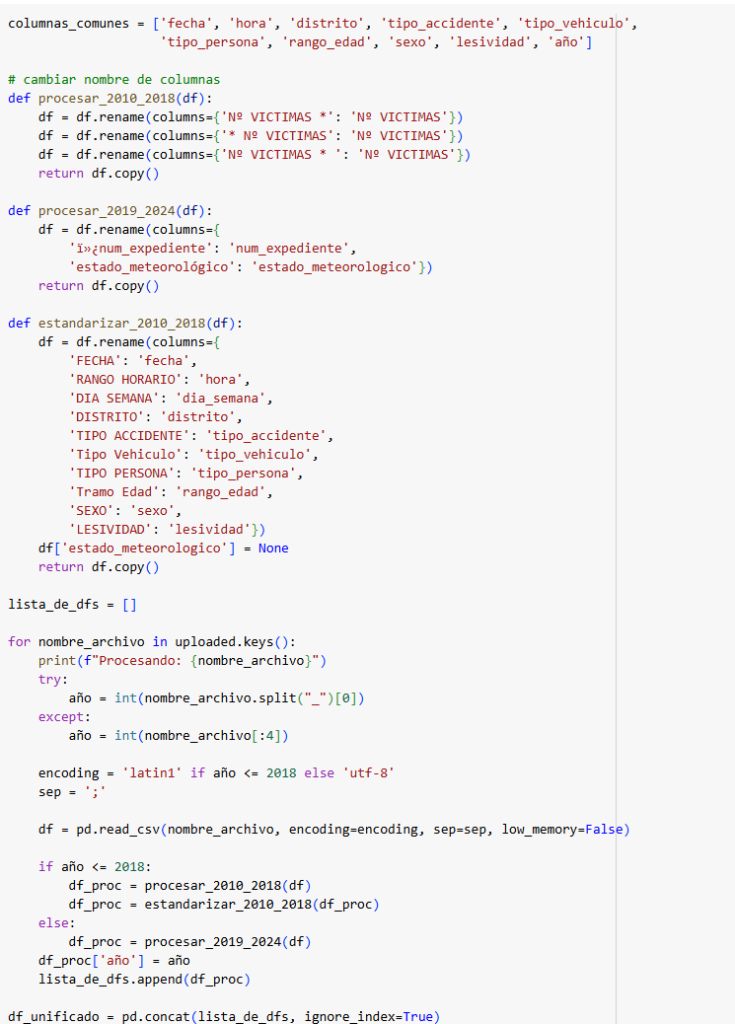

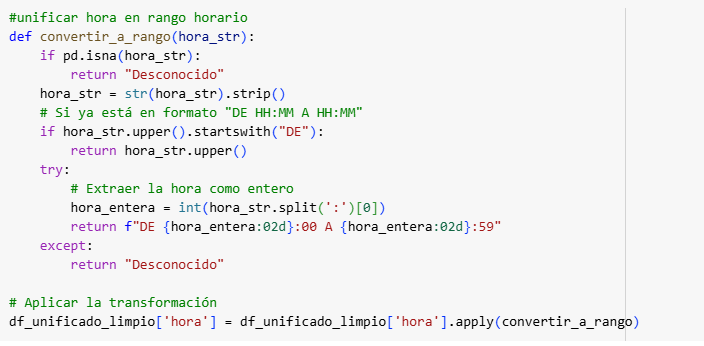
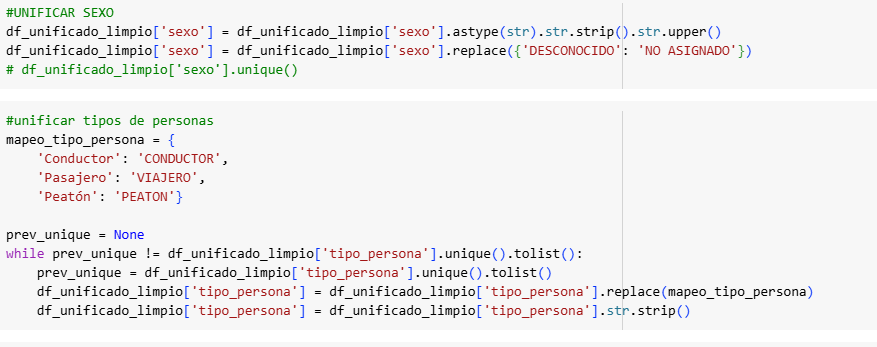
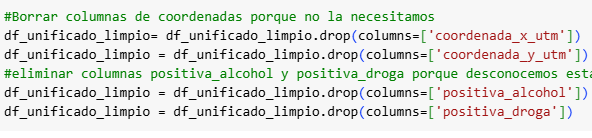
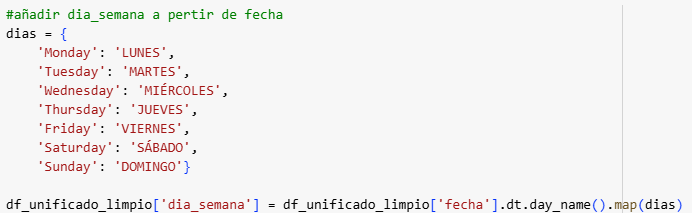

Tras estos pasos, nos han quedado las siguientes columnas clave:
- Fecha en formato aaaa/mm/dd.
