Autora: Paula Miles Uribe
Tutor: Nicolás Sáenz Lechón
Fecha de lectura: 10 de julio de 2020
Este proyecto surge por el deseo de Nicolás Sáenz de obtener una copia digital del diario mecanografiado de su abuelo Clemente Sáenz García. Tras varios intentos de digitalización mediante diferentes programas de reconocimiento óptico de caracteres (OCR) comerciales, se observó que los resultados no eran buenos.
El objetivo principal de este proyecto es el desarrollo de una herramienta de OCR a medida, realizando un análisis predictivo de caracteres mediante el modelado de una red neuronal artificial convolucional. A través del entrenamiento y aprendizaje de la red neuronal, se permitirá un mejor reconocimiento del texto mecanografiado, obteniendo una representación del texto en un formato editable en el que las correcciones sean las menores posibles.
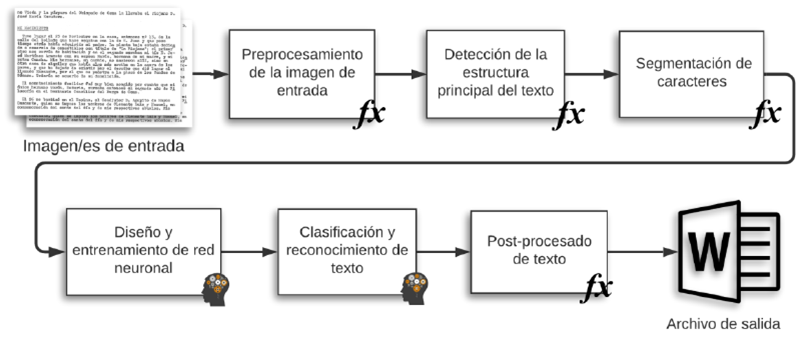
Se dispone, como material de partida, de fotografías tomadas con una cámara digital de cada página del diario, el cual se divide en 15 tomos, sumando un total de 5420 cuartillas mecanografiadas. Con el fin de facilitar su tratamiento en el proceso que conlleva el desarrollo de este proyecto, las imágenes utilizadas pasan por un procesado previo ya desarrollado, dejándolas en unas condiciones similares a las que tendrían si hubieran sido escaneadas.
La aplicación consta de varios procesos: segmentación de imágenes, etiquetado de caracteres, entrenamiento de la red neuronal, reconocimiento de caracteres y post-procesado del texto predicho obtenido.
La herramienta utilizada para implementarla ha sido MATLAB, la cual dispone de múltiples paquetes que proporcionan funciones específicas para cada uno de los procesos utilizados. En este caso se han utilizado Image Processing Toolbox para el tratamiento de imágenes, Deep Learning Toolbox para el entrenamiento y predicción de la red neuronal, y Report Generator Toolbox para la obtención del texto final en formato Word.
Se ha utilizado una metodología de trabajo iterativo y creciente. En un primer momento se utilizó un sistema de segmentación ya desarrollado, basado en la utilización del método de acumulación de pixeles. Como no se consiguieron resultados satisfactorios al observarse solapamiento de caracteres, se realizan mejoras al respecto obteniendo así, caracteres únicos como salida.
Tras el desarrollo de esta función y su validación con el conjunto de imágenes seleccionado, con los resultados obtenidos se crea un dataset de imágenes de caracteres que a su vez requiere de un etiquetado manual de cada una de ellas. Este resultado se utiliza posteriormente para el entrenamiento y aprendizaje de la red neuronal convolucional. La red neuronal convolucional imita el proceso de aprendizaje biológico que sucede en nuestro cerebro, en el que se interconectan múltiples neuronas y responden a estímulos que se les presenta en un área restringida del campo visual. Como resultado, aprende a clasificar los caracteres haciendo un análisis de sus características.
Finalmente, los caracteres predichos se agrupan en palabras coherentes, formando así, un texto legible. El resultado final se presenta en formato Word con el contenido del texto de la imagen de entrada, marcando en rojo las palabras que no sean correctas debido a errores de predicción para facilitar su posterior corrección manual.