INTRODUCCIÓN
Los modelos de difusión, específicamente los modelos de texto a imagen, han permitido la transformación de ideas (imaginarias) a la realidad con un ‘prompt’ adecuado, idóneo, oportuno, conveniente… El énfasis sobre el prompt se debe a que la traducción del propio prompt al modelo y su conocimiento definen nuestros grados de libertad a la hora de querer generar esas ‘ideas’ en una imagen.
En el caso de que usemos un modelo para introducir un nuevo objeto o persona, o que deseemos modificar el estilo de la propia imagen, el modelo puede desconocerlo. Para solucionar dicho problema se ha ideado una salida que tiene un símil con el método socrático. Aprendemos una nueva representación del objeto o estilo en el ‘space embedding’ a partir de 4-5 imágenes con un modelo “text2image” congelado.
ESTADO DEL ARTE
La generación de imágenes a partir de un prompt o descripción textual ha avanzado significativamente en los últimos años. Este campo es conocido como “ text to image”, y está transformando la forma en la que se crean contenidos visuales en distintos campos que lo requieren.
La generación de contenido digital es algo muy extendido por todos los sectores. Sectores como el marketing y la publicidad pueden generar contenido para campañas publicitarias de una manera más rápida y personalizada. Además, este contenido estará basado en las preferencias del usuario. En general, la generación de imágenes aporta un enfoque distinto de creatividad. Sin embargo, hay que tener en cuenta una serie de consideraciones acerca de qué contenido se genera y cómo se genera.
DESARROLLO DE MODELO DE DIFUSIÓN
Modelos de difusión
Vamos a indagar cómo los modelos de difusión estable funcionan, los modelos de difusión son entrenados para quitar ruido gaussiano a un dato al que se le ha añadido ruido gaussiano hasta ser puro.
Encontramos dos procesos dentro de los modelos de difusión:
- ‘Forward diffusion’: difusión hacia delante, proceso fijo que va añadiendo ruido gaussiano a una imagen hasta llegar a ruido puro gaussiano q(xt | xt+1)
- ‘Backward diffusion’: red neuronal que aprende a quitar el ruido gaussiano gradualmente, empezando desde puro ruido gaussiano hasta la imagen real
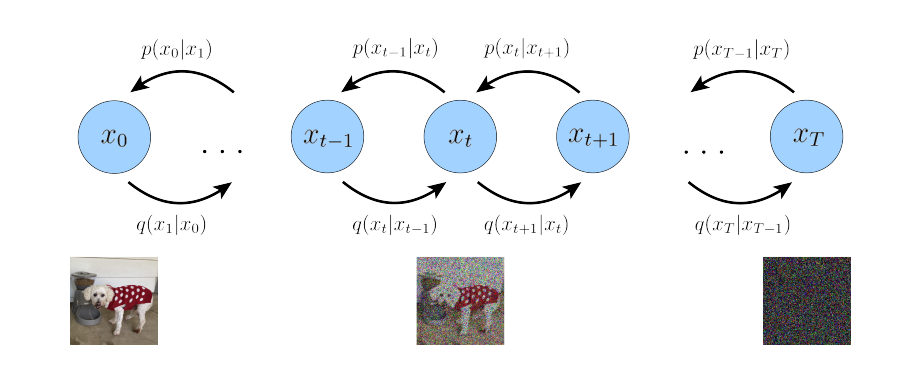