- Rango horario: la hora se establece en intervalos de 1 hora.
- Día de la Semana: de lunes a domingo.
- Distrito por nombre.
- Localización: calle o cruce de calles.
- Número: Número de la calle.
- Nº Parte: Número del parte de accidente.
- Estado meteorológico: Condiciones ambientales (granizo, hielo, lluvia, niebla, nublado, despejado o nieve).
- Tipo de accidente: colisión doble, colisión múltiple, colisión fronto-lateral, choque contra obstáculo fijo, atropello a animal, atropello a persona, vuelco, caída, salida de la vía, o alcance.
- Tipo de vehículo: turismo, motocicleta, furgoneta, camión, ambulancia, bicicleta, ciclomotor o autocar.
- Tipo de persona: conductor, peatón, testigo o viajero.
- Sexo: hombre, mujer o no asigando.
- Lesividad: Herido leve (HL), herido grave (HG), sin asistencia sanitaria (IL), se desconoce, o muerto (MT).
- Tramo de edad de la persona implicada.
- Año: año en el que se produjo el accidente.
- Sexo de la persona implicada en el accidente.
RESULTADOS
A continuación, mostramos los principales resultados obtenidos a partir del análisis de los datos:
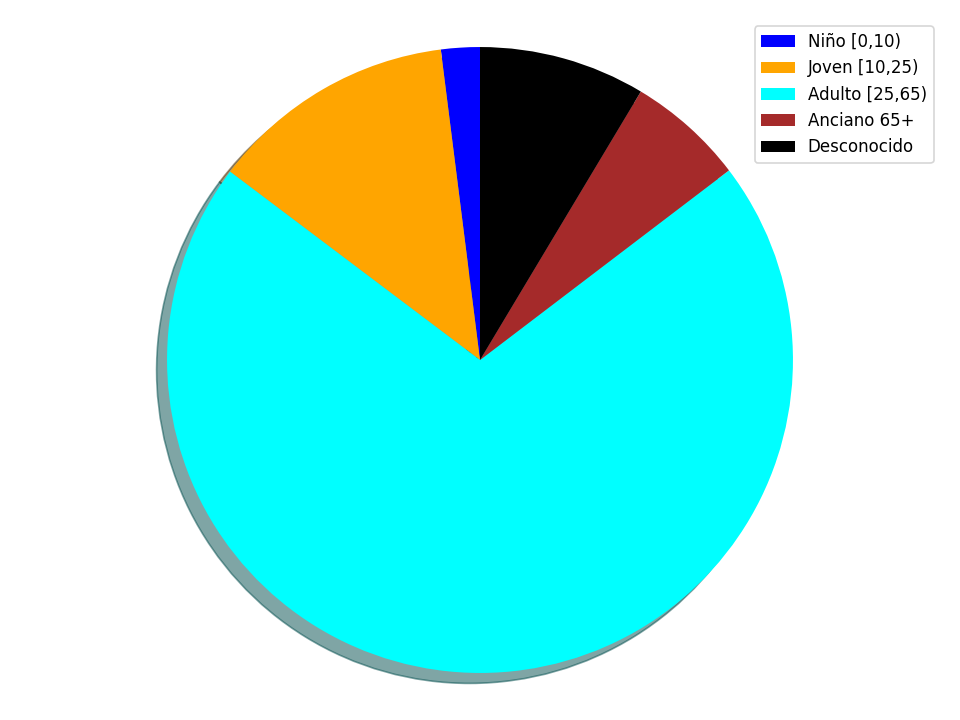
Distribución de accidentes respecto a edades de los afectados: Como es lógico, obtenemos que el rango de edad más afectado son los adultos entre 25 y 65 años, pues suelen ser quienes conducen.
