Introducción
En el ámbito de la inteligencia artificial y el procesamiento de audio, los autoencoders variacionales (VAEs) han demostrado ser herramientas muy útiles para la representación y generación de señales de audio. Estos modelos permiten comprimir datos a través de una representación latente compacta y también facilitan la generación de nuevas señales que mantienen características similares a las del conjunto de datos original [1]. Realtime Audio Variational AutoEncoder (RAVE) es una arquitectura específica de VAE optimizada para el procesamiento de audio en tiempo real, abordando los desafíos de la naturaleza temporal y la alta dimensionalidad de las señales de audio. [2]
El proyecto propuesto busca explorar cómo convergen y divergen las representaciones latentes obtenidas de dos modelos RAVE distintos cuando se les da la misma entrada de audio. La idea principal es aplicar una función matemática a una de las representaciones latentes para minimizar su distancia euclidiana respecto a la otra. La distribución del error calculado a partir de esta distancia se utiliza para ajustar la representación latente, que luego se introduce al decodificador del primer modelo RAVE. Esto permitirá obtener una salida que se asemeje mucho a la que se lograría utilizando la representación latente original del mismo modelo [3] .
Este enfoque no solo proporciona una forma novedosa de analizar y mejorar la interoperabilidad entre diferentes modelos RAVE, sino que también puede tener aplicaciones prácticas en la mejora de la calidad y coherencia del procesamiento de audio en tiempo real.
Estado del arte
En los últimos años, la inteligencia artificial y el procesamiento de señales han experimentado un avance significativo, particularmente en el ámbito de los autoencoders variacionales. Los VAEs han demostrado ser herramientas efectivas para la representación y generación de datos complejos, incluidos los datos de audio. A diferencia de los autoencoders tradicionales, los VAEs incorporan un enfoque probabilístico que permite generar nuevas muestras que son coherentes con el conjunto de datos de entrenamiento, lo cual es crucial para aplicaciones como la síntesis de audio y la compresión de señales.
VAEs en el Procesamiento de Audio
Los VAEs han sido ampliamente utilizados en diversas aplicaciones de audio debido a su capacidad para aprender representaciones latentes compactas y generar señales realistas.Algunos ejemplos concretos de estas aplicaciones son:
Kingma y Welling (2013) introdujeron los VAEs, estableciendo las bases teóricas que han sido aplicadas y extendidas en el procesamiento de audio [4]. Modelos como WaveNet [5] y SampleRNN [6] han utilizado conceptos de VAEs y redes neuronales recurrentes para generar audio de alta calidad, demostrando la eficacia de estas técnicas en la captura de las características temporales y espectrales del audio.
Realtime Audio Variational AutoEncoder (RAVE)
La arquitectura RAVE representa una evolución significativa en el uso de VAEs para el procesamiento de audio en tiempo real. RAVE está diseñada para abordar los desafíos específicos del procesamiento de audio, como la alta dimensionalidad y la naturaleza secuencial de las señales de audio. A través de una arquitectura optimizada y técnicas avanzadas de entrenamiento, RAVE permite la compresión eficiente y la generación de audio en tiempo real, manteniendo la coherencia y la calidad de las señales.
Interoperabilidad y Representaciones Latentes
Un área emergente de investigación en el campo de los VAEs y RAVE es la interoperabilidad entre diferentes modelos y la manipulación de las representaciones latentes. La capacidad de ajustar y adaptar estas representaciones puede mejorar altamente la calidad y la consistencia de las señales generadas.
Aplicaciones Prácticas
Las aplicaciones prácticas de estos avances son numerosas y variadas. En el ámbito de la producción musical, los VAEs y RAVE pueden facilitar la generación de sonidos y efectos de alta calidad, permitiendo a los artistas y productores explorar nuevas posibilidades creativas. Además, en aplicaciones de transmisión y compresión de audio, estas técnicas pueden mejorar la eficiencia y la calidad del audio transmitido, ofreciendo una mejor experiencia al usuario final.
Desarrollo
Audio de Entrada
El audio de entrada se suministra a los modelos seleccionados en forma de un archivo .wav. Utilizando la librería librosa, se extrae la tasa de muestreo (sampling rate, sr) del archivo para proceder con el muestreo y obtener la señal de audio x.
Modelos
Seleccionamos dos modelos de RAVE: Percussion y VCTK. Cada uno de estos modelos consta de un codificador (encoder) y un decodificador (decoder). Es importante destacar que los tamaños de las representaciones latentes generadas por los codificadores de ambos modelos difieren ([1, 8, 108] para Percussion vs. [1, 4, 108] para VCTK). Para unificar estas dimensiones, añadimos ceros a la representación de menor tamaño, ajustándola al tamaño mayor, consiguiendo mismo TorchSize en ambos, lo que permite realizar operaciones posteriores sin incompatibilidades dimensionales.