En cuanto al desarrollo matemático subyacente, vamos a comentar sus diferencias con el modelo Variacional Jerárquico Markoviano y su desarrollo hasta llegar a la expresión del ELBO que habrá que optimizar en el proceso de aprendizaje del modelo de difusión.
En un modelo de difusión variable tenemos 2 distribuciones: “p” y “q”. La distribución “q” añade ruido a una imagen durante unos timesteps determinados. La distribución “p” elimina el ruido que ha añadido la distribución “q” a la imagen original. Esta distribución tiene que intentar que tras eliminar el ruido añadido por “q” la imagen de salida sea lo más parecido a la imagen de entrada.
De esta manera podemos definir el modelo de difusión HVAE en el que definimos el espacio latente como de misma dimensión al de la entrada. Cada paso del encoder está pre-definido como una distribución gaussiana centrada en el output del paso anterior, y unos parámetros que son optimizables a medida que pasa el tiempo.
Entonces, tenemos las mismas expresiones que en el caso del Autoencoder afectadas por las restricciones definidas.
De esta manera nos quedan:
Posterior
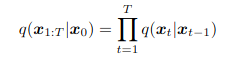
Como hemos definido, cada paso del encoder será gaussiano:
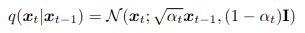
Podemos observar que q(x0) es la distribución real de los datos en la imagen real, de los datos que entran al modelo.
De la misma manera, con las distribuciones que eliminan el ruido (p):
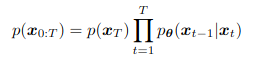
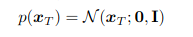
Finalmente, para optimizar el modelo tenemos que optimizar ELBO, teniendo en cuenta que lo único a aprender son las distribuciones del decoder p, y no los encoders, que hemos definido como gaussianas. Como observamos en las nuevas expresiones que hemos mostrado, esto se refleja en que ya no está parametrizado por θ.
Si derivamos la expresión del ELBO directamente de la del (MHVAE), obtenemos una expresión que usaría Montecarlo para hacer las estimaciones de dos variables a la vez. En su lugar, se utiliza una variación en la que se tiene en cuenta sólo una variable a la vez, teniendo en cuenta x0 como parámetro a la distribución.
Usando Bayes, la transición sería:
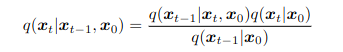
Finalmente, la expresión del ELBO quedaría así:
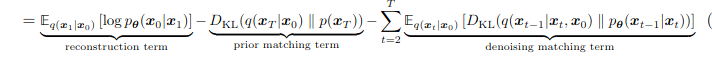
Nos quedan 3 principales componentes, y nuestro objetivo será optimizar el término de reconstrucción y el término de similitud del denoiser. El “prior matching term” quedaría como 0 según las asunciones definidas para este modelo.
Así, el proceso de aprendizaje pasará por optimizar por Monte Carlo el reconstruction term, y obtener las distribuciones de p que más se parezcan a q para minimizar la divergencia Kullback-Leiber entre las dos.
Modelo de difusión condicionado a un prompt
Una vez explicados los modelos de difusión, nos centramos en los modelos de difusión de texto a imagen. Para estos modelos, tendremos que introducir un prompt sobre el que se basará el modelo para devolver una imagen. Este prompt es un texto que tiene que ser procesado. Las partes más importantes de este procesado son:

Tras prcoesar el texto se llega al predictor de ruido que es una red U-Net. La principal diferencia con los modelos de difusión de texto a imagen con respecto al resto de los modelos de difusión es que la red U-Net está condicionada al prompt que se ha introducido. Este prompt ha sido procesado antes de introducirse a la red U-Net. Al predictor de ruido no solo llega el prompt procesado, si no que también llega una imagen codificada por un VAE. Esta imagen generada en un principio solo contiene ruido. En conclusión, el predictor de ruido (U-Net) enlaza el prompt y la imagen.
El predictor de ruido, como su nombre indica, predice el ruido de la imagen que le ha llegado. Ese ruido predicho se resta a la imagen latente que se ha introducido a la red U-Net, de tal forma que se obtiene una nueva imagen latente. Esta nueva imagen latente tendrá menos ruido que la imagen que se había introducido antes a la red, y se volverá a introducir al predictor de ruido para volver a repetir el mismo proceso. Este proceso hay que repetirlo entre 20 y 50 veces. Si repetimos el proceso menos de 20 veces, es probable que la imagen que obtengamos no tenga mucha calidad ya que no se habría quitado suficiente ruido. Por el contrario, si repetimos el proceso más de 50 veces, podemos caer en overfitting ya que estaríamos quitando ruido cuando no es necesario.
Tras haber eliminado el ruido de la imagen latente, el sistema podrá devolver la imagen asociada al prompt. Sin embargo, antes de ello habrá que hacer el paso opuesto al principio, decodificando la imagen latente con un VAE.

Textual inversion
Textual inversion crea relaciones entre imágenes y texto en un modelo preentrenado. Además, se alimenta al modelo con las distintas descripciones textuales. Dicho modelo se entrenará ajustando los embeddings del texto. En conclusión, este proceso nos permite generar imágenes precisas a partir de descripciones textuales.