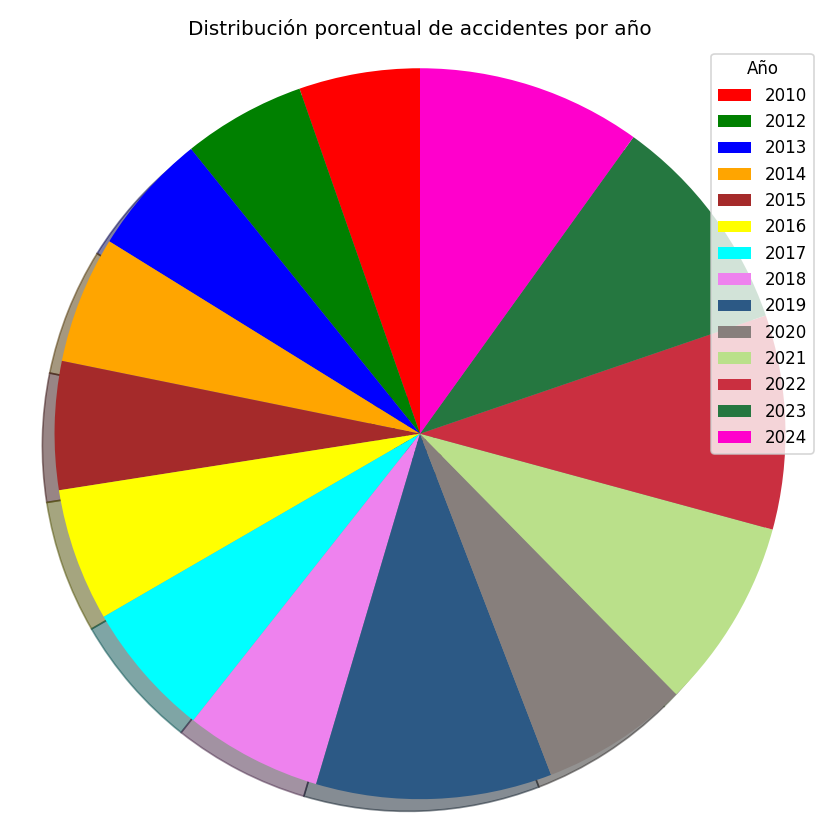
Distribución de accidentes respecto al año. A medida que pasan los años, observamos un aumento en el número de accidentes anuales. Sin embargo, en el año 2020 hay una clara disminución debido a la pandemia.
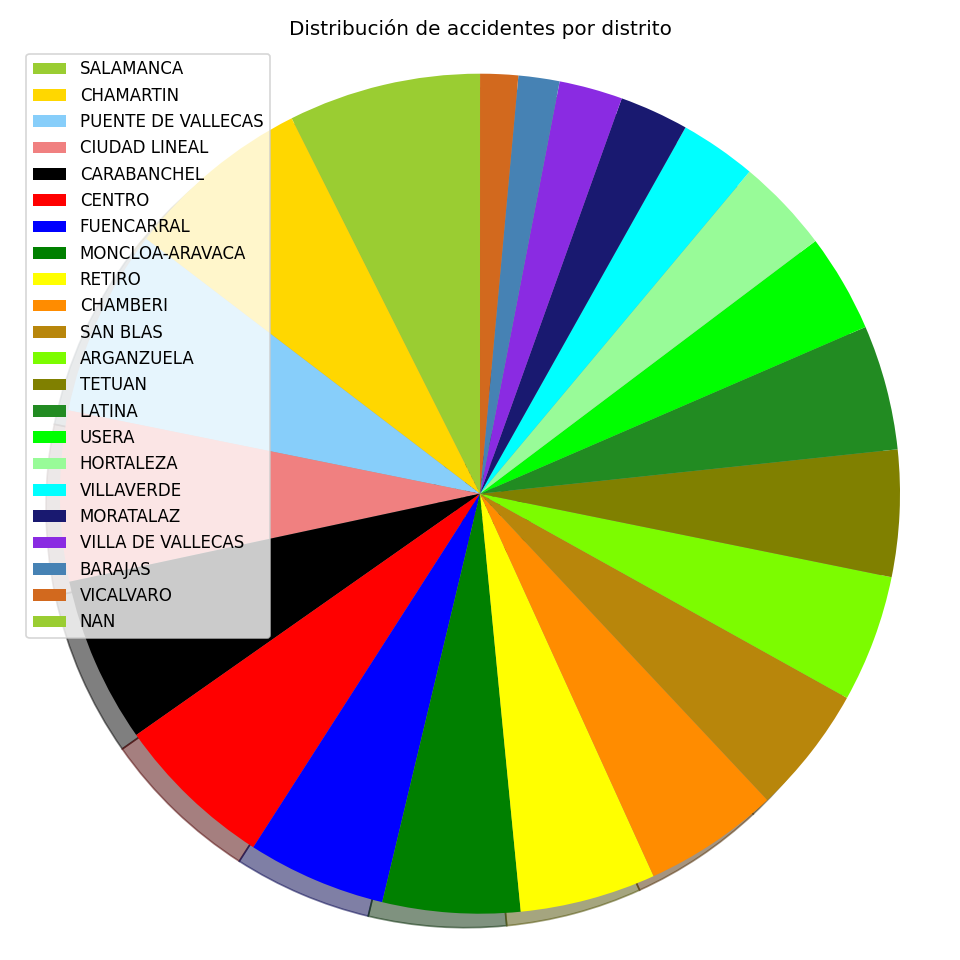
Distribución de accidentes respecto al distrito donde tuvo lugar, siendo el distrito donde se producen más accidentes Salamanca.
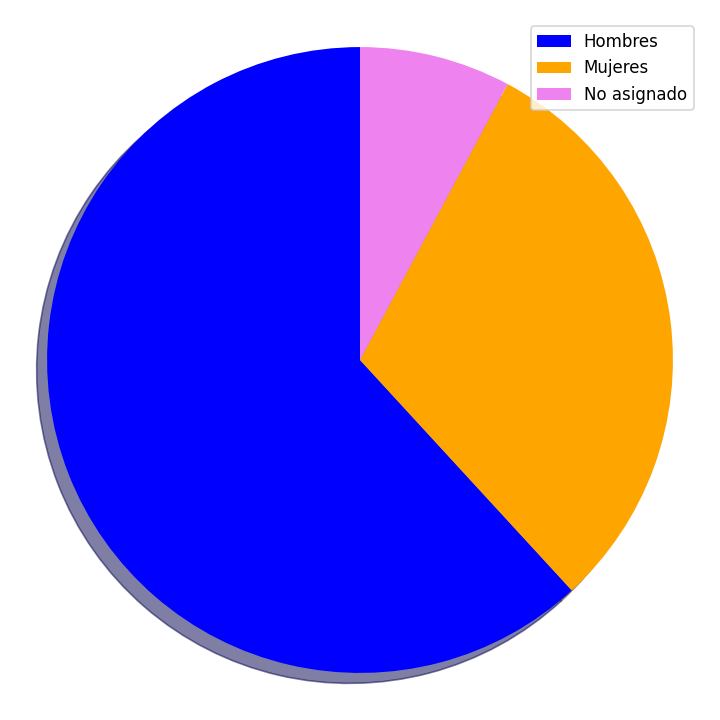
Distribución de accidentes respecto al sexo del afectado, siendo más propensos los hombres.
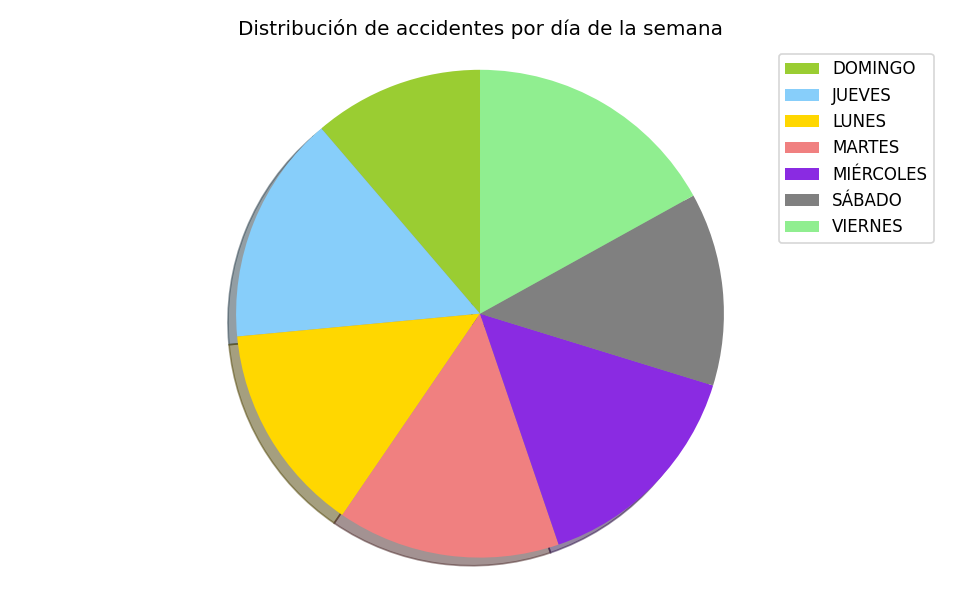
Distribución de accidentes respecto al día de la semana del incidente, siendo el día en que se producen más accidentes los miércoles.