Esquema de trabajo
El audio muestreado x se introduce en los codificadores de ambos modelos (Percussion y VCTK), obteniendo así dos salidas (después de sendos Encoders) correspondientes a las representaciones latentes z1 y z2, que tienen distribuciones diferentes.
Aplicación del Transfer Learning Transductivo
En cuanto a la aplicación del aprendizaje por transferencia transductivo, queremos transformar la representación latente z2 obtenida del segundo encoder en una nueva representación z’ que se alinee con z1 obtenida del primer encoder. Esta transformación se diseña para que, al pasar z’ por el decodificador del primer modelo (Percussion), se obtenga una salida x2 similar a la que se generaría si se introdujera z1 en dicho decodificador. De tal manera que x1 x2.
Para lograr esto, seguimos los siguientes pasos:
Minimización de la Distancia Euclídea: Definimos una función de transformación T(z2) que convierte z2 en z′. Esta función T se entrena para minimizar la distancia euclídea entre z1 y z’:
z’=T(z2)
La función de pérdida que queremos minimizar es la distancia euclídea entre z1 y z’:
L=∥z1−z’∥, es decir el error
Donde ∥⋅∥ denota la norma euclídea.

Transformación de z2: Para encontrar T(z2), primero calculamos la distancia euclídea entre z1 y z2:
d(z1,z2)=∥z1−z2∥
Esta distancia nos da una medida del error producido por el encoder 2 cuando intentamos decodificar con el decodificador del modelo
Optimización: La función T se optimiza iterativamente usando un conjunto de datos de entrenamiento. Para cada par de representaciones z1 y z2 correspondientes a un mismo audio pero generadas por encoders diferentes, aplicamos T a z2 y ajustamos T para minimizar L.
Entrenamiento con Múltiples Audios: Este proceso se repite para un conjunto grande de audios. Por cada audio, calculamos el error entre z1 y T(z2), y ajustamos la función T. Al hacerlo para muchos audios, obtenemos una distribución del error y entrenamos T para minimizar este error en promedio:
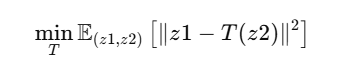
Donde E denota la esperanza matemática, es decir, el promedio sobre todos los pares (z1,z2)
Salida Decodificada: Una vez entrenada T, podemos transformar cualquier z2 en z’ y pasarlo por el decodificador del modelo 1 para obtener x2, asegurándonos de que x2sea similar a x1:
Esto garantiza que las características de z2 se alineen con las de z1, permitiendo una salida decodificada de alta calidad.
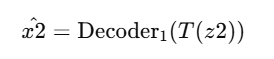
Materiales utilizados
A continuación vamos a incluir el código que hemos utilizado. Lo hemos realizado para dos muestras:
Nos descargamos un fichero .wav el cual será el input común para ambos encoders

Seguidamente nos descargamos dos modelos de RAVE para realizar el proyecto

Si representamos la representación latente de la salida de cada uno de los encoders podemos observar lo mencionado