RESULTADOS
Como hemos explicado en el modelo de difusión condicionado por un prompt y el entrenamiento se realiza sobre la parte de text_encoder, parte donde se codifica el espacio embedding del texto (prompt) que se emplea para condicionar el modelo de difusión empleando una atención cruzada con el de la imagen. En las demás partes del modelo se congelan los parámetros ya que como hemos explicado en el textual inversion el error asociado del gradient-tape se propaga sobre el text-embedding.

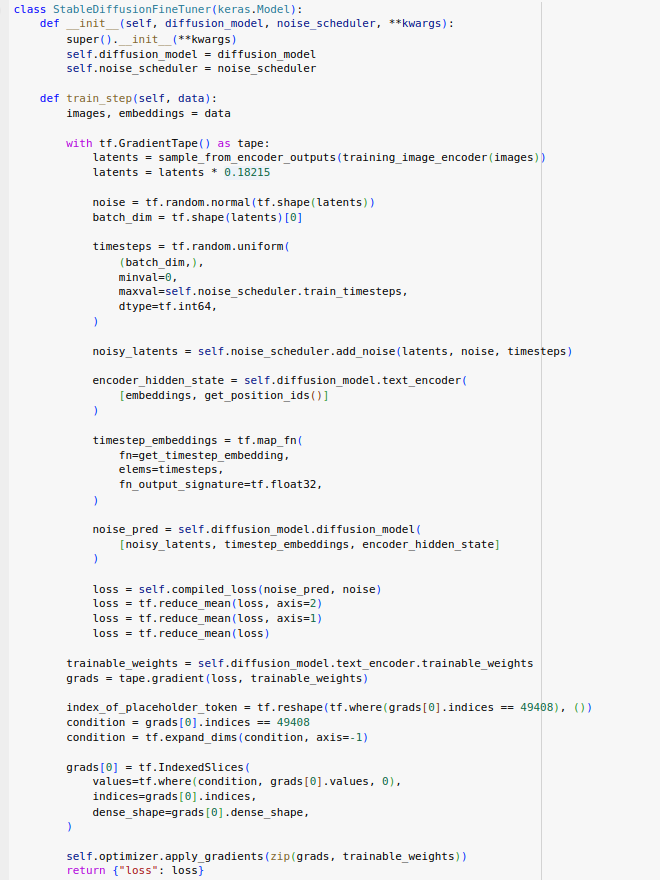
Definimos un entrenador para afinar un modelo de difusión estable, StableDiffusionFineTuner, utilizando un programador de ruido específico, NoiseScheduler. Se configura con un optimizador Adam que tiene una tasa de aprendizaje cíclica mediante una decaída coseno. Luego, se compila el modelo con una función de pérdida MSE.

Generación del modelo.

Generamos la imagen y dentro del prompt definimos dónde va a estar el token entrenado.

CONCLUSIÓN
Como podemos observar, no se han modificado los parámetros del modelo. Esto implica que el modelo conserva el conocimiento referente a las pirámides. Sin embargo, dentro del prompt podemos definir el objeto o estilo específico con el token que se ha entrenado previamente. Al final se ajusta el modelo de tal forma que pueda conocer distintos objetos o estilos sin modificar el espacio latente, es decir, el conocimiento del modelo.
Uno de los atractivos de textual inversion es que se basa en la modificación del propio input, por lo que es muy adaptable para usarse con otros modelos como generadores de audio.
REFERENCIAS
Andrew. (2024, 04, Enero). How does Stable Diffusion work?. Recuperado el 28 de Abril de 2024, https://stable-diffusion-art.com/how-stable-diffusion-work/
Calvin Luo. (2022, 26, Agosto). Understanding Diffusion Models: A Unified Perspective. Recuperado el 28 de Abril de 2024, https://arxiv.org/pdf/2208.11970
Rogge, Niels., Rasul Kashif. (2022, 7, Junio). The Annotation Diffusion Model. Recuperado el 04 de Mayo de 2024. https://huggingface.co/blog/annotated-diffusion
Gal, Rinon., Alaluf, Yuval., Aramon, Yuval.,Patashnik, Or., Bermano, Amit H., Chechik, Gal., Cohen-Or, Daniel. (2022, 02, Agosto). An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion. Recuperado el 15 de Mayo de 2024, de: https://arxiv.org/abs/2208.01618