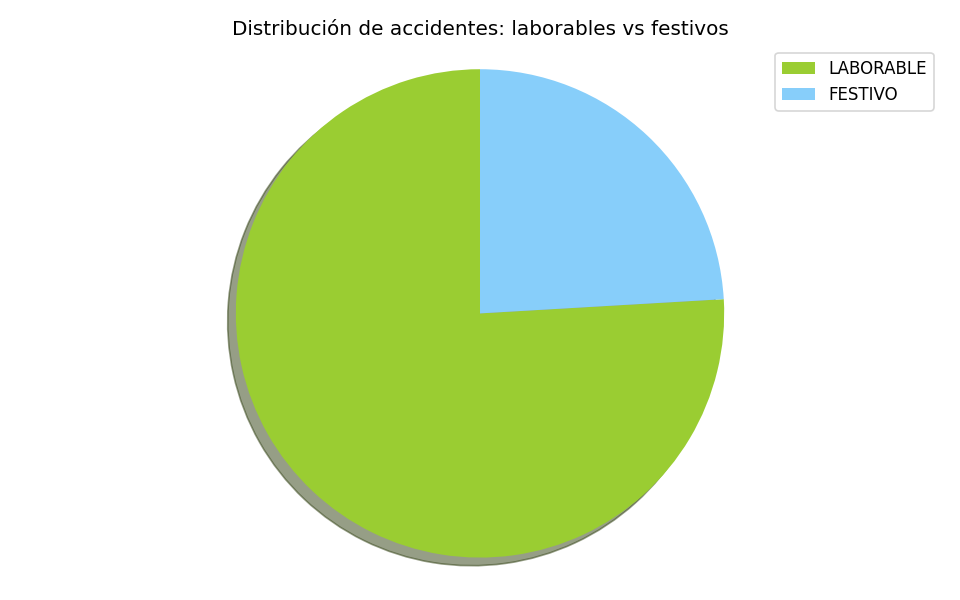
Distribución de accidentes respecto a si el día del suceso fue día laborable o no, siendo los días laborables más frecuentes los incidentes. Esto se debe a que los días hábiles son más numerosos que los NO laborables (sábado y domingo)
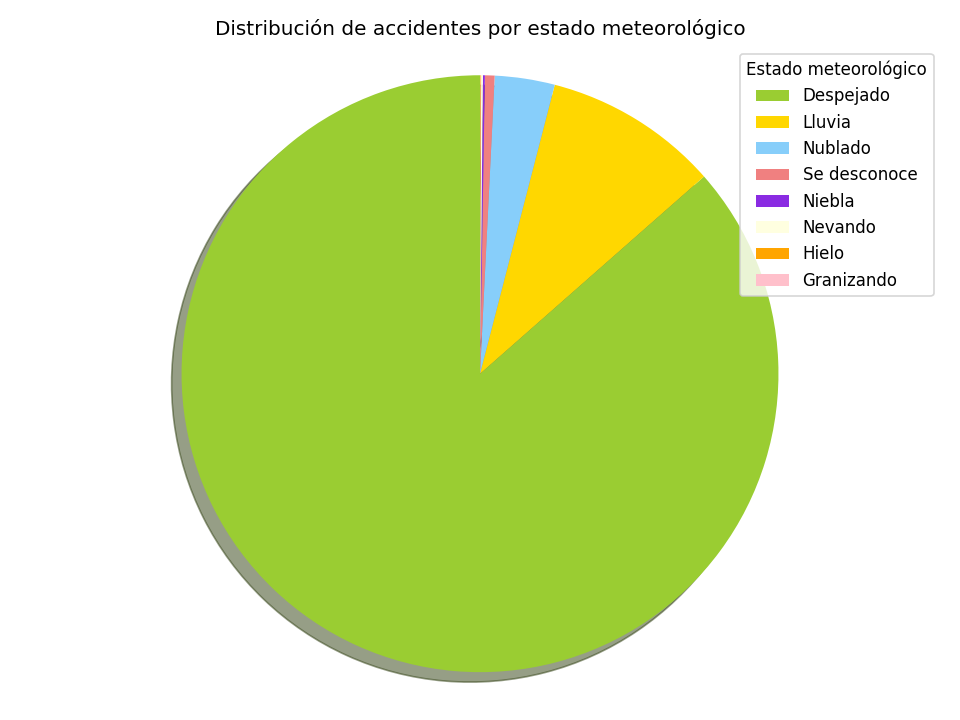
Distribución de accidentes respecto al clima. Es un hecho, que cuando hace buen tiempo se conduce de forma menos prudente, incrementando la velocidad y por tanto, aumentando el riesgo de accidente.
Distribución de accidentes respecto al rango horario:
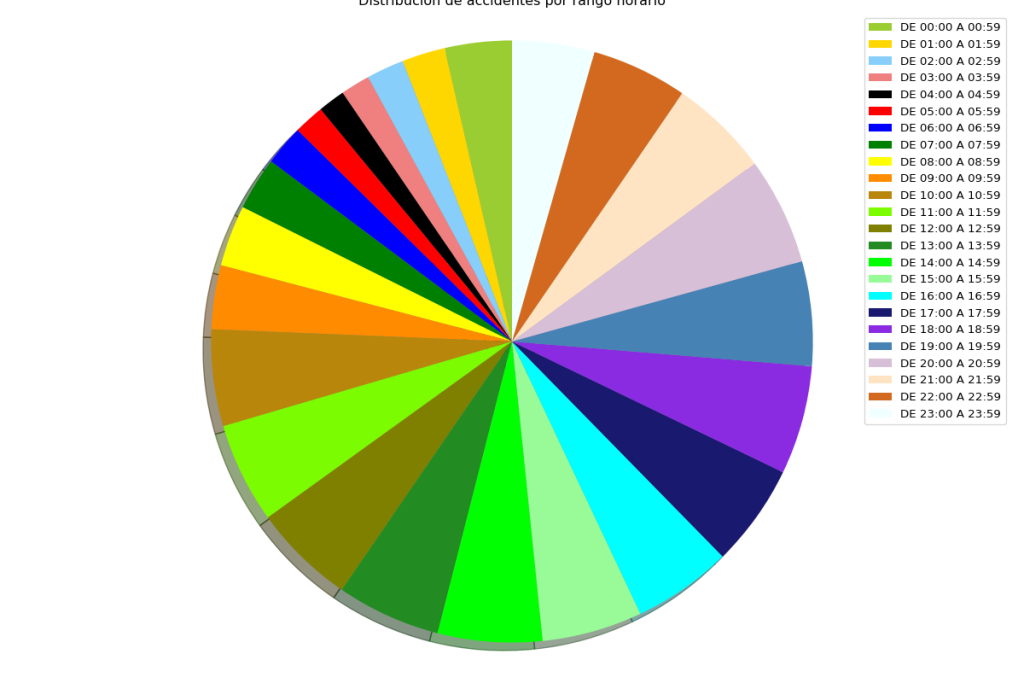
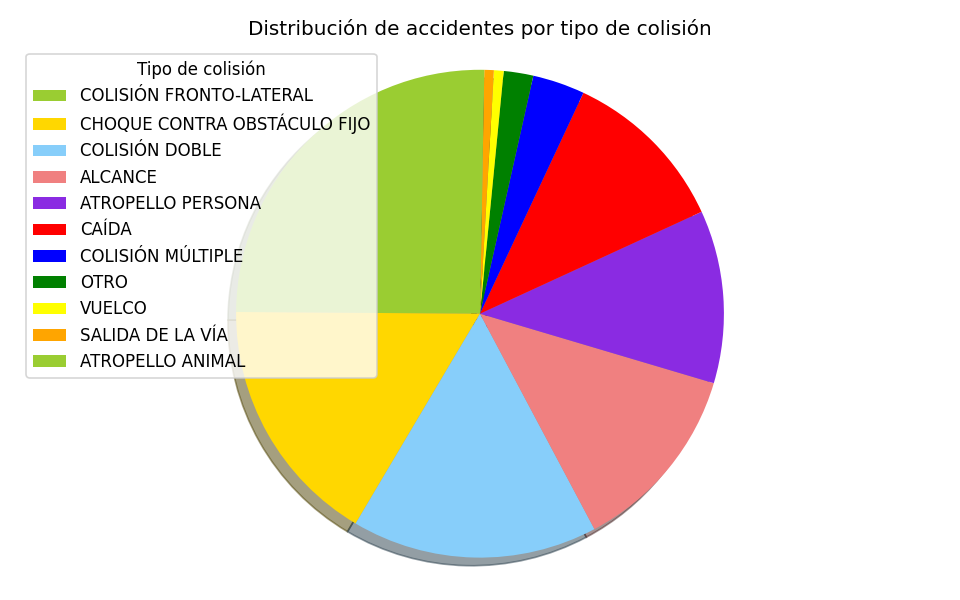
Distribución de accidentes respecto al tipo de colisión, siendo el más común la colisión fronto-lateral.
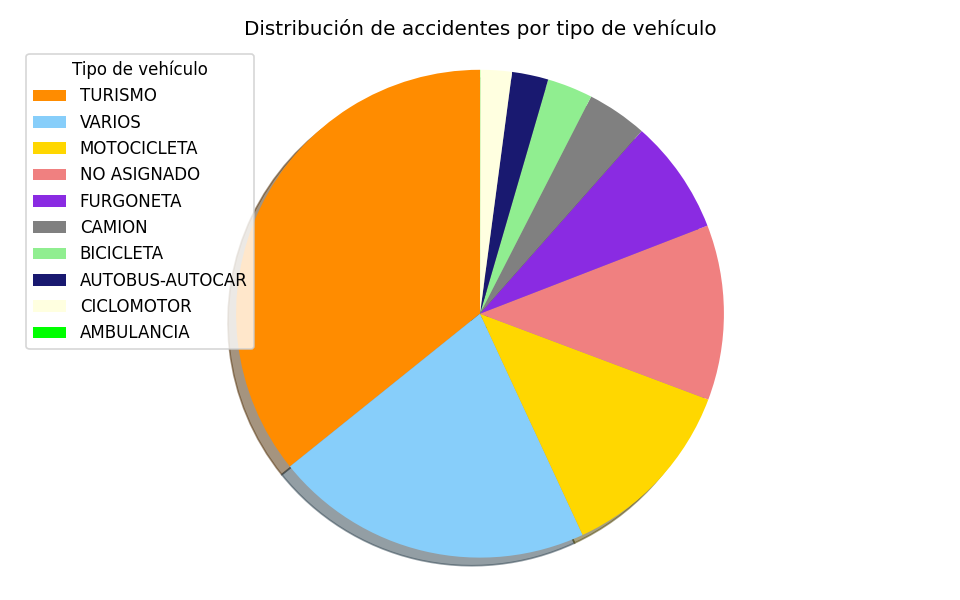
Distribución de accidentes respecto al tipo de vehículo afectado, siendo el más común el turismo, lo que es lógico al ser el vehículo más común.
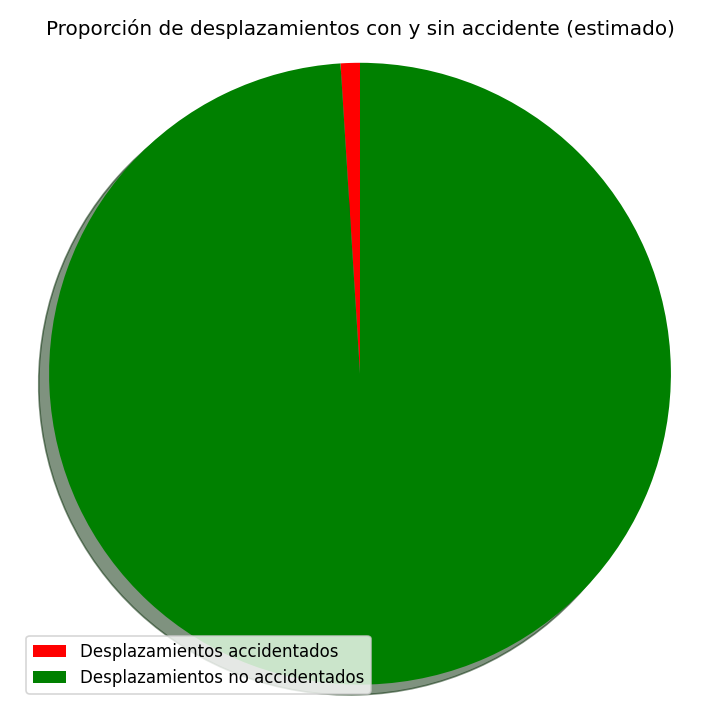
Distribución de accidentes total, lo que muestra que los accidentes representan solo una pequeña parte del total de desplazamientos realizados en Madrid.
Distribución de accidentes respecto al tipo de persona accidentada, siendo el más afectado el conductor.
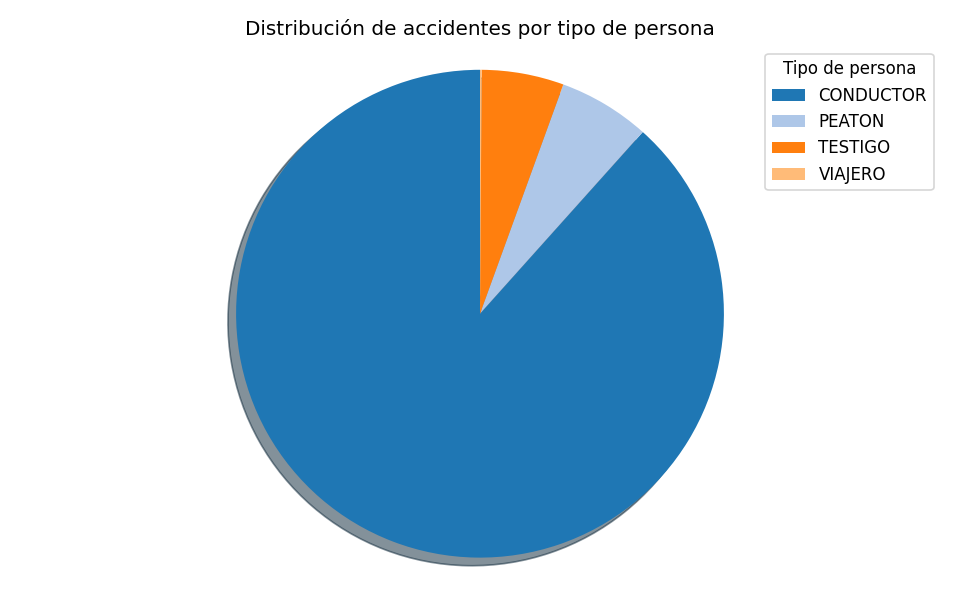
Por otro lado, la idea de la parte del uso de Machine Learning es la predicción de la probabilidad de tener un accidente dado un nuevo caso que no se encuentre en nuestro dataset. El dataset consta con muchas columnas informativas pero hemos decidido centrarnos en aquellas que creemos más relevantes (rigiéndonos por el criterio empleado por Mario de los Ríos):
- DISTRITO → Distrito de Madrid al que queremos dirigirnos.
- DÍA SEMANA→ Día en el que procederemos al viaje.
- Tipo Vehículo→ Tipo de vehículo que usaremos en el viaje.
- TIPO PERSONA → Tipo de persona implicada en el accidente. Incluye: conductor, peatón, testigo o viajero.
Para ello, preprocesamos los datos (2011–2024) unificando el formato y generamos un archivo machineLearning.csv con las columnas clave ya convertidas: distrito, día de la semana, tipo de vehículo, tipo de persona, número de casos y proporción.
Debido a que nuestro objetivo es predecir una nueva probabilidad Y para un nuevo caso X, optamos por usar regresión lineal no regularizada. Primero, implementaremos manualmente la función de coste y la del gradiente, ya que el tamaño del dataset impide usar funciones externas para obtener el theta óptimo al instante.

Este proceso es costoso en tiempo y computación, y debe repetirse si se modifica el dataset. Por ello, aunque el modelo entrena a partir del descenso de gradiente, ponemos directamente el ThetaOptimo hallado en el código para no calcularlo en cada ejecución. El valor obtenido tras aplicar el algoritmo de descenso de gradiente sobre nuestro dataset unificado es el siguiente:
[2.98199206e-04,-1.53753441e-05,-9.97759787e-06,1.03940314e-04,-1.97096881e-04]
Una vez calculado el Theta Óptimo, predecir una nueva probabilidad es casi inmediato mediante:

El resultado se interpreta como la probabilidad (en porcentaje) de accidente relativa a la media de accidentes con esas características.
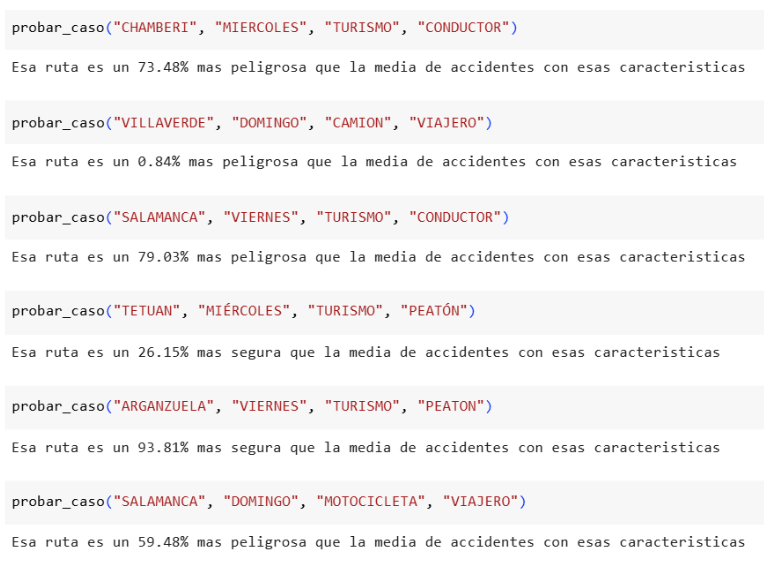
Podemos observar algunos de los ejemplos obtenidos:
DISCUSIÓN DE RESULTADOS
Consideramos de gran importancia conocer los resultados del análisis general:
- El barrio más propenso a accidentes es Salamanca, seguido por Chamartín y Puente de Vallecas.
- El día con más accidentes es el viernes, seguido del miércoles, mientras que el domingo es el más seguro.
- El vehículo más implicado es el turismo, presente en varias rutas peligrosas.
- El tipo de persona más afectada es el conductor, mientras que el viajero suele aparecer en rutas más seguras.
Los resultados obtenidos muestran que la combinación de ciertas características puede aumentar significativamente la peligrosidad de una ruta. Algunas rutas, como las de Arganzuela un viernes con un peatón o Tetuán un miércoles, resultan mucho más seguras que la media. En cambio, otras como las que incluyen Salamanca o Chamberí en días laborables, muestran una mayor probabilidad de accidente, en algunos casos superando el 70% respecto a la media. Además, el turismo y el conductor aparecen en las rutas con mayor riesgo.
Estos resultados coinciden con los patrones detectados en el análisis, lo que confirma que el modelo es útil para detectar qué combinaciones concretas aumentan o disminuyen el riesgo de accidente, mostrando que el comportamiento del tráfico varía según el distrito, el tipo de vehículo, la persona implicada y el día de la semana.
REFERENCIAS
[1] Accidentes de tráfico de la ciudad de Madrid. Datos.Madrid. Ayuntamiento de Madrid.
[2] Incidencias_de_trafico_en_Madrid. GitHub Mario de los Santos.
https://github.com/MarioDeLosSantos/Incidencias_de_trafico_en_Madrid?utm_source=chatgpt.com
AUTORES: AMPARO HINOJOSA, CARLOTA LÓPEZ y ANA LI CAMELLO