En este enlace se puede encontrar el fichero con el código: https://drive.google.com/file/d/1OeyP8BWZJWWPp96p–dbNYyoKd52ZJQy/view?usp=share_link
Discusión de resultados
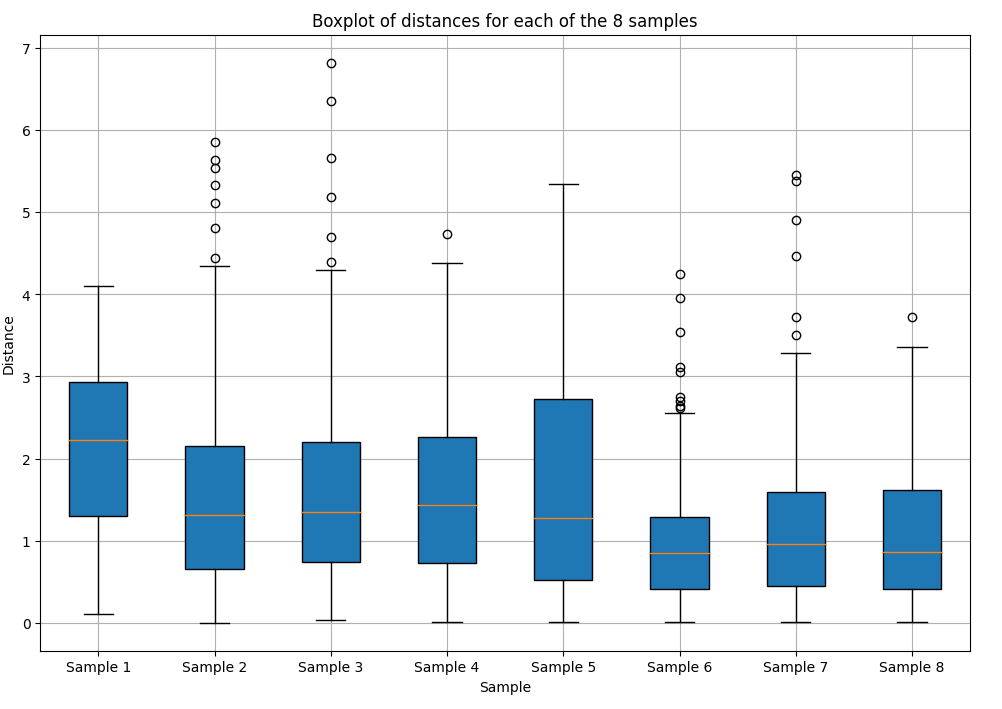
Analizando las distancias euclídeas, es decir errores, para dos audios diferentes tomados como entrada, podemos ver a través de un gráfico de cajas que estas distancias son pequeñas por lo tanto las representaciones latentes obtenidas eran bastante similares.

Referencias
[1] Kingma, D. P., & Welling, M. (2019). An Introduction to Variational Autoencoders. arXiv. https://arxiv.org/abs/1906.02691
[2] Caillon, A., & Esling, P. (2021). RAVE: A variational autoencoder for fast and high-quality neural audio synthesis. arXiv. https://arxiv.org/abs/2111.05011
[3] José Luis Blanco-Murillo (2022). Advanced Data and Signals Processing
[4] Kingma, D. P., & Welling, M. (2013). Auto-Encoding Variational Bayes. arXiv.
https://arxiv.org/abs/1312.6114
[5] Van den Oord, A., Dieleman, S., Zen, H., Simonyan, K., Vinyals, O., Graves, A., Kalchbrenner, N., Senior, A., & Kavukcuoglu, K. (2016). WaveNet: A Generative Model for Raw Audio. arXiv. https://arxiv.org/abs/1609.03499
[6] Mehri, S., Kumar, K., Gulrajani, I., Kumar, R., Jain, S., Sotelo, J., Courville, A., & Bengio, Y. (2017). SampleRNN: An Unconditional End-to-End Neural Audio Generation Model. arXiv. https://arxiv.org/abs/1612.